标签:地址 host ast sla 主机 key 秘书 dir ram
拷贝机器
安装hadoop
配置etc/hadoop/hadoop-env.sh文件
sudo vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到“export JAVA_HOME=”部分,修改为本机jdk路径
配置etc/hadoop/core-site.xml文件
sudo vi /usr/local/hadoop/etc/hadoop/core-site.xml
在<configuration></configuration>中间添加如下内容:
master为namenode主机名,即/etc/hosts文件里的名字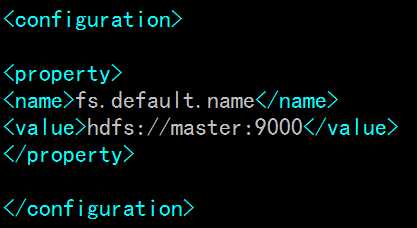
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop</value>
</property>配置hdfs-site.xml文件,若路径下没有此文件,则将hdfs-site.xml.template重命名
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!—NameNode节点秘书节点SecondaryNameNode配置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>cs-2:50090</value>
</property>
<value>1</value>中间的数字表示slave节点数配置mapred-site.xml
<!-- 指定mr运行在yarn上,默认是local,本地模仿一个资源环境 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>配置yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>cs-1</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>向slaves文件中添加slave主机名,一行一个
cs-1
cs-2
cs-3环境变量配置
命令:vi /etc/profile
export HADOOP_HOME=/export/server/hadoop-2.7.6
export PATH=${JAVA_HOME}/bin:$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
重新加载环境变量:source /etc/profile
拷贝
- 分别拷贝hadoop安装包和环境变量到cs-2,cs-3
--拷贝hadoop安装包到cs-2,cs-3
标签:地址 host ast sla 主机 key 秘书 dir ram
原文地址:https://www.cnblogs.com/pangrou/p/9690343.html