标签:使用 两台 sele 配置 slist 影响 incr sql语句 参数配置
〇、经验总结:接着上一篇Grpc性能调优的文章继续写,我们这次压测的是一个查询用户群组列表信息的接口,该接口里需要查询某个用户的所有群组信息,包括每个群组的名称、成员数量等。
经过之前对业务机器的JVM参数等进行优化后,现在已经不存在业务机器的频繁GC、CPU占用率过高、TPS上不去等问题了。但是我们遇到了两个新问题:在业务接口并发50、TPS600左右时,压测接口出现了超时错误,而且数据库服务器CPU占用率超过了93%!
数据准备:
t_info_group群组表: 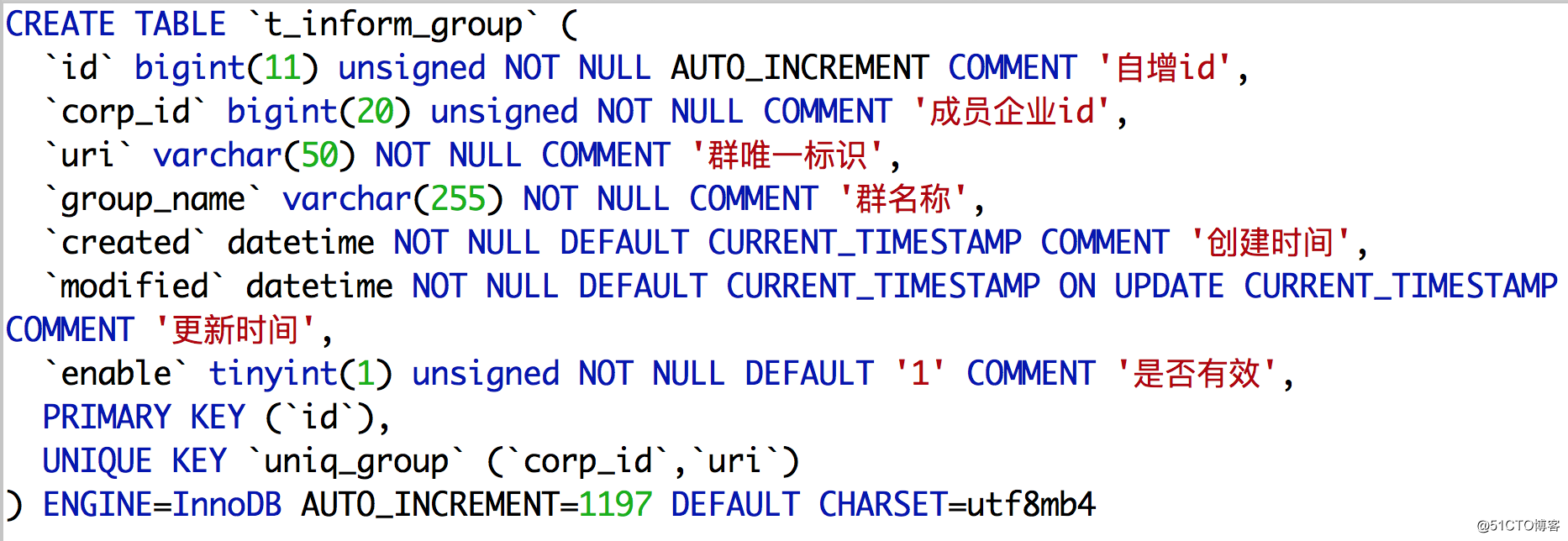
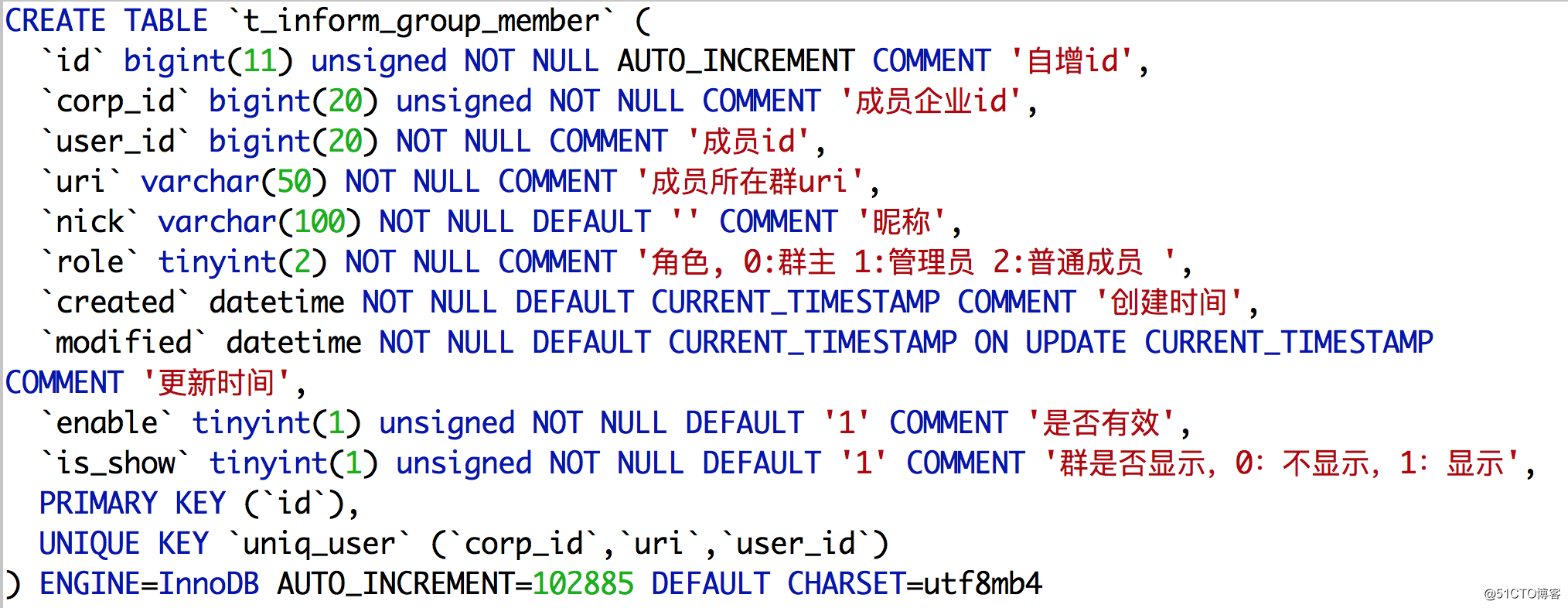
数据约定:测试数据中,每个群组里面有3000个成员;每个成员有20个群组。
我们首先进行一次摸底测试,使用两台压测机器共同发起300个并发,持续压测2分钟。(如果只用一台压测机发起300个并发,会由于机器端口受限,TPS超过5W后不能发起新请求,压测机将报错)
(1)数据库连接池配置
c3p0.initialPoolSize=15
c3p0.minPoolSize=15
c3p0.acquireIncrement=10
c3p0.maxPoolSize=32
(2)数据库慢查日志、数据库服务器监控指标
top命令显示CPU使用率超过了91%,而且慢查日志一直在刷!
通过分析慢查日志里面的SQL语句,以及对应的数据库表,发现查询语句中有“where a=.. and b=.. and c=..”,但是有一个联合索引的字段是“a, c"。根据联合索引的匹配规则,这条sql用不了索引,导致慢查。经过将索引更换成"a, b, c",单条sql查询效率提高一倍。
使用两台压测机器共同发起50个并发,持续压测2分钟。
(1)其他配置均不做改变。
(2)数据库慢查日志、数据库服务器监控指标
经过上述调整,慢查日志没有了,但是CPU使用率依然还是超过了90%。这是一个不能容忍的数据,如果并发继续提高,数据库服务器很快将被撑爆。
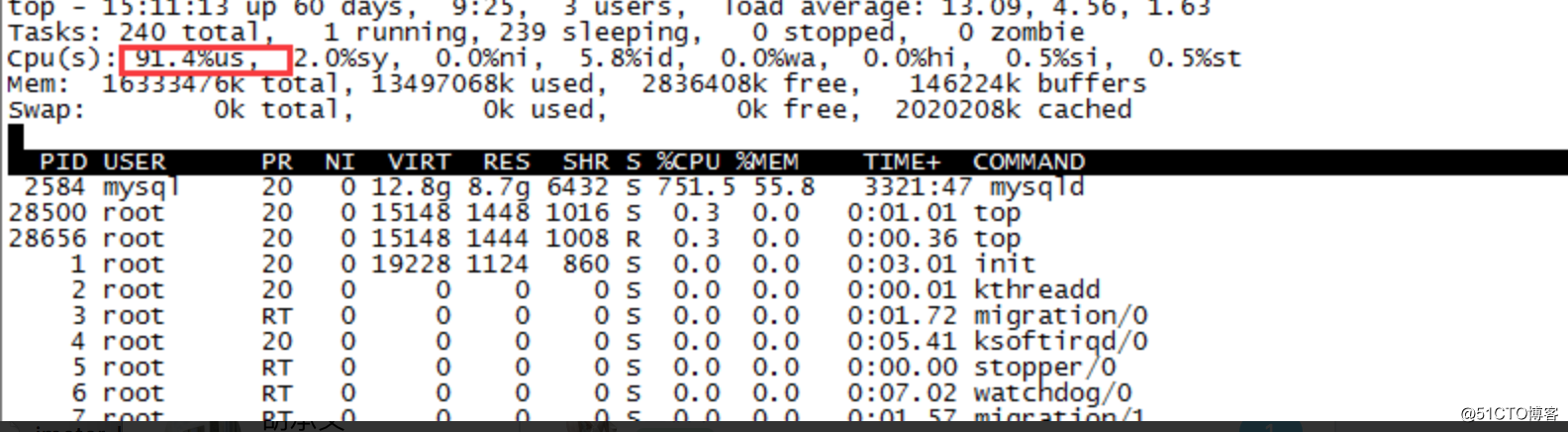
由于其他涉及到sql查询的接口在压测时都没有出现过CPU占用率这么高的情况,所以我们排除了数据库服务器安装配置的问题。
我们开始思考出现问题的可能原因:
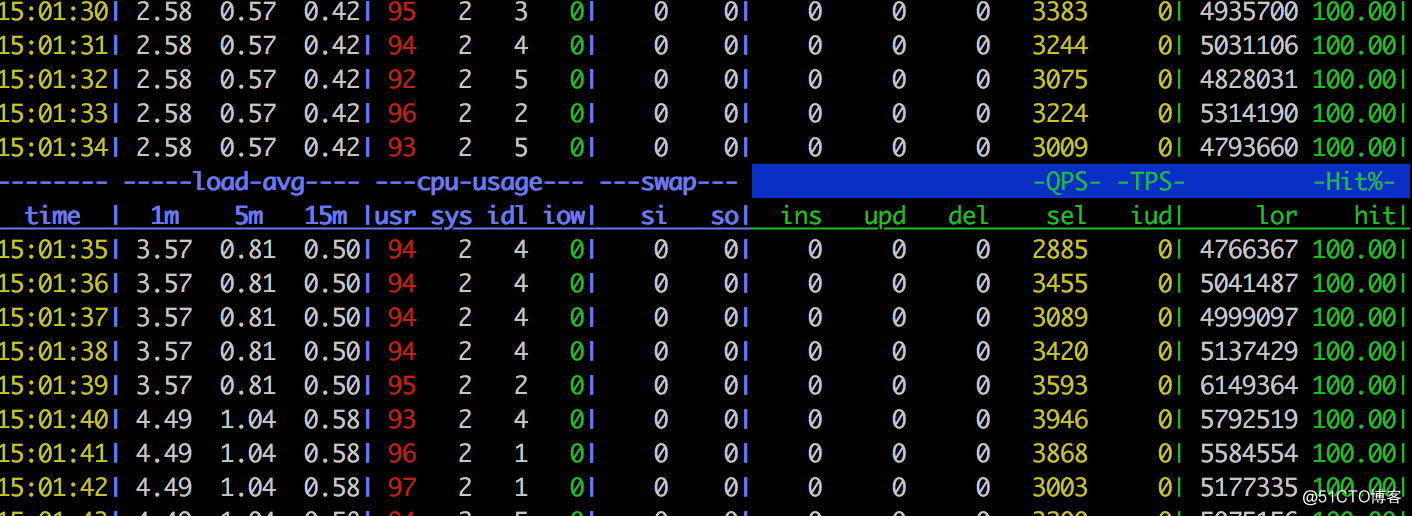
对照接口的指标数据: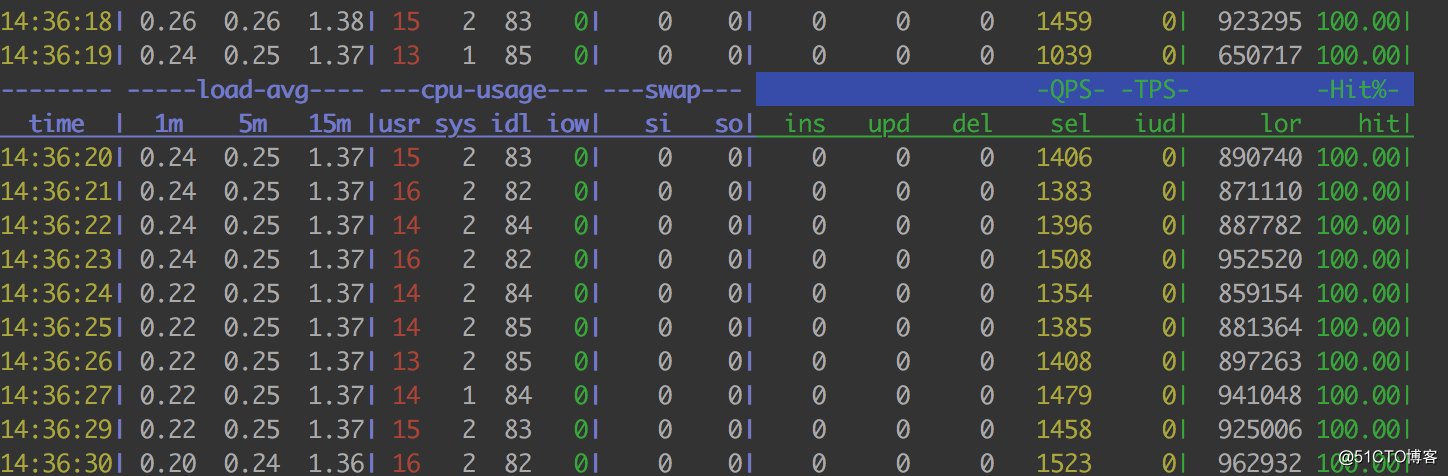
从上述两个对比图可以看到,当前压测接口的数据库QPS高达3000。对比数据汇总一下,可以看出一些问题:
当前接口:
并发:60,TPS:600,数据库CPU:92%,数据库QPS:3000
对照接口:
并发60,TPS:1000,数据库CPU:20%,数据库QPS:1400
当前压测接口处理更耗时,可能原因是一次接口业务里涉及到了多次数据库操作。
那么接下来就是排查业务代码里的数据库操作了。进行code review!
核心业务伪代码:
//查询用户的群组列表
List<Dto> groupList = groupDao.selectGroups(userId);
for(Dto dto:groupList){
//查询每个群组的用户数,会循环20次!
int userNumber = groupDao.getGroupNumber(dto.getAsIong(groupId));
}
这段代码怎么这么别扭?第一个查询已经去查询群组信息了,还要用for循环去遍历20次统计每个群组用户数??
这样操作的话,一次接口请求将操作很多次的数据库查询,并带来更多网络、IO操作。那么CPU占用率过高的问题很可能是这个情况导致的。
我们的优化措施是优化groupDao.selectGroups(userId)对应的查询语句,使用子查询返回用户的群组列表和每个群组的用户数,去掉for循环。
使用两台压测机器共同发起50个并发,持续压测2分钟。
(1)其他配置均不做改变。
(2)数据库慢查日志、数据库服务器监控指标
数据库慢查日志没有提示慢查SQL语句,数据库服务器CPU占用率稳定在80%以下,数据库QPS提高到了近7000!这个优化效果可以说是非常的明显了。
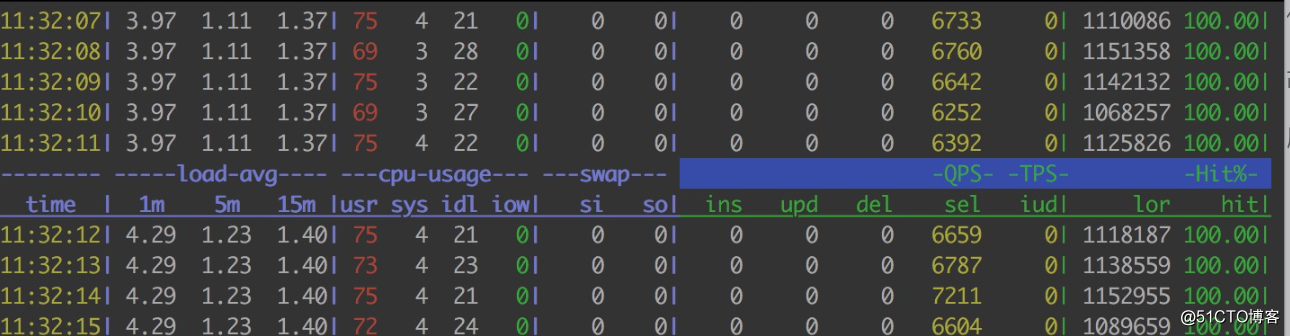
也许有人会问:代码优化后数据库的QPS比之前更高了,那CPU使用应该更多啊,但是为什么数据库的CPU占用率反而降下来了呢?这是为什么呢?这个问题,其实我也没有想明白,有知道原因的朋友欢迎留言讨论。
接口优化前:
并发:60,TPS:600,数据库CPU:92%,数据库QPS:3000


标签:使用 两台 sele 配置 slist 影响 incr sql语句 参数配置
原文地址:http://blog.51cto.com/andrewli/2177363