标签:出现 参数文件 并且 例子 run 需要 启动 调校 roc
1、批处理:顺序处理请求(切换次数少,吞吐量高)
2、分时处理:时间片,把请求分为一个一个的时间片,一片一片的分给CPU处理,我们现在使用的x86就是这种架构(如同“独占”,吞吐量小)
3、实时处理比如:
批处理--------以前的大型机上所采用的系统,需要把一批程序事先写好,然后计算得出结果
分时处理------现在流行的PC机和服务器都是采用这种运行模式,就是把CPU的运行分成若干时间片分别处理不同的运算请求
实时处理------一般用于单片机上,比如电梯的上下控制,对于按键等动作要求进行实时处理中断
中断是指在计算机执行期间,系统内发生任何非寻常的或非预期的急需处理事件,使得CPU暂时中断当前正在执行的程序而转去执行相应的时间处理程序。待处理完毕后又返回原来被中断处继续执行或调度新的进程执行的过程。中断是一种发生了一个外部的事件时调用相应的处理程序的过程。
硬中断
外围硬件发给CPU或者内存的异步信号就是硬中断信号。简言之:外设对CPU的中断, 因此具有随机性和突发性, , 硬件中断处理程序要确保它能快速地完成它的任务,这样程序执行时才不会等侍较长时间, 外部设备(如输入输出设备)请求引起的中断,也称为外部中断或I/O中断。例如(鼠标点击程序"取消")
软中断
由软件本身发给操作系统内核的中断信号,称之为软中断。通常是由硬中断处理程序或进程调度程序对操作系统内核的中断,也就是我们常说的系统调用(System Call)了。软中断发生的时间是由程序控制的
为了说明这个问题,举一例子。假设你有一个朋友来拜访你,但是由于不知道何时到达,你只能在大门等待,于是什么事情也干不了。如果在门口装一个门铃,你就不必在门口等待而去干其它的工作,朋友来了按门铃通知你,你这时才中断你的工作去开门,这样就避免等待和浪费时间。计算机也是一样,例如打印输出,CPU传送数据的速度高,而打印机打印的速度低,如果不采用中断技术,CPU将经常处于等待状态,效率极低。而采用了中断方式,CPU可以进行其它的工作,只在打印机缓冲区中的当前内容打印完毕发出中断请求之后,才予以响应,暂时中断当前工作转去执行向缓冲区传送数据,传送完成后又返回执行原来的程序。这样就大大地提高了计算机系统的效率。
grep HZ /boot/config-3.10.0-327.el7.x86_64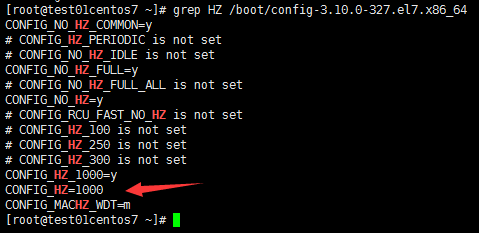
CONFIG_HZ=1000 #1秒钟有1000次中断,该参数是编译内核的时候编译进去的,改不了的,除非重新编译一下内核注意:此文件config-3.10.0-327.el7.x86_64是编译内核的参数文件
可以调整nice值,让进程使用更多的CPU
nice值的范围:-20~19 #数值越小优先级越高
nice作用:以什么优先级运行程序。默认优先级是0
nice语法:nice -n 优先级数值 命令 例如:
nice -n -1 vim a.txt # vim进程以-1级别运行查看
ps -ef | grep vim
top -p 2814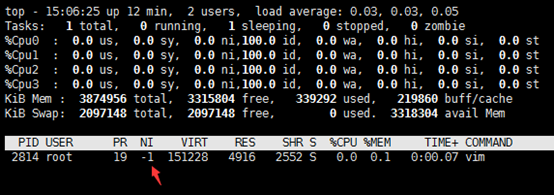
renice #修改正在运行的进程的优先级
renice语法:
renice –n -6 PID例如:

renice -n -6 2520
top -p 2520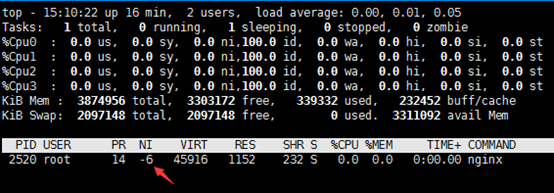
CPU亲合力就是指在Linux系统中能够将一个或多个进程绑定到一个或多个处理器上运行.
一个进程的CPU亲合力掩码决定了该进程将在哪个或哪几个CPU上运行.在一个多处理器系统中,设置CPU亲合力的掩码可能会获得更好的性能.
我们来分析一下:
1、linux的SMP负载均衡是基于进程数的,每个cpu都有一个可执行进程队列,只有当其中一个cpu的可执行队列里进程数比其他cpu队列进程数多25%时,才会将进程移动到另外空闲cpu上,也就是说cpu0上的进程数应该是比其他cpu上多,但是会在25%以内
2、我们的业务中耗费cpu的分四种类型,(1)网卡中断(2)1个处理网络收发包进程(3)耗费cpu的n个worker进程(4)其他不太耗费cpu的进程基于1中的负载均衡是针对进程数,那么(1)(2)大部分时间会出现在cpu0上,(3)的n个进程会随着调度,平均到其他多个cpu上,(4)里的进程也是随着调度分配到各个cpu上;
当发生网卡中断的时候,cpu被打断了,处理网卡中断,那么分配到cpu0上的worker进程肯定是运行不了的
其他cpu上不是太耗费cpu的进程获得cpu时,就算它的时间片很短,它也是要执行的,那么这个时候,你的worker进程还是被影响到了;按照调度逻辑,一种非常恶劣的情况是:(1)(2)(3)的进程全部分配到cpu0上,其他不太耗费cpu的进程数很多,全部分配到cpu1,cpu2,cpu3上。。那么网卡中断发生的时候,你的业务进程就得不到cpu了
如果从业务的角度来说,worker进程运行越多,肯定业务处理越快,人为的将它捆绑到其他负载低的cpu上,肯定能提高worker进程使用cpu的时间
举个例子说一下,redis是单进程模型,为了充分利用多核服务器的性能,可以指定不同的redis实例运行在不同的CPU上,这样也可以减少进程上下文切换。
安装:
[root@test01centos7 ~]# rpm -qf `which taskset`
util-linux-2.23.2-26.el7.x86_64taskset作用:在多核情况下,可以指定一个进程在哪颗CPU上执行程序,减少进程在不同CPU之间切换的开销
ps -aux | grep mysql
taskset -p 4223
f #说明MySQL在4颗CPU上随机进行切换
taskset -pc 2 4223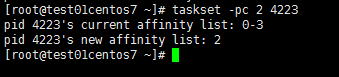
注意:2表示该进程只会运行在第三个CPU上(从0开始计数)
taskset -p 4223
这里看到了4,有朋友就要说了,你这不对呀,刚刚我明明指定的-pc 2,那从0开始计算,应该是第三颗CPU上运行才对,怎么会是4呢,说明一下:
8核CPU ID: 7 6 5 4 3 2 1 0
对应的十进制数为:128 64 32 16 8 4 2 1
十六进制: A=10 B=11 C=12 D=13 E=14 F=15从上边可以看出什么了么,我们taskset -p查看时,下边显示的4,是十进制数的CPU,4对应的CPU ID为2,从0开始算,那就是第三颗CPU。那之前我们看到的f呢,为什么代表的是4颗CPU,f=15=1+2+4+8,这样可以明白f为什么代表的是4颗CPU了么
taskset -c 3 /a01/apps/nginx/sbin/nginx -c /etc/nginx/nginx.confps -aux | grep nginx
taskset -p 4468
通常,一个被充分利用的CPU,利用率之间的比例应该是:
1、CPU利用率,如果 CPU 有 100% 利用率,那么应该到达这样一个平衡:65%-70% User Time,30%-35% System Time,0%-5% Idle Time
2、上下文切换,上下文切换应该和 CPU 利用率联系起来看,如果能保持上面的 CPU 利用率平衡,大量的上下文切换是可以接受的
3、可运行队列,每个可运行队列不应该有超过1-3个线程(每处理器),比如:双处理器系统的可运行队列里不应该超过6个线程。vmstat 是个查看系统整体性能的小工具,小巧、即使在很 heavy 的情况下也运行良好,并且可以用时间间隔采集得到连续的性能数据。
vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 140 2915476 341288 3951700 0 0 0 0 1057 523 19 81 0 0 0
4 0 140 2915724 341296 3951700 0 0 0 0 1048 546 19 81 0 0 0
4 0 140 2915848 341296 3951700 0 0 0 0 1044 514 18 82 0 0 0
4 0 140 2915848 341296 3951700 0 0 0 24 1044 564 20 80 0 0 0
4 0 140 2915848 341296 3951700 0 0 0 0 1060 546 18 82 0 0 0从上面的数据可以看出几点:
1. interrupts(in)非常高,context switch(cs)比较低,说明这个 CPU 一直在不停的请求资源;
2. user time(us)一直保持在 80% 以上,而且上下文切换较低(cs),说明某个进程可能一直霸占着 CPU;
3. run queue(r)刚好在4个。procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
14 0 140 2904316 341912 3952308 0 0 0 460 1106 9593 36 64 1 0 0
17 0 140 2903492 341912 3951780 0 0 0 0 1037 9614 35 65 1 0 0
20 0 140 2902016 341912 3952000 0 0 0 0 1046 9739 35 64 1 0 0
17 0 140 2903904 341912 3951888 0 0 0 76 1044 9879 37 63 0 0 0
16 0 140 2904580 341912 3952108 0 0 0 0 1055 9808 34 65 1 0 0从上面的数据可以看出几点:
1. context switch(cs)比 interrupts(in)要高得多,说明内核不得不来回切换进程;
2. 进一步观察发现 system time(sy)很高而 user time(us)很低,而且加上高频度的上下文切换(cs),说明正在运行的应用程序调用了大量的系统调用(system call);
3. run queue(r)在14个线程以上,按照这个测试机器的硬件配置(四核),应该保持在12个以内。r b swpdfree buff cache si so bi bo in cs us sy wa id
2 1 207740 98476 81344 180972 0 0 2496 0 900 2883 4 12 57 27
0 1 207740 96448 83304 180984 0 0 1968 328 810 2559 8 9 83 0
0 1 207740 94404 85348 180984 0 0 2044 0 829 2879 9 6 78 7
0 1 207740 92576 87176 180984 0 0 1828 0 689 2088 3 9 78 10
2 0 207740 91300 88452 180984 0 0 1276 0 565 2182 7 6 83 4
3 1 207740 90124 89628 180984 0 0 1176 0 551 2219 2 7 91 01、上下文切换数目高亍中断数目,说明当前系统中运行着大量的线程,kernel 中相当数量的时间都开销在线程的”上下文切换“。
2、大量的上下文切换将导致 CPU 利用率丌均衡.很明显实际上等待 io 请求的百分比(wa)非常高,以及 user time 百分比非常低(us). 说明磁盘比较慢,磁盘是瓶颈
3、因为 CPU 都阻塞在 IO 请求上,所以运行队列里也有相当数量的可运行状态线程在等待执行.参数介绍:
? r,可运行队列的线程数,这些线程都是可运行状态,只不过 CPU 暂时不可用;
? b,被 blocked 的进程数,正在等待 IO 请求;
? in,被处理过的中断数
? cs,系统上正在做上下文切换的数目
? us,用户占用 CPU 的百分比
? sy,内核和中断占用 CPU 的百分比
? wa,所有可运行的线程被 blocked 以后都在等待 IO,这时候 CPU 空闲的百分比
? id,CPU 完全空闲的百分比首先要确认系统性能问题是由CPU导致的而不是其他子系统。如果处理器为服务器瓶颈,可以通过相应调整来改善性能,这包括:
?使用ps -ef命令确保没有不必要的程序在后台运行。如果发现有不必要的程序,将其停止并使用cron将其安排在非高峰期运行。
? 通过使用top命令找出非关键性且消耗CPU较多的进程,并使用renice命令修改它们的优先级。
? 在基于SMP的机器中,尝试使用taskset将进程绑定到指定的CPU,确保进程不需要在处理器间忙碌,从而导致多次cache清空。
? 对于正在运行的应用程序,最好的办法是纵向升级(提升CPU频率)而不是横向升级(增加CPU数量)。这取决于你的应用程序是否能使用到多个处理器。例如一个单线程应用程序的升级方式最好是更换成更快的CPU而不是增加为多个CPU。
? 通常的做法还包括确认你所使用的是最新的驱动程序和韧体,因为这会影响CPU的负载。标签:出现 参数文件 并且 例子 run 需要 启动 调校 roc
原文地址:https://www.cnblogs.com/93bok/p/9684200.html