标签:连续 显示 挑战 网络架构 多个 自己的 尺寸 nes init
第15章 MiniVGGNet:更深的CNNs
VGGNet(或简称为VGG),第一次在文献《Very Deep Learning Convolutional Neural Networks for Large-Scale Image Recognition》提出。它们的贡献是具有非常小(3×3)的网络架构可被训练增加到很深的层次(16-19层)并且能够在ImageNet分类挑战上获得最新的分类。
之前,在深度学习文献的网络架构中使用混合核大小:CNN的第一层通常核大小为7×7或11×11,之后的层次中核大小逐渐减小到5×5,最后仅在网络的非常深的层次上使用3×3的核。
VGGNet独特的原因是它在整个网络架构中使用唯一的3×3的核。任何时候你看到一个网络架构整个都用3×3的核,你可以认为它来自于VGGNet。直接看VGGNet的整个16层或19层目前CNN的介绍来说太高深了,对于更细节的VGG16或VGG19,看ImageNet Bundle的第11章。
我们将回顾VGGNet的架构构成,且定义CNN要实现该架构必须满足的特性。之后,我们实现一个VGGNet的变种——MiniVGGNet。这个网络也将演示如何使用两个重要的层——BN层和Dropout层。
VGG家族的CNN构成主要有两个部分:
(1)所有的CONV层仅使用3×3的核;
(2)在应用POOL操作之前堆叠多个CONV=>RELU层(随着网络越深,连续的CONV=>RELU数目通常减少)。
在ShallowNet和LeNet网络中我们应用了一系列CONV=>RELU=>POOL层。但是,在VGGNet中,我们在应用单个POOL层之前将堆叠多个CONV=>RELU层。这个操作允许网络在通过POOL层对输入空间尺寸做下采样之前可以从CONV层中学习到更丰富的特征。
整体上,MiniVGGNet包含CONV => RELU => CONV => RELU => POOL这样的两个集合,之后跟着FC => RELU => FC => SOFTMAX层。前两个CONV层将学习32个3×3的核。后两个CONV层将学习64个同样是3×3的核。我们的POOL层将执行2×2核、stride为2×2的max pool操作。我们也将在每个激活层之后跟着BN层并且在POOL和FC层之后跟上Dropout层。
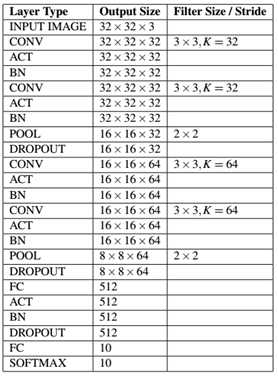
表15.1 MiniVGGNet层次表
网络架构细节见表15.1,网络的输入大小为32×32×3,因为我们在CIFAR-10上训练网络。再次注意,我们是如何在网络架构中应用BN层和Dropout层的。应用BN层可以降低过拟合的风险并且增加分类正确率。
根据网络蓝图如表15.1,我们使用keras库实现它。与第14章实现类似,我们在nn.conv子目录下新建minivggnet.py,作为我们MiniVGGNet的实现。且不要忘记在当前目录的__init__.py中添加导出的类名MiniVGGNet。
我们通过keras.layers.normalization import BatchNormalization,通过keras.layers.core import Dropout导入丢弃层。在定义类MiniVGGNet中,我们增加了一个变量chanDim表示通道优先顺序。因为BN层工作在通道上,我们需要该变量指明BN工作在哪个axis上。
之后的构建模型,根据蓝图一层一层构建即可,注意里面在构建POOL层时,我们用model.add(MaxPooling2D(pool_size=(2, 2)))而没有明确的指明stride的2×2大小,在keras中不指定stride时,默认stride大小等于该pool_size大小。我们还注意到model.add(Dropout(0.25))表示当前层的节点以25%的概率不连接到下一层节点上。我们第一模块的CONV层核大小为32,第二模块的CONV层核大小为64,即随着网络中越深空间输入尺寸越小,增加核的数目是很常见的操作。最后我们的FC层使用512节点,且注意到我们在两个FC层之间使用Dropout层,丢弃概率为50%,即在FC层之间通常的Dropout设置为0.5。
训练脚本类似于第14章的操作模式:加载CIFAR-10数据集、初始化MiniVGGNet架构、训练MiniVGGNet、评估网络性能。
我们创建minivggnet_cifar10.py的脚本,见GitHub。
我们首先导入必要的模块,这里使用matplotlib后台用AGG,表明我们将创建一个非交互性的仅保存到磁盘的结果文件,因为在一些通过ssh等远程登录的运行中,直接显示图片会造成matplotlib错误,因此这里直接使用agg作为使用,表示在训练完成后,直接把结果保存到磁盘上。
最重要的初始化优化器语句opt = SGD(lr=0.01, decay=0.01 / 40, momentum=0.9, nesterov=True),表示我们学习率α=0.01并且动量参数γ=0.9。设置nesterov=True表明我们在SGD中使用Nesterov加速。这里我们还使用一个特别的参数decay=0.01/40,用于随着时间缓慢的降低学习率参数。就像在下一章讨论的,降低学习率在降低过拟合和增加分类正确率方面很有用——学习率越小,权重更新越小。通常,decay的设置为学习率除以epoch数目。这里的epoch设置为40,初始学习率为lr=0.01,即设置decay=0.01/40。我们在评估MiniVGGNe时,采用两种方式,即一个具有BN层,另一个不具有BN层。
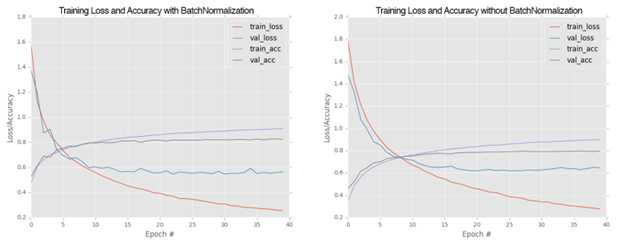
图15.2 具有BN层和不具有BN层损失对比图
我们首先在chapter15/下创建一个输入结果保存文件:output/cifar10_minivggnet_with_bn.png。然后直接执行python minivggnet_cifar10.py --output output/cifar10_minivggnet_with_bn.png即可开始训练,且将最终结果保存到该文件中。
结果如图15.2左图所示,可看到具有BN层的MiniVGGNet分类正确率大约在83%左右,这个结果要比ShallowNet的60%的分类正确率高很多。
我们将nn/conv/minivggnet.py文件中的所有BN层注释掉,即获得不具有BN层的MiniVGGNet网络模型。之后我们创建保存的图片文件:output/cifar10_minivggnet_without_bn.png。然后执行python minivggnet_cifar10.py --output output/cifar10_minivggnet_without_bn.png即可重新训练不具有BN层的结果。
训练结果如图15.2右图所示。我们注意到不具有BN层的训练要比具有BN层训练的快,但是训练完成后,它的验证正确率将只有79%左右。
通过上述图对比,我们可看到BN层的影响:在不具有BN层的图表中验证损失在30epoch后将增加,这表明网络在训练数据上过拟合了。我们还看到在25epoch后,验证损失变得比较平稳了。另一方面,具有BN层的MiniVGGNet更稳定。尽管损失和精确率在35epoch之前不平稳,但是它没有过拟合。这也是为什么建议在网络中使用BN层的原因。
本章讨论了CNNs的VGG家族。一个CNN可考虑是类VGG网络,如果(1)它不管网络多深,只使用3×3核;(2)在应用POOL层之前,堆叠多个CONV=>RELU层。
之后我们实现了一个类VGG网络——MiniVGGNet,这个网络考虑两个((CONV=>RELU)*2)=>POOL的结构,之后跟着FC => RELU => FC => SOFTMAX结构,我们也在每个激活层后跟着BN层以及在每个POOL核FC层后跟着Dropout层。
之后,我们在CIFAR-10上评估MiniVGGNet性能,结果建议在训练自己的网络时加入BN层。
标签:连续 显示 挑战 网络架构 多个 自己的 尺寸 nes init
原文地址:https://www.cnblogs.com/paladinzxl/p/9686017.html