标签:客户机 超时 功能实现 ima get 包括 http 转发器 protoc
在介绍 HTTP 协议之前,先简单说一下TCP/IP协议的相关内容。TCP/IP协议是分层的,从底层至应用层分别为:物理层、链路层、网络层、传输层和应用层,如下图所示: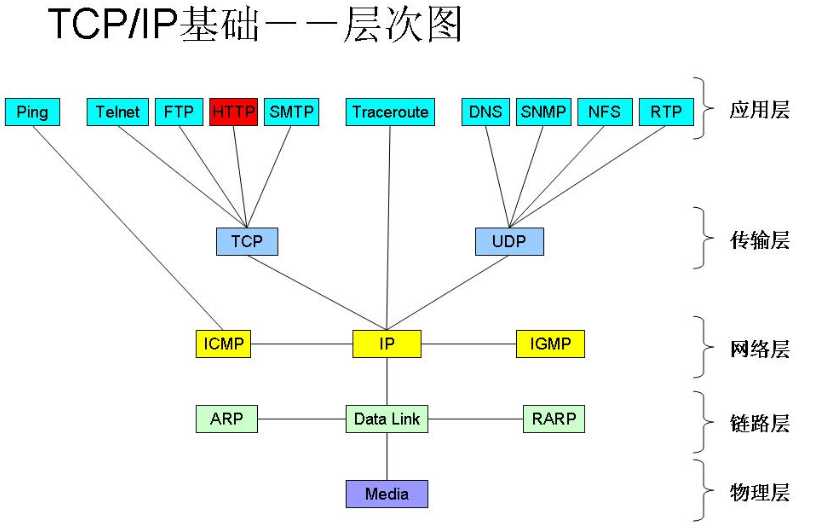
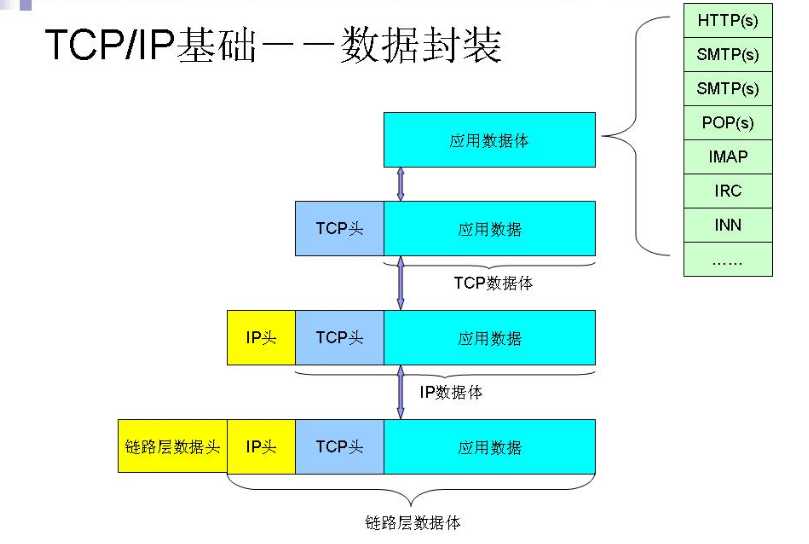
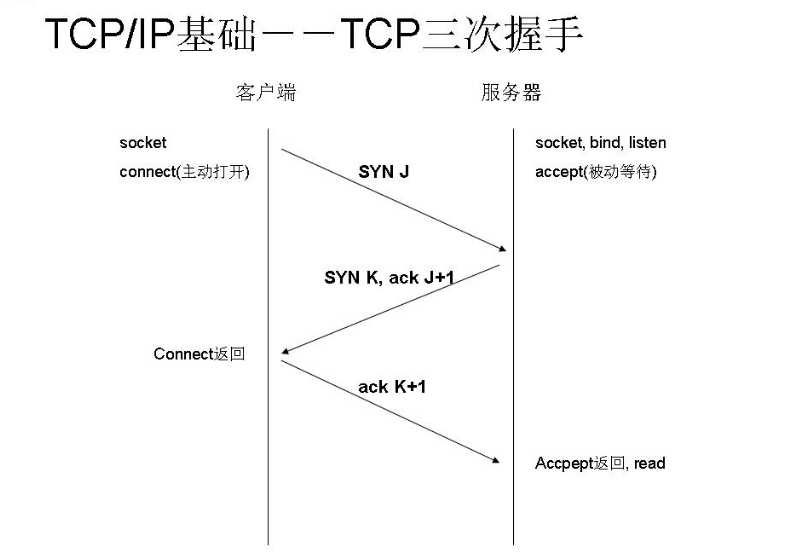
其中,对于TCP传输协议,客户端在于服务器建立连接前需要经过TCP三层握手,过程如下:
超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议,是互联网上应用最为广泛的一种网络协议。所有的www都必须遵守这个标准,设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
HTTP 是一种请求/响应式的协议。一个客户机与服务器建立连接后,发送一个请求给服务器;服务器接到请求后,给予相应的响应信息。
HTTP 的第一版本 HTTP/0.9是一种简单的用于网络间原始数据传输的协议;
HTTP/1.0由 RFC 1945 定义 ,在原 HTTP/0.9 的基础上,有了进一步的改进,允许消息以类 MIME 信息格式存 在,包括请求/响应范式中的已传输数据和修饰符等方面的信息;
HTTP/1.1(RFC2616) 的要求更加严格以确保服务的可靠性,增强了在HTTP/1.0 没有充分考虑到分层代理服务器、高速缓冲存储器、持久连接需求或虚拟主机等方面的效能;
安全增强版的 HTTP (即S-HTTP或HTTPS),则是HTTP协议与安全套接口层(SSL)的结合,使HTTP的协议数据在传输过程中更加安全。
端口对应的服务
21 ftp
22 ssh sftp
25 smtp
3306 mysql
873 rsync
161 snmp
111 rpc
3389 windows 远程桌面
80 http
443 https
110 pop3
55 dns
HTTP协议格式也比较简单,格式如下:
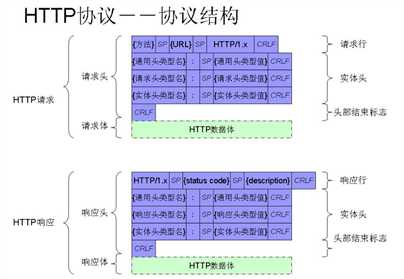
a) 通用头(general-header):
Cache-Control:客户端希望服务端如何缓存自己的请求数据。
Connection:客户端是否希望与服务端之间保持长连接。
Date:只有当请求方法为POST或get方法时客户端才可能会有些字段。
Pragma:包含了客户端一些特殊请求信息。
b) 请求头(request-header):
Accept: 表明客户同端可接受的请求回应的媒体类型范围列表。“*”用于按范围将类型分组,用“*/*”指示可接受全部类型;用“type/*”指示可接受 type类型的所有子类型,
Accept-Charset:客户端所能识别的字符集编码格式,格式:“Accept-Charset: 字符集1[:权重],字符集2[:权重]”,如:“ Accept-Charset: iso-8859-5, unicode-1-1;q=0.8”;
Accept-Language:客户端所能识别的语言,格式:“Accept-Language: 语言1[:权重],语言2[:权重]”,如:” Accept-Language: zh, en;q=0.7”;
Host:客户请求的主机域名或主机IP,格式:“Host: 域名或IP[:端口号]”,如:“Host: www.mysq.com:80“,请求行中若有HTTP/1.1则必须有该请求头;
User-Agent:表明用户所使用的浏览器标识,主要用于统计的目的;
Referer:指明该请求是从哪个关联连接而来;
Accept-Encoding:客户端所能识别的编码压缩格式,如:“Accept-Encoding: gzip, deflate”。
If- Modified-Since:该字段与客户端缓存相关,客户端所访问的URL自该指定日期以来在服务端是否被修改过,如果修改过则服务端返回新的修改后 的信息,如果未修改过则服务器返回304表明此请求所指URL未曾修改过。
If-None-Match:该字段与客户端缓存相关,客户端发送URL请求的同时发送该字段及标识,如 果服务端的标识与客户端的标识一致,则返回304表明此URL未修改过,如果不一致则服务端返回完整的数据信息,如:“If-None-Match: 0f0a893aad8c61:253, 0f0a893aad8c61:252, 0f0a893aad8c61:251”;
Cookie:为扩展字段,存储于客户端,向同一域名的服务端发送属于该域的cookie,如:“Cookie: MailUserName=whouse”;
c) 实体头(entity-header): (此类头存在时要求有数据体)
Content-Encoding:客户端所能识别的编码压缩格式,如:“Content-Encoding: gzip, deflate”;
Content-Length:客户端以POST方法上传数据时数据体部分的内容长度,如:“ Content-Length: 24”;
Content- Type:客户端发送的数据体的内容类型,如:“Content-Type: application/x-www-form-urlencoded”为以普通的POST方法发送的数据;“Content-Type: multipart/form-data; boundary=---------------------------5169208281820”,则表明数据体由多部分组成,分隔符为 “-----------------------------5169208281820”;

a) 通用头(general-header):
Cache- Control:服务端要求中间代理及客户端如何缓存自己响应的数据,如“Cache-Control: no-cache”,如:“Cache-Control: private” 不希望被缓存,“Cache-Control: public” 可以被缓存;
Connection:服务端是否希望与客户端之间保持长连接,;
Date:只有当请求方法为POST或get方法时客户端才可能会有些字段;
Pragma:包含了服务端一些特殊响应信息,如 “Pragma: no-cache” 服务端希望代理或客户端不应缓存结果数据;
Transfer-Encoding:服务端向客户端传输数据所采用的传输模式(仅在HTTP1.1中出现),如:“Transfer-Encoding: chunked”,注:该字段的优先级要高于“Content-Length” 字段的优先级;
Via:一般用在代理网关向应用服务器发送的请求头中,表明该来自客户端的请求经过了网关代理,
格式为:"Via: 请求协议版本 网关标识 [其它信息] ",
如 :" Via: 1.1 webcache_250_199.hexun.com:80 (squid)"
b)响应头(response-header):
Accept-Ranges:表明服务端接收的数据单位,如:“Accept-Ranges: bytes”, ;
Location:服务端向客户端返回此信息以使客户端进行重定向,如:“Location: http://www.hexun.com”;
Server:服务端返回的用于标识自己的一些信息,如:“ Server: Microsoft-IIS/6.0”;
ETag:服务端返回的响应数据的标识字段,客户端可根据此字段的值向服务器发送某URL是否更新的信息;
c)实体头(entity-header): (此类头存在时要求有数据体)
Content-Encoding:服务端所响应数据的编码格式。
Content-Length:服务端所返回数据的数据体部分的内容长度。
Content-Type:服务端所返回的数据体的内容类型。
Set-Cookie:服务端返回给客户端的cookie数据。
1xx:表明服务端接收了客户端请求,客户端继续发送请求;
2xx:客户端发送的请求被服务端成功接收并成功进行了处理;
3xx:服务端给客户端返回用于重定向的信息;
4xx:客户端的请求有非法内容;
5xx:服务端未能正常处理客户端的请求而出现意外错误。
比如:
“100” ; 服务端希望客户端继续;
“200” ; 服务端成功接收并处理了客户端的请求;
“301” ; 客户端所请求的URL已经移走,需要客户端重定向到其它的URL;
“304” ; 客户端所请求的URL未发生变化;
“400” ; 客户端请求错误;
“403” ; 客户端请求被服务端所禁止;
“404” ; 客户端所请求的URL在服务端不存在;
“500” ; 服务端在处理客户端请求时出现异常;
“501” ; 服务端未实现客户端请求的方法或内容;
“502” ; 此为中间代理返回给客户端的出错信息,表明服务端返回给代理时出错;
“503” ; 服务端由于负载过高或其它错误而无法正常响应客户端请求;
“504” ; 此为中间代理返回给客户端的出错信息,表明代理连接服务端出现超时。
GET、POST、HEAD、CONNECT、PUT、DELETE、TRACE、OPTIONS
| 方法 | 描述 |
|---|---|
| HEAD | 与 GET 相同,但只返回 HTTP 报头,不返回文档主体。 |
| PUT | 上传指定的 URI 表示。 |
| DELETE | 删除指定资源。 |
| OPTIONS | 返回服务器支持的 HTTP 方法。 |
| CONNECT | 把请求连接转换到透明的 TCP/IP 通道。 |
Html代码
a)GET请求
GET http://mail.test.com/ HTTP/1.1
Host: mail.test.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.0; zh-CN; rv:1.8.1) Gecko/20061010 Firefox/2.0
Accept: text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
Accept-Language: en-us,zh-cn;q=0.7,zh;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: gb2312,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Proxy-Connection: keep-alive
b)POST请求
POST / HTTP/1.1 Accept: image/gif, image/x-xbitmap, image/jpeg, application/vnd.ms-powerpoint, application/msword, */* Accept-Language: zh-cn Content-Type: application/x-www-form-urlencoded Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0) Host: www.test.com Content-Length: 24 Connection: Keep-Alive Cache-Control: no-cache name=value&submitsubmit=submit
c)POST方式上传文件
POST http://www.test.comt/upload_attach?uidl=%3C HTTP/1.1
Host: www.test.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.0; zh-CN; rv:1.8.1) Gecko/20061010 Firefox/2.0
Accept: text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
Accept-Language: en-us,zh-cn;q=0.7,zh;q=0.3
Accept-Charset: gb2312,utf-8;q=0.7,*;q=0.7
Content-Type: multipart/form-data; boundary=---------------------------5169208281820
Content-Length: 449
-----------------------------5169208281820
Content-Disposition: form-data; name="file_1"; filename=""
Content-Type: application/octet-stream
-----------------------------5169208281820
Content-Disposition: form-data; name="file_0"; filename="test.txt"
Content-Type: text/plain
hello world!
-----------------------------5169208281820
Content-Disposition: form-data; name="oper"
upload
-----------------------------5169208281820--
虽然我不写代码,但是还是说一下get与post传参区别吧,毕竟了解过,
1)get参数通过url传递,post放在request body中。
2)get请求在url中传递的参数是有长度限制的,而post没有
3)get比post更不安全,因为参数直接暴露在url中,所以不能用来传递敏感信息。
4)get请求只能进行url编码,而post支持多种编码方get请求会浏览器主动cache,而post支持多种编码方式。
5)get请求参数会被完整保留在浏览历史记录里,而post中的参数不会被保留。
GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同,GET产生一个TCP数据包;POST产生两个TCP数据包。
简单的说:
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
总结:http协议通信原理
1、http是osi模型中应用层协议。http协议的重要应用是www服务。
2、DNS解析原理
3、http请求信息包含的内容。
4、http服务返回的内容,消息主体也消息头。
5、用户通过浏览器访问站服务器的请求到返回数据流程。
概念:在网站设计中,纯粹HTML格式的网页(可以包含图片,JS(前端功能实现),CSS(样式)等)通常被称为“静态网页”。
特点:所有程序在客户浏览器端解析,客户端如:IE浏览器,你编的是什么,它显示的就是什么,一旦编写完成,就不会有任何改变。维护和更新比较麻烦。
(1)静态网页每个页面都有一个固定的URL,且网页URL一般以.htm、.html、.shtml等常见形式为后缀,而且地址中不含问好“?”或“&”
(2)网页内容一经发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都是保存在网页服务器上的,也就是说,静态网页是实实在在保存在服务器上的文件,每个网页都是一个独立的文件
(3)静态网页的内容相对稳定,因此,容易被搜索引擎收录(优点,seo)
(4)静态网页没有数据库的支持,在网站制作和维护方面工作量较大,因此当网站信息量很大时完全依靠静态网页制作的方式比较困难(缺点)
(5)静态网页的交互性较差,在功能方面有较大的限制(缺点)
(6)网页程序在用户浏览器端解析,如IE浏览器,这样程序解析效率更高,由于服务端不进行解析,因此可以接受更多的并发访问,当客户端向服务器请求数据时,服务器直接把数据返回(不做任何解析),当客户端拿到数据后,在浏览器端解析展现出来。
扩展名:常见扩展名为asp,aspx,php,jsp,cgi,perl等
(1)动态网页一般以数据库技术为基础,可以大大降低网站的维护工作量
(2)采用动态网页技术的网站可以实现更多的功能,如用户注册,用户登录,在线调查,投票,用户管理,订单管理,发博文等等
(3)动态网页大多并不是独立存在于服务器上的网页文件,只有当用户请求时服务器才返回一个完整的网页
(4)动态网页中的“?”对搜索的收录存在一定的问题,搜索引擎一般不可能从一个网站的数据库中访问全部网页,或者出于技术方面的考虑,搜索蜘蛛一般不会区抓取网址中的“?”后面的内容,因此采用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理(伪静态)才能适应搜索引擎的抓取的要求
(5)程序在服务端解析,服务端:php引擎,java容器(tomcat,resin,jboss)
(6)由于程序在服务端解析,因此,会消耗大量的CPU和内存等资源,因此,效率远不如静态网页。
伪静态特点:从URL地址里看,给人感觉是静态内容(如地址结尾带html),通过rewrite规则实现URL重写。地址规范、美观、有利于搜索引擎抓取。
1、动态网页伪装成静态
2、目的:便于搜索引擎搜录,提升用户访问量以及用户体验。
3、由于仅仅是伪装,实际上还是动态,性能没有提升,转换消耗资源因此性能反而下降。
4、尽可能转换成真正的静态页面,除非并发量不是很大,用rewrite实现伪静态。
DNS( Domain Name System)是“域名系统”的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,它用于TCP/IP网络,它所提供的服务是用来将主机名和域名转换为IP地址的工作。DNS就是这样的一位“翻译官”,它的基本工作原理可用下图来表示。

当 DNS 客户机需要查询程序中使用的名称时,它会查询本地DNS 服务器来解析该名称。客户机发送的每条查询消息都包括3条信息,以指定服务器应回答的问题。
1) 指定的 DNS 域名,表示为完全合格的域名 (FQDN) 。
2) 指定的查询类型,它可根据类型指定资源记录,或作为查询操作的专门类型。
3) DNS域名的指定类别,它始终应指定为 Internet 类别。
DNS 查询以各种不同的方式进行解析。客户机有时也可通过使用从以前查询获得的缓存信息就地应答查询。DNS 服务器可使用其自身的资源记录信息缓存来应答查询,也可代表请求客户机来查询或联系其他 DNS 服务器,以完全解析该名称,并随后将应答返回至客户机。这个过程称为递归。
另外,客户机自己也可尝试联系其他的 DNS 服务器来解析名称。如果客户机这么做,它会使用基于服务器应答的独立和附加的查询,该过程称作迭代,即DNS服务器之间的交互查询就是迭代查询。
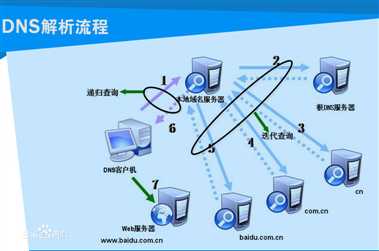
1、在浏览器中输入www.baidu.com域名,操作系统会先检查自己本地的hosts文件是否有这个网址映射关系,如果有,就先调用这个IP地址映射,完成域名解析。
2、如果hosts里没有这个域名的映射,则查找本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析。
3、如果hosts与本地DNS解析器缓存都没有相应的网址映射关系,首先会找TCP/ip参数中设置的首选DNS服务器,在此我们叫它本地DNS服务器,此服务器收到查询时,如果要查询的域名,包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析,此解析具有权威性。
4、如果要查询的域名,不由本地DNS服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析,此解析不具有权威性。
5、如果本地DNS服务器本地区域文件与缓存解析都失效,则根据本地DNS服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地DNS就把请求发至根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(baidu.com)给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找baiducom域服务器,重复上面的动作,进行查询,直至找到www.qq.com主机。
6、如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根DNS或把转请求转至上上级,以此循环。不管是本地DNS服务器用是是转发,还是根提示,最后都是把结果返回给本地DNS服务器,由此DNS服务器再返回给客户机。
标签:客户机 超时 功能实现 ima get 包括 http 转发器 protoc
原文地址:https://www.cnblogs.com/liang-io/p/9691938.html