标签:apr 安装nagios cin bak 指定 tin 联系人 tar user
nagios 监控服务应用指南
小区:视频监控,保安
企业工作中为什么要部署监控系统
监控系统相当于哨兵的作用,监控几百台上千台服务器,监控系统非常重要。
监控系统都需要监控
1. 本地资源:负载uptime cpu(top,sar),磁盘(df),内存(free),io(iostat),raid,温度,passwd文件的变化,本地所有文件指纹识别
2. 网络服务:端口,url ,丢包,进程数,网络流量
3. 其他设备: 路由器、交换机端口流量,打印机,windows等
4. 业务数据:用户登录失败次数,用户登录网站次数,输入验证码失败的次数,某个api
接口流量并发,电商网站定单,支付交易的数量。
5. 监控软件本身仅仅是一个平台,我们想监控的内容,理论上只要在服务器命令行可以获取到就可以被监控软件监控
前言 nagios 监控工具介绍及原理
nagios(难够死)监控工具介绍与优势
nagios是一款开源的网络及服务的监控工具,功能强大,灵活性强,能有效监控 windows linux和unix 等系统的主机各种状态信息,交换机,路由器等设备,主机端口及url服务等,根据不同业务故障级别发出告警信息(邮件、微信、短信、语音报警、飞信、msn)给管理员,当故障恢复时也会发出恢复消息给管理员
nagios服务端可以在linux系统和类unix系统上运行,目前无法再windows上运行(客户端软件),windows可以作为被监控的主机,但是不能被作为监控服务器
nagios 官方网站地址为http://www.nagios.org
nagios的特点
01)监控网络服务(smtp 、pop3 、http、tcp、ping等)
02)监控主机资源
03)简单的插件设计模式使得用户可以方便的定制符合自己的服务的检测方法
04)并行服务检查机制
05)具备定义网络分层结构的能力,用‘parent’主机定义来表达网络主机间的关系,这种 关系可被用来返现和明晰主机宕机或不可达状态
06)当服务或主机问题产生与解决后将及时通报联系人(mail、im、sms、sound);
07)自动的日志回滚
08)可选的web界面用于查看当前的网络状态、通知和故障历史、日志文件等
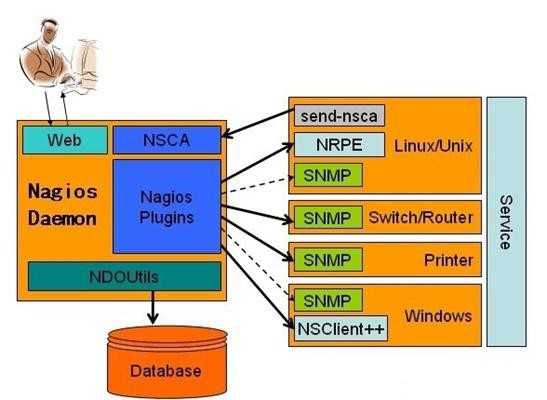
14.2.3 nagios监控系统家族成员的构成
nagios监控一般由一个主程序(nagios)、一个插件程序(nagios-plugins)和一些可选的附加程序(NRPE、NSClient++、NSCA和NDOUtils)等组成
nagios本身只是一个监控的品台而已,其具体的监控工作都是通过各类插件(例如:nagios-plugins)来实现的,也可以自己编写插件,因此,nagios主程序和nagios-plugins插件都是nagios服务器端必须安装的程序组建。不过,一般nagios-plugins也要安装于被监控端,用来获取响应的数据,nagios可选的附加组建描述如下
1.NRPE组件
存在的位置:工作于被监控端,操作系统为linux系统
作用:用于在被监控的远程主机上执行脚本插件,获取数据回传给服务器端,以实现对这些主机资源和服务的监控
存在形式:守护进程模式,开启的端口号是5666
监控的资源:主要用于监控本地资源,包括负载(uptime)、cpu(top、sar)磁盘(df -hi)
内存(free)、io(iostat)、raid磁盘故障、cpu温度、passwd文件的变化,以及本地所有文件的指纹识别监控,当然也可以监控进程、端口、url等
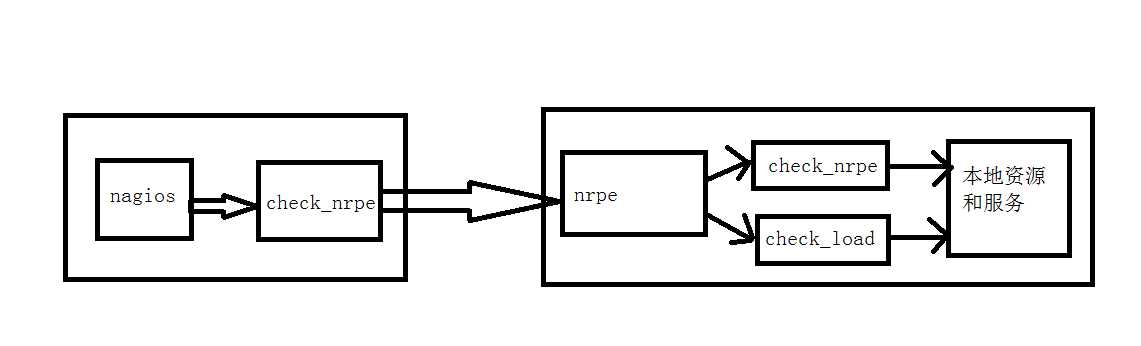
图为nrpe组件的运行原理图
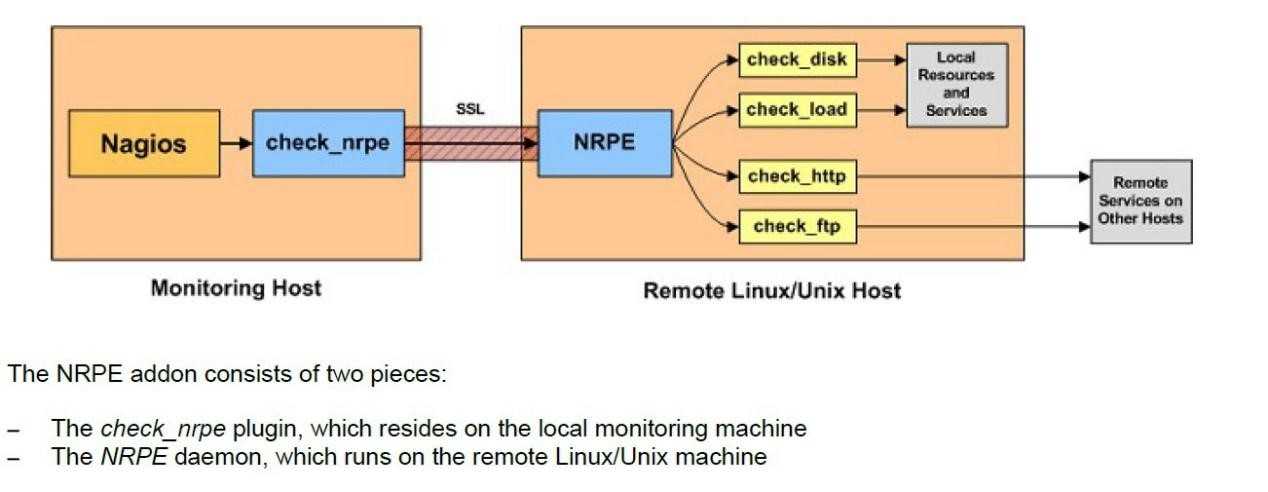
工作原理:通常由nagios服务器端发起获取数据请求,由check_nrpe插件携带要获取的命令,传给被监控端的nrpe守护进程,nrpe进程读取nrpe.cfg里对应服务器端发送的命令信息,调用本地插件获取数据,然后返回给nagios服务器端check_nrpe,进而传给nagios展示到web界面中,严格讲可以称之为半被动工作模式,本文主要讲解这个npre组件的功能
1.NSClient++组件
用于被监控端为windows系统的服务器
2.NDOUtils组件(不推荐用)
作用:将nagios的配置信息和各event产生的数据存入数据库
3.nsca组件 目前应用场景较少
14.2.4 nagios监控系统完整图解
14.3 nagios服务器的安装
14.3.1 nagios安装准备
1)准备三台服务器
|
管理ip地址 |
角色 |
备注 |
|
192.168.1.11 |
nagios-server |
nagios服务器端 |
|
192.168.1.12 |
web01 |
被监控的客户端 |
|
192.168.1.13 |
web02 |
被监控的客户端 |
2)解决perl软件编译问题
[root@hd1 ~]# echo ‘export LC_ALL=C‘ >>/etc/profile
[root@hd1 ~]# tail -1 /etc/profile
export LC_ALL=C
[root@hd1 ~]# source /etc/profile
[root@hd1 ~]# echo $LC_ALL
C
3)关闭nagios server端防火墙及SELINUX
通过配置文件查看selinux的状态
[root@hd1 ~]# cat /etc/selinux/config
用命令关闭 selinux
[root@hd05 ~]# setenforce 0
5)安装nagios服务器端所需软件包
nagios服务器端需要有web界面展示监控效果,界面的展示主要使用php程序,因此,需要lamp环境,有些网友总想安装lnmp环境,这完全是自我麻烦,yum安装的lamp环境是配合nagios服务端展示界面的最佳环境
安装下面软件包
[root@hd1 ~]# yum install gcc glibc glibc-common -y
[root@hd1 ~]# yum install gd gd-devel -y
[root@hd1 ~]# yum -y install mysql-server
[root@hd1 ~]# yum install httpd php php-gd -y
查看
[root@hd1 ~]# rpm -qa mysql httpd php
mysql-5.1.73-3.el6_5.x86_64
php-5.3.3-38.el6.x86_64
httpd-2.2.15-39.el6.centos.x86_64
6)创建nagios服务器端需要的用户及组
批量执行命令如下:
[root@hd1 ~]# useradd nagios
[root@hd1 ~]# groupadd nagcmd
[root@hd1 ~]# usermod -a -G nagcmd nagios
[root@hd1 ~]# usermod -a -G nagcmd apache
[root@hd1 ~]# id -n -G nagios
nagios nagcmd
[root@hd1 ~]# id -n -G apache
apache nagcmd
[root@hd1 ~]# groups nagios
nagios : nagios nagcmd
[root@hd1 ~]# groups apache
apache : apache nagcmd
7)启动lamp环境的http服务
[root@hd1 ~]# /etc/init.d/httpd start
[root@hd1 ~]# /etc/init.d/httpd start
Starting httpd: httpd: apr_sockaddr_info_get() failed for hd1.com
httpd: Could not reliably determine the server‘s fully qualified domain name, using 127.0.0.1 for ServerName
[ OK ]
14.3.2安装nagios服务器端
[root@hd1 ~]# tar xf nagios-3.5.1.tar.gz
[root@hd1 ~]# cd nagios
[root@hd1 nagios]# ./configure --with-command-group=nagcmd
[root@hd1 nagios]#make all
[root@hd1 nagios]#make install
[root@hd1 nagios]# make install-init 安装初始化脚本到/etc/init.d/
[root@hd1 nagios]# make install-config 生成nagios模板配置
[root@hd1 nagios]# make install-commandmode 安装配置目录许可外部命令文件
1)安装nagios web配置文件及创建登录用户
接着来安装nagios web配置文件(生成nagios对应于apache里的配置文件)
[root@hd1 nagios]# make install-webconf
创建nagios web监控界面后,登入时需要用户名及密码,这里分别为admin和123456
[root@hd1 nagios]# htpasswd -bc /usr/local/nagios/etc/htpasswd.users admin 123456
Adding password for user admin
[root@hd1 nagios]# cat /usr/local/nagios/etc/htpasswd.users
admin:4SH4NvORhXMFs
重新加载apache服务
[root@hd1 nagios]# /etc/init.d/httpd reload
2)配置启动apache服务
启动apache服务加入系统开机自启动
[root@hd1 ~]# chkconfig httpd on
打开客户端上的浏览器访问http://192.168.1.11/nagios 用户名是:admin密码是123456
1)安装nagios插件软件包
nagios插件软件包就是一些实现获取数据信息的命令或程序,通过这些命令或程序, nagios可以获取到需要的数据,然后进行报警和展示,具体安装过程如下:
先安装基础依赖包
[root@hd1 ~]# yum -y install perl-devel openssl-devel -y
安装nagios plugins插件包
[root@hd1 ~]#tar xf nagios-plugins-1.4.13.tar.gz
[root@hd1 ~]# cd nagios-plugins-1.4.13
[root@hd1 nagios-plugins-1.4.13]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios --with-mysql
[root@hd1 nagios-plugins-1.4.13]make
[root@hd1 nagios-plugins-1.4.13]make install
查看插件个数
[root@hd1 nagios-plugins-1.4.13]# ls /usr/local/nagios/libexec/|wc -l
61
2)安装nrpe软件
nrpe是客户端安装的软件,为什么还要安装在nagios服务器端?
1.nagios服务端需要check_nrpe插件做被动检查,如果服务器端不装nrpe软件,就没有check_npre这样的检查插件
2.nagios服务器端本地的资源也需要被监控,因此,nagios服务端也会被作为客户端
[root@hd1 ~]# tar zxvf nrpe-2.12.tar.gz
[root@hd1 ~]# cd nrpe-2.12
[root@hd1 nrpe-2.12]# ./configure
[root@hd1 nrpe-2.12]# make all
[root@hd1 nrpe-2.12]# make install-plugin
[root@hd1 nrpe-2.12]# make install-daemon
[root@hd1 nrpe-2.12]# make install-daemon-config
检查check_nrpe插件
[root@hd1 ~]# ls /usr/local/nagios/libexec/check_nrpe
/usr/local/nagios/libexec/check_nrpe
[root@hd1 nrpe-2.12]# ls /usr/local/nagios/libexec/|wc -l
62
提示:生成的nrpe的配置文件为/usr/local/nagios/etc/nrpe.cfg
6.配置并启动nagios服务
[root@hd1 ~]# chkconfig nagios on
[root@hd1 ~]# chkconfig nagios --list
nagios 0:off 1:off 2:on 3:on 4:on 5:on 6:off
7.更好的设置自动开机的方法是:
[root@hd1 ~]# echo "/etc/init.d/nagios start" >>/etc/rc.local
检验nagios配置文件(检查语法)
[root@hd1 ~]# /etc/init.d/nagios checkconfig
Running configuration check... OK.
此命令为检查语法的命令,但是只能报告对错无法给出错误的信息
可以使用命令行检查报错,并输出信息
[root@hd1 ~]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Total Warnings: 0
Total Errors: 0
可以修改/etc/init.d/nagios实现上述命令行检查语法的详细输出,如下:
[root@hd1 ~]# grep ‘checkconfig)‘ -n -A 2 /etc/init.d/nagios
181: checkconfig)
182- printf "Running configuration check..."
183- $NagiosBin -v $NagiosCfgFile > /dev/null 2>&1;
grep表示搜索 checkconfig) 字符串,-n表示打印行号,-A 2 表示打印符合条件字符串最近的两行
把 $NagiosBin -v $NagiosCfgFile > /dev/null 2>&1的输出重定向去掉就可以

[root@hd1 ~]# /etc/init.d/nagios checkconfig
Total Warnings: 0
Total Errors: 0
最后浏览nagios web界面检查,打开浏览器访问
到此,nagios服务端的安装及配置就告一段落
14.4 nagios客户端安装
14.4.1 nagios客户端安装准备
准备2台服务器或vm虚拟机
安装基础系统软件
[root@hd2 ~]# yum install gcc glibc glibc-common -y
[root@hd2 ~]# yum install mysql-server -y
安装这个目的是为了安装nagios plugins 生成check_mysql插件
上传nagios相关软件
添加nanios用户
[root@hd2 ~]# useradd nagios -M -s /sbin/nologin
[root@hd2 ~]# id nagios
uid=503(nagios) gid=503(nagios) groups=503(nagios)
安装nagios-plugins插件
[root@hd2 ~]# yum install perl-devel perl-CPAN openssl-devel -y
[root@hd2 ~]# tar xf nagios-plugins-1.4.13.tar.gz
[root@hd2 ~]# cd nagios-plugins-1.4.13
[root@hd2 nagios-plugins-1.4.13]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios --enable-perl-modules --with-mysql
[root@hd2 nagios-plugins-1.4.13]#make && make install
此时,检查插件个数
[root@hd2 ~]# ls /usr/local/nagios/libexec/|wc -l
59
5.安装nagios客户端的nrpe软件
[root@hd2 ~]# tar xf nrpe-2.12.tar.gz
[root@hd2 ~]# cd nrpe-2.12
[root@hd2 nrpe-2.12]# ./configure
[root@hd2 nrpe-2.12]# make all
[root@hd2 nrpe-2.12]#make install-plugin
[root@hd2 nrpe-2.12]#make install-daemon
[root@hd2 nrpe-2.12]#make install-daemon-config
6.安装其他相关的插件
以下是check_iostat插件需要的依赖包
root@hd2 ~]# tar zxf Params-Validate-0.91.tar.gz
[root@hd2 ~]# cd Params-Validate-0.91
[root@hd2 Params-Validate-0.91]# perl Makefile.PL
[root@hd2 Params-Validate-0.91]# make && make install
[root@hd2 ~]# tar zxf Class-Accessor-0.31.tar.gz
[root@hd2 ~]# cd Class-Accessor-0.31
[root@hd2 Class-Accessor-0.31]# perl Makefile.PL
[root@hd2 Class-Accessor-0.31]# make && make install
[root@hd2 ~]# tar zxf Config-Tiny-2.12.tar.gz
[root@hd2 ~]# cd Config-Tiny-2.12
[root@hd2 Config-Tiny-2.12]# perl Makefile.PL
[root@hd2 Config-Tiny-2.12]# make && make install
[root@hd2 ~]# tar zxf Math-Calc-Units-1.07.tar.gz
[root@hd2 ~]# cd Math-Calc-Units-1.07
[root@hd2 Math-Calc-Units-1.07]# perl Makefile.PL
[root@hd2 Math-Calc-Units-1.07]# make && make install
[root@hd2]# tar zxf Regexp-Common-2010010201.tar.gz
[root@hd2]# cd Regexp-Common-2010010201
[root@hd2 Regexp-Common-2010010201]# perl Makefile.PL
[root@hd2 Regexp-Common-2010010201]# make && make install
[root@hd2 ~]# tar zxf Nagios-Plugin-0.34.tar.gz
[root@hd2 ~]# cd Nagios-Plugin-0.34
[root@hd2 Nagios-Plugin-0.34]# perl Makefile.PL
[root@hd2 Nagios-Plugin-0.34]# make && make install
[root@hd2 ~]# yum install sysstat -y
sysstat工具包中包含两类工具,分别为即时查看工具(iostat、mpstat、sar)和累计统计工具(sar)可以看到,这两类工具都有sar,可见sar具有着两种功能
为了实现sar的累计统计功能,系统必须周期性的记录当时的信息,这是通过调用/usr/lib/sa中的三个工具实现的
sa1 :收集并存储每天的系统动态信息到一个二进制的文件中,用作sadc的前端程序
sa2:收集每天的系统活跃信息写入总结性的报告,用作sar的前端程序
sadc:系统动态数据收集工具,收集的数据被写入一个二进制文件中,用作sar工具的后端程序
这里针对监视物理组件的高级linux命令小结如下:
内存:top free vmstat mpstat iostat sar
cpu:top vmstat mpstat iostat sar
i/o:vmstat mpstat iostat sar
进程:ipcs、ipcrm
负载:uptime
7.配置监控内存、磁盘i/o脚本插件
将上传的两个文件复制到对应的目录
[root@hd2 ~]# cp check_memory.pl /usr/local/nagios/libexec/
[root@hd2 ~]# cp check_iostat /usr/local/nagios/libexec/
授权脚本可执行
[root@hd2 ~]# chmod 755 /usr/local/nagios/libexec/check_memory.pl
[root@hd2 ~]# chmod 755 /usr/local/nagios/libexec/check_iostat
改变脚本格式为unix的格式
[root@hd2 ~]# yum -y install dos2unix # 安装dos2unix命令
[root@hd2 ~]# dos2unix /usr/local/nagios/libexec/check_memory.pl
dos2unix: converting file /usr/local/nagios/libexec/check_memory.pl to UNIX format ...
[root@hd2 ~]# dos2unix /usr/local/nagios/libexec/check_iostat
dos2unix: converting file /usr/local/nagios/libexec/check_iostat to UNIX format ...
14.4.4 配置nagios客户端nrpe服务
[root@hd2 ~]# cd /usr/local/nagios/etc
[root@hd2 etc]# cp nrpe.cfg nrpe.cfg.bak # 备份原始配置文件
[root@hd2 etc]# sed -n 79p nrpe.cfg #print
allowed_hosts=127.0.0.1
[root@hd2 etc]# sed -i ‘s#allowed_hosts=127.0.0.1#allowed_hosts=127.0.0.1,192.168.1.11#‘ nrpe.cfg
[root@hd2 etc]# sed -n 79p nrpe.cfg
allowed_hosts=127.0.0.1,192.168.1.11
加入可以监控nagios server的ip地址192.168.1.11
使用vim命令编辑nrpe.cfg的内容
1)注释199-203的内容

2)在下面添加新内容
command[check_load]=/usr/local/nagios/libexec/check_load -w 15,10,5 -c 30,25,20
command[check_mem]=/usr/local/nagios/libexec/check_memory.pl -w 10% -c 3%
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 15% -c 7% -p /
command[check_swap]=/usr/local/nagios/libexec/check_swap -w 20% -c 10%
command[check_iostat]=/usr/local/nagios/libexec/check_iostat -w 6 -c 10

我们一般通过nrpe去客户端执行脚本插件获取信息,这样的模式成为被动监控,与nsca的客户端主动提交结果不冲突,由nagios服务端通过nrpe插件定时在client的nrpe服务上获取信息
启动nagios nrpe守护进程
[root@hd2 etc]# /usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d
[root@hd2 etc]# netstat -lntup|grep nrpe
tcp 0 0 0.0.0.0:5666 0.0.0.0:* LISTEN 93592/nrpe

这时,可以将nrpe加入开机自启动了,命令如下
[root@hd2 etc]# echo "/usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d" >>/etc/rc.local
注意:客户端nrpe.cfg配置文件,最好保留一份到计算机上,这样以后在其他的机器上装nrpe时,直接上传即可
到此,客户端的安装配置部分全部结束
14.5 nagios服务器端监控
14.5.1 nagios服务器端监控基础介绍
1. nagios服务器端目录结构
[root@hd1 ~]# ls -l /usr/local/nagios
total 24
drwxrwxr-x. 2 nagios nagios 4096 Oct 21 17:43 bin
drwxrwxr-x. 3 nagios nagios 4096 Oct 21 17:43 etc
drwxrwxr-x. 2 nagios nagios 4096 Oct 21 17:43 libexec
drwxrwxr-x. 2 nagios nagios 4096 Oct 20 17:09 sbin
drwxrwxr-x. 11 nagios nagios 4096 Oct 21 16:55 share
drwxrwxr-x. 5 nagios nagios 4096 Oct 20 17:12 var
bin 目录为nagios相关命令
etc目录为nagios的配置文件及目录信息
etc
|-- cgi.cfg
|-- cgi.cfg~
|-- htpasswd.users
|-- nagios.cfg
|-- nagios.cfg~
|-- nrpe.cfg
|-- objects
| |-- commands.cfg
nagios.cfg主配置文件
nrpe.cfg服务器端的nrpe的配置文件
objects具体对象配置文件
libexec为所有插件的目录路径
var为nagios数据及日志目录
share为nagios界面展示的php程序等内容的目录
所有客户端本地服务的监控都是通过执行libexec目录下的插件来实现的,如果开启了snmp(简单网络管理协议)
nagios服务器端也可以主动抓取
2. nagios服务器端核心配置文件
objects目录里面放的是主配置文件nagios.cfg包含的其他nagios配置文件

|
配置文件名称 |
说明 |
|
command.cfg |
存放nagios命令相关配置,这里的命令是nagios里定义的命令和插件命令相关联的一个文件 |
|
services.cfg |
存放具体被监控的服务相关配置文件内容 |
|
hosts.cfg |
存放具体被监控主机相关的配置内容 |
|
contacts.cfg |
存放报警联系人相关配置的文件 |
|
timeperiods.cfg |
存放报警周期时间等相关配置内容 |
|
templates.cfg |
模板配置文件 |
3. 配置主配置文件nagios.cfg
[root@hd1 etc]# vim nagios.cfg +34
#cfg_file=/usr/local/nagios/etc/objects/localhost.cfg
cfg_file=/usr/local/nagios/etc/objects/hosts.cfg
cfg_file=/usr/local/nagios/etc/objects/services.cfg

添加37,38行注释掉36行
localhost.cfg这个配置为监控服务器本地服务的配置文件,注释掉,然后统一监控
根据已有数据生成hosts.cfg主机文件
[root@hd1 etc]# cd /usr/local/nagios/etc/objects/
[root@hd1 objects]# head -51 localhost.cfg >hosts.cfg
[root@hd1 objects]# chown nagios.nagios hosts.cfg
生成新的services.cfg服务文件
[root@hd1 objects]# touch services.cfg
[root@hd1 objects]# chown nagios.nagios services.cfg
最后生成服务的配置文件目录,所有放到此目录下的配置都会自动被包含到主配置文件中生效
[root@hd1 objects]# mkdir services
[root@hd1 objects]# chown -R nagios.nagios services
1. nagios监控模式定义及监控模式选择
根据监控的行为,将nagios的监控分为主动和被动
主动监控:nagios服务器发出请求的主动探测监控方式,不需要客户端安装任何插件
被动监控:nagios服务端通过nrpe插件定时去连接client的nrpe服务获取信息,并发回到nagios服务器的监控是被动监控,这类监控通常是针对本地资源的
如何选择主动和被动监控
1.对于本地的资源查看,一般是被动模式例如:负载,内存、硬盘、温度、风扇等
2.对于web服务,数据库服务这种能对外提供服务的,一般是主动监控 例如httpd sshd mysqld rsyncd 等
主动模式和被动模式也可以相互转换
14.5.2 配置nagios服务器端监控项
1.定义要监控的nagios客户端主机
hosts.cfg一般用来存放nagios要监控的主机相关配置,下面是hosts.cfg中的主机定义部分的配置参数详解
添加所有需要监控的客户端主机和主机组
例如:
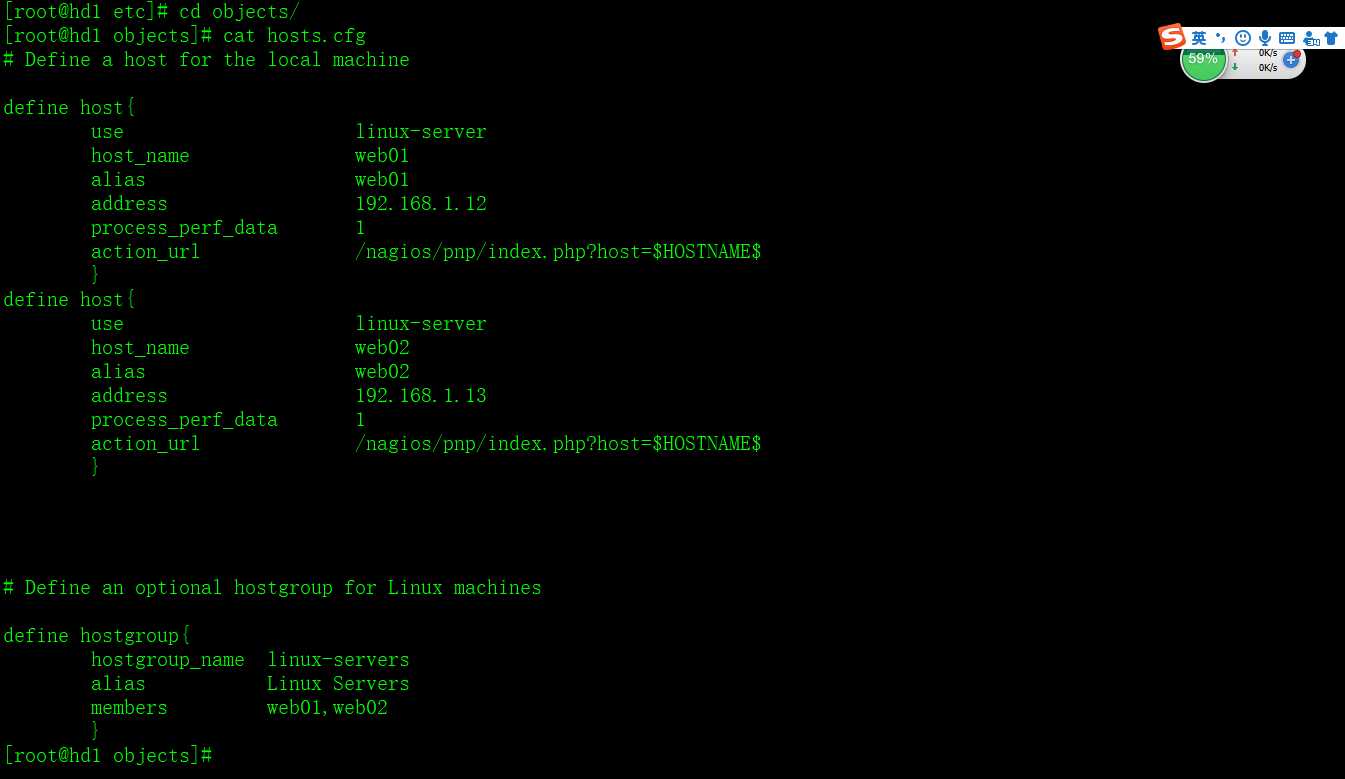
2.配置services.cfg,定义要监控的资源服务
实例如下
[root@hd1 objects]# vim services.cfg
define service {
use generic-service
host_name web01
service_description Disk Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name web01
service_description swap useage
check_command check_nrpe!check_swap
}
define service {
use generic-service
host_name web01
service_description mem useage
check_command check_nrpe!check_mem
}
define service {
use generic-service
host_name web01
service_description current load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name web01
service_description disk iostat
check_command check_nrpe!check_iostat!5!11
}
define service {
use generic-service
host_name web01
service_description ping
check_command check_ping!100.0,20%!500.0,60%
}
提示:check_nrpe是服务器端的插件(是commands.cfg里预先定义的命令名),负责和客户端的nrpe进程交流并执行check_nrpe叹号后的插件,所以,check_nrpe!check_load中的check_load是客户端的插件名,是在客户端的nrpe进程对应的配置nrpe.cfg定义的命令名
nagios软件默认没有提供客户端的内存和i/o插件,但是本文在配置时已经复制进去了,因此,只需在commands.cfg里配置即可
3..调试hosts.cfg和services.cfg的所有配置
1)需要在commands.cfg中加入check_nrpe的插件配置

执行检查语法命令
[root@hd1 objects]# /etc/init.d/nagios checkconfig
Total Warnings: 0
Total Errors: 0
警告和错误都是0 表示已经ok了
启动nagios服务
[root@hd1 objects]# /etc/init.d/nagios reload
Running configuration check...done.
Reloading nagios configuration...done
此时,可以看到自己配置的本地个系统状态的监控结果了
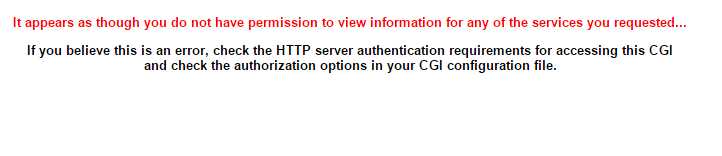
出现如上结果,表示登录web用户没有被许可查看这些服务资源,可按照如下方法解决上面的问题
[root@hd1 objects]# cd /usr/local/nagios/etc
查看权限
[root@hd1 etc]# grep "^authorized_for" cgi.cfg
authorized_for_system_information=nagiosadmin
authorized_for_configuration_information=nagiosadmin
authorized_for_system_commands=nagiosadmin
authorized_for_all_services=nagiosadmin
authorized_for_all_hosts=nagiosadmin
authorized_for_all_service_commands=nagiosadmin
authorized_for_all_host_commands=nagiosadmin
替换成admin用户
[root@hd1 etc]# sed -i ‘s#nagiosadmin#admin#g‘ cgi.cfg
再次查看
[root@hd1 etc]# grep "^authorized_for" cgi.cfg
authorized_for_system_information=admin
authorized_for_configuration_information=admin
authorized_for_system_commands=admin
authorized_for_all_services=admin
authorized_for_all_hosts=admin
authorized_for_all_service_commands=admin
authorized_for_all_host_commands=admin
重新加载配置文件
[root@hd1 etc]# /etc/init.d/nagios reload
再次通过浏览器查看
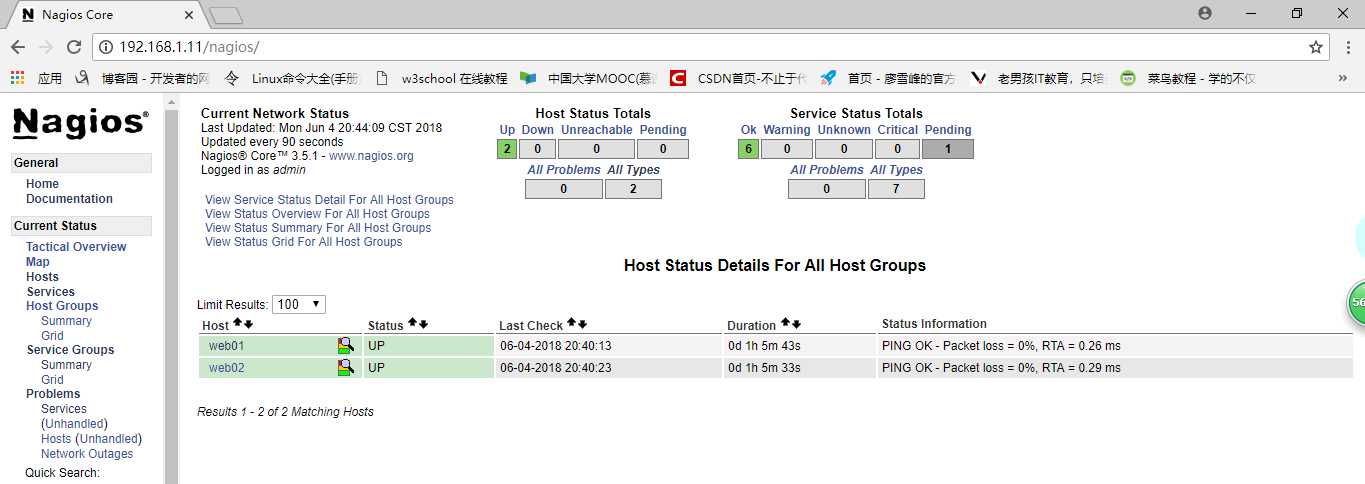
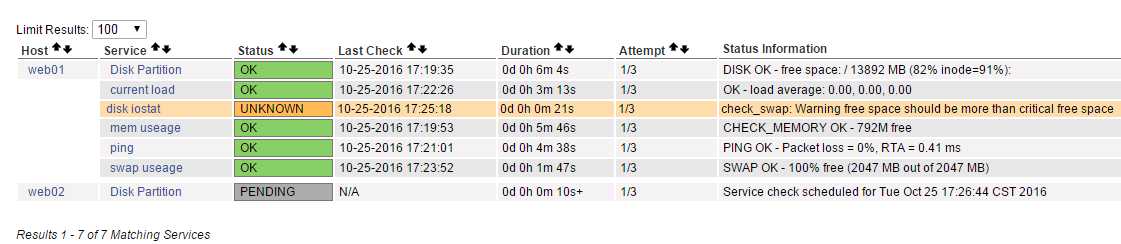
up 意思是服务器正常
pending的意思是服务器还没确定状态 稍等
红色表示有故障
提示:
1)最好换掉默认管理员用户nagiosadmin,替换成admin
2)遇到调试问题注意查看/usr/local/nagios/var/nagios.log这点很重要
#要养成经常查看日志的习惯
》》》》基于nagios监控原理排错的案例
nagios被动监控的原理其实就是利用下面这个命令工作的
[root@hd1 objects]# /usr/local/nagios/libexec/check_nrpe -H 192.168.1.12 -c check_iostat
IOSTAT OK - user 0.07 nice 0.00 sys 0.20 iowait 0.04 idle 0.00 | iowait=0.04%;; idle=0.00%;; user=0.07%;; nice=0.00%;; sys=0.20%;;
我们来看一个错误的案例

上图说明有一个服务显示不正常 disk iostat
1)在nagios服务器端执行如下命令
[root@hd1 objects]# /usr/local/nagios/libexec/check_nrpe -H 192.168.1.12 -c check_iostat
check_swap: Warning free space should be more than critical free space
这个跟图形报错一样
2)在客户端本地执行脚本检查命令
[root@hd2 ~]# cd /usr/local/nagios/libexec/
[root@hd2 libexec]# ./check_iostat -w 6 -c 10
IOSTAT OK - user 0.07 nice 0.00 sys 0.20 iowait 0.04 idle 0.00 | iowait=0.04%;; idle=0.00%;; user=0.07%;; nice=0.00%;; sys=0.20%;;
发现很正常,这说明客户端的配置文件或者是服务器端的配置文件的问题
3)检查客户端的配置文件
[root@hd2 etc]# vim nrpe.cfg
command[check_swap]=/usr/local/nagios/libexec/check_swap -w 20% -c 10%
command[check_iostat]=/usr/local/nagios/libexec/check_swap -w 20% -c 10%
4)修改
command[check_swap]=/usr/local/nagios/libexec/check_swap -w 20% -c 10%
command[check_iostat]=/usr/local/nagios/libexec/check_iostat -w 6 -c 10
5)重启
[root@hd2 etc]# pkill nrpe
[root@hd2 etc]# /usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d
6)刷新查看(务必耐心等待)
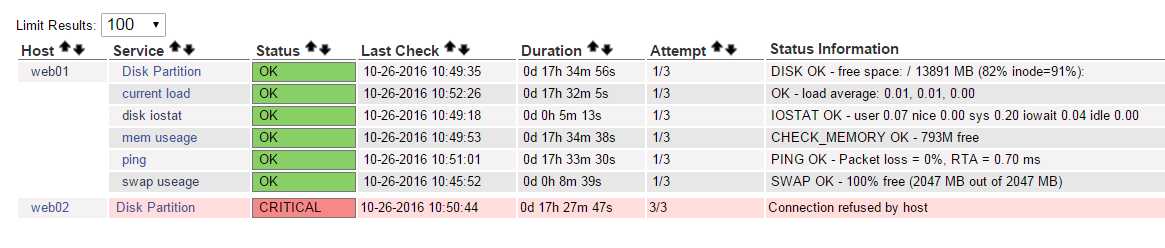
可以看到disk iostat服务ok了
5添加http服务的url地址及端口监控
url监控的是指是通过命令行理解http的监控原理,如下
[root@hd1 ~]# cd /usr/local/nagios/libexec/
[root@hd1 libexec]# ./check_http -H 192.168.1.12
下面将192.168.1.12配置成一个web服务器
[root@hd2]# yum -y install httpd
[root@hd2]# /etc/init.d/httpd start
[root@hd2]# cd /var/www/html/
[root@hd2 html]# echo "woshi 192.168.1.12" >index.html
下面对url地址进行监控,将要监控的服务配置到services.cfg中即可
define service {
use generic-service
host_name web01
service_description http_url
check_command check_http
}
配置好之后,检查nagios语法
[root@hd1 objects]# /etc/init.d/nagios checkconfig
Total Warnings: 0
Total Errors: 0
重新加载配置文件
[root@hd1 objects]# /etc/init.d/nagios reload
此时,可以看到自己配置的url监控成果了
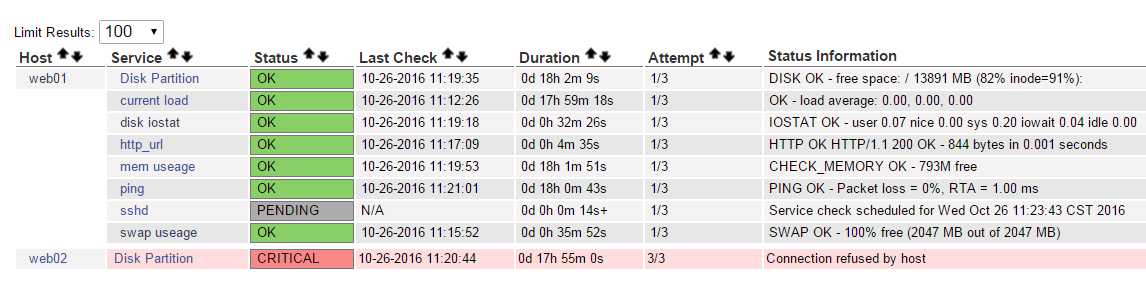
7.监控任意tcp udp端口举例
端口监控的实质就是执行如下命令去监控
ip 协议 网络层 三层
tcp协议,传输控制协议,四层,稳定的协议,打电话
upd 协议,四层,用户数据报协议,短消息qq
http 应用层的协议 check_http check_tcp 80

我们把22端口号添加进去进行监控
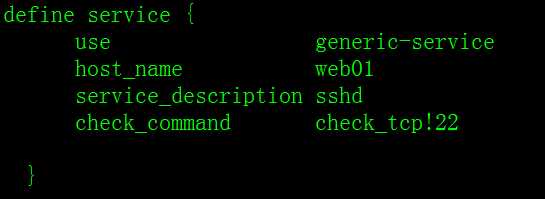
define service {
use generic-service
host_name web01
service_description sshd
check_command check_tcp!22
}
[root@hd1 objects]# /etc/init.d/nagios reload
Running configuration check...done.
Reloading nagios configuration...done
这里的check_tcp为nagios plugin默认插件,commands.cfg会自动配置进去,不需要添加
端口检查也是很不错的辅助监控方式
小结:
主动模式的监控配置过程如下:
1)在服务器端的命令行把要监控的命令先调试好
2)在commands.cfg里定义nagios命令,同时调用命令行的插件
3)在服务的配置文件里定义要监控的服务,调用commands.cfg里定义的nagios的监控命令
4)如果我们在服务器端写了一个脚本,必须在commands.cfg定义
5)如果我们在客户端写了一个脚本,必须在客户端的nrpe.cfg里定义命令
14.6 服务器端nagios图形监控显示和管理
14.6.1 服务器端安装pnp生成图形监控曲线
1.pnp出图基础依赖软件安装
先通过下面的命令安装pnp软件需要的基础包
[root@hd1 ~]# yum -y install cairo pango zlib zlib-devel freetype freetype-devel gd gd-devel
然后安装rrdtool依赖的libart_lgpl相关软件包,这个软件包要优于rrdtool安装
[root@hd1 ~]# yum install libart_lgpl libart_lgpl-devel -y
png工具最终是通过rrdtool实现的画图,因此需要提前安装rrdtool
root@hd1 ~]# yum install rrdtool -y
2.安装出图web界面展示软件pnp
此处选择0.4.14的pnp版本,如果选择高版本在出图方面可能会有坑,正常情况下,选0.4版已经足够了
[root@hd1 ~]# yum -y install perl-Time-HiRes
[root@hd1 ~]# tar zxf pnp-0.4.13.tar.gz
[root@hd1 ~]# cd pnp-0.4.13
[root@hd1 pnp-0.4.13]# ./configure \
> --with-rrdtool \
> --with-perfdata-dir=/usr/local/nagios/share/perfdata/
[root@hd1 pnp-0.4.13]# make all
[root@hd1 pnp-0.4.13]# make install
[root@hd1 pnp-0.4.13]# make install-config
[root@hd1 pnp-0.4.13]# make install-init
[root@hd1 pnp-0.4.13]# ls /usr/local/nagios/libexec/|grep process
process_perfdata.pl
pnp提供了一个获取数据出图的perl脚本,可以用如下命令查到,
[root@hd1 pnp-0.4.13]# ll /usr/local/nagios/libexec/|grep process
-rwxr-xr-x. 1 nagios nagios 30138 Oct 27 10:33 process_perfdata.pl
此时打开浏览器访问http://192.168.1.11/nagios/pnp 会出现下图所示
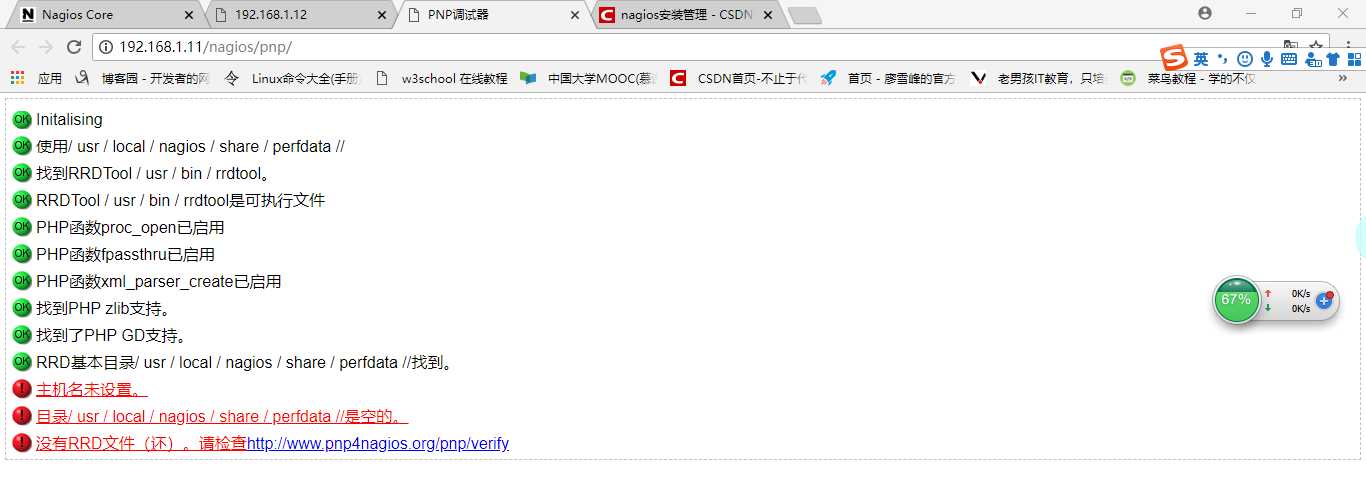
过一会儿重新访问上述地址就会恢复正常
如果过了很长时间还是现实不正常,可以执行如下命令
[root@hd1 pnp-0.4.13]# yum install -y php-gd
[root@hd1 pnp-0.4.13]# yum install -y gd
[root@hd1 pnp-0.4.13]# rpm -ivh /root/gd-devel-2.0.35-11.el6.x86_64.rpm
3.nagios出图相关配置
1)执行编辑命令 ‘vi /usr/local/nagios/etc/nagios.cfg +835’ ,修改主配置文件835行,将如下参数对应的值从0改为1 ,表示记录数据

大概从848行开始,找到如下两项,取消参数开头的注释,修改后的最终结果如下:

2)执行编辑命令 ‘vi /usr/loca/nagios/etc/objects/commands.cfg +227’ ,修改commands.cfg命令配置文件,定义出图获取数据的命令
要修改的是commands.cfg配置文件的第227-238行,默认的配置如下
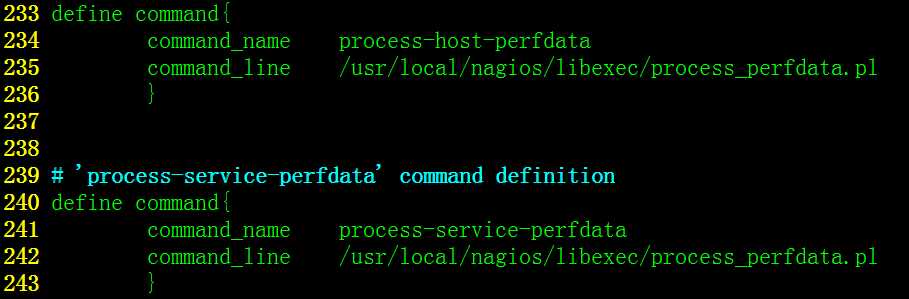
define command{
command_name process-host-perfdata
command_line /usr/local/nagios/libexec/process_perfdata.pl
}
# ‘process-service-perfdata‘ command definition
define command{
command_name process-service-perfdata
command_line /usr/local/nagios/libexec/process_perfdata.pl
}
重启配置文件
[root@hd1 ~]# /etc/init.d/nagios reload
Running configuration check...done.
Reloading nagios configuration...done
4)此时在浏览器输入’http://192.168.1.11/nagios/pnp/index.php’打开页面,正确的pnp界面如下
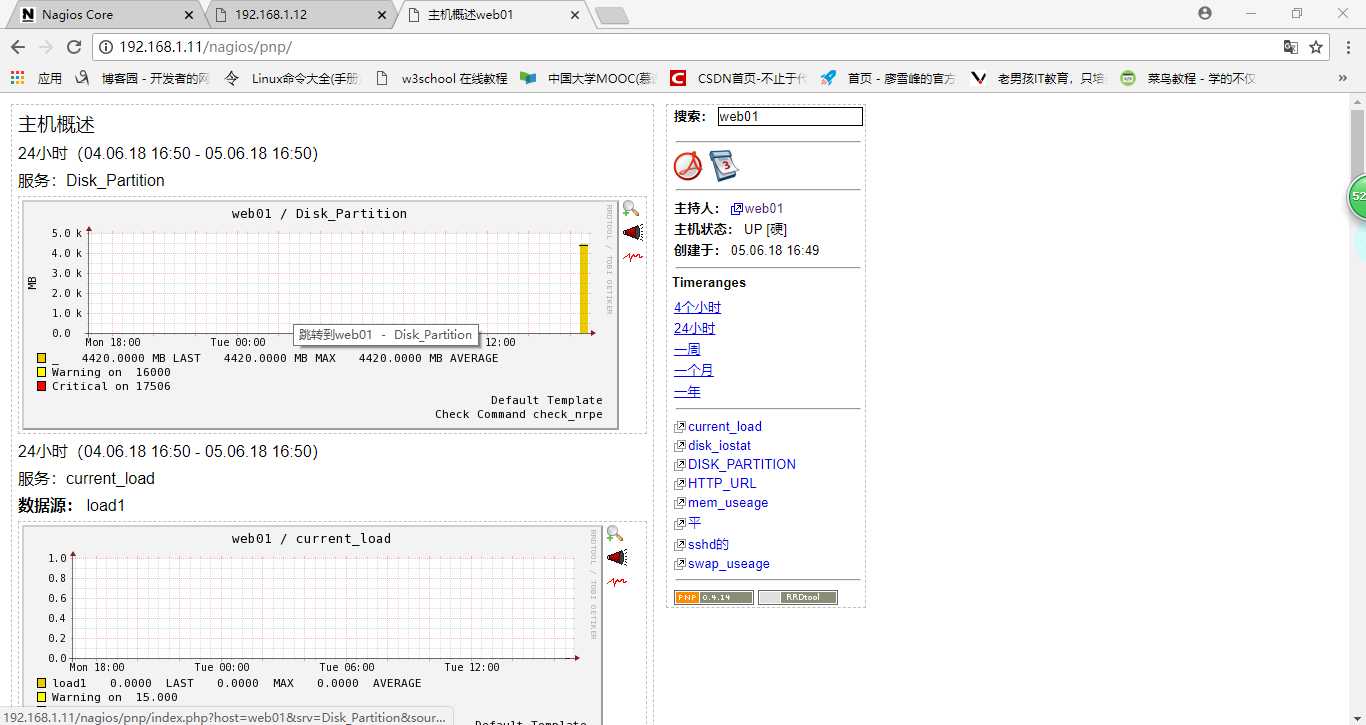
到这里为止,pnp软件的出图就ok了,但是还没有业务数据的图形趋势,因为还没有配置呢,接下去就来配置
14.6.2 配置主机及服务获取状态数据出图
1.设置让被监控的主机记录数据
如果要让所有的主机获取数据并出趋势图,则需编辑nagios的主机hosts.cfg文件,
不过,只要在每一个被监控主机的配置下面增加同一个参数项 ‘process_perf_data 1’
即可
[root@hd1 ~]# cd /usr/local/nagios/etc/objects/
[root@hd1 objects]# vi hosts.cfg
# Define a host for the local machine
define host{
use linux-server
host_name web01
alias web01
address 192.168.1.12
process_perf_data 1
}
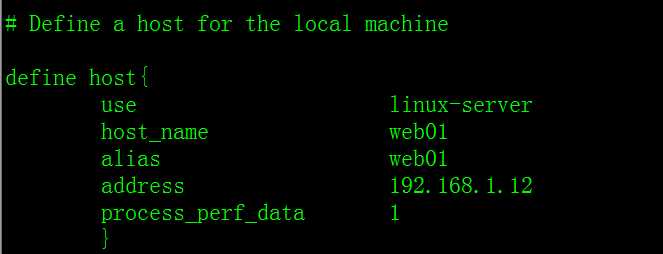
2.设置让被监控主机对应的服务记录数据
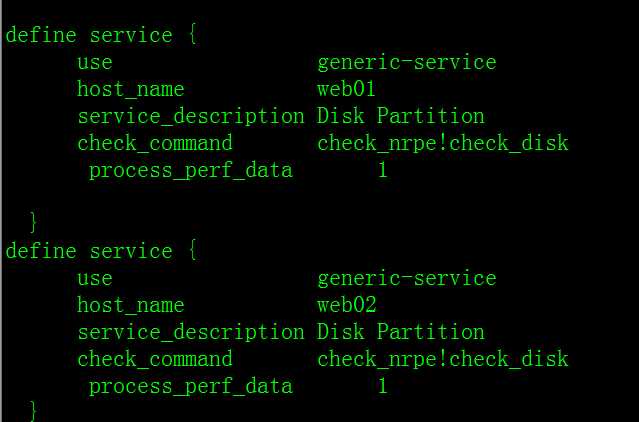
[root@hd1 objects]# vim services.cfg
define service {
use generic-service
host_name web01
service_description Disk Partition
check_command check_nrpe!check_disk
process_perf_data 1
}
define service {
use generic-service
host_name web02
service_description Disk Partition
check_command check_nrpe!check_disk
process_perf_data 1
}
如何批量插入一行呢?
[root@hd1 objects]# sed -i "/check_command/a process_perf_data 1 " services.cfg
[root@hd1 objects]# sed -i "s#,,,# #" services.cfg
还可以对采取对所有服务对应的统一模板里添加配置参数的方式
服务里的use generic-service 已经配置了
[root@hd1 objects]# sed -n ‘154,177p‘ templates.cfg
name generic-service
failure_prediction_enabled 1
process_perf_data 1
重启nagios服务
[root@hd1 objects]# /etc/init.d/nagios reload
Running configuration check...done.
Reloading nagios configuration...done
到此,如果等一段时间,然后查看pnp url就可以发现生成了图形数据,有些数据需要压测或者真实环境才能看
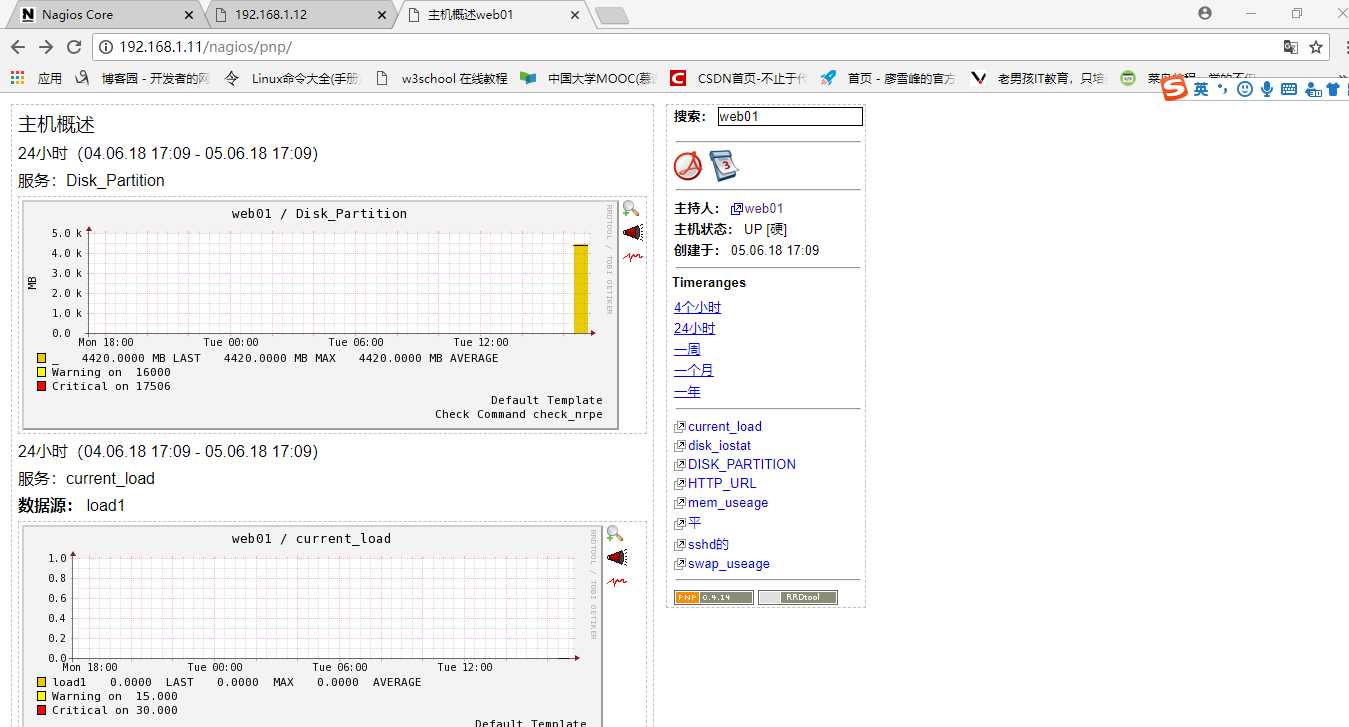
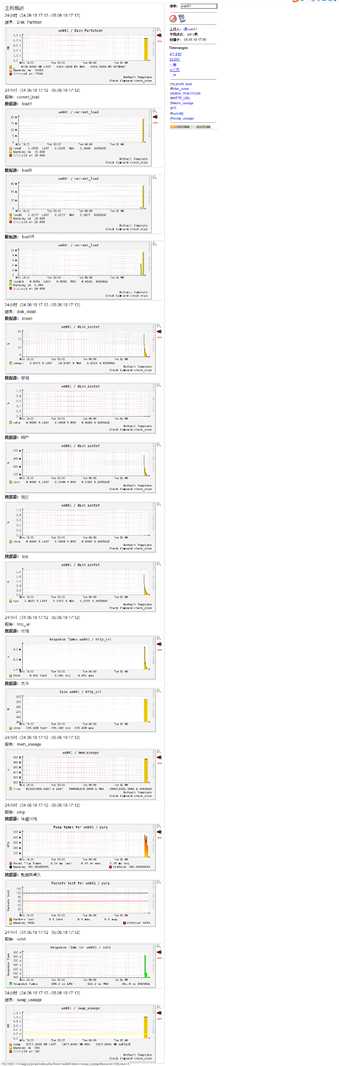
14.6.3 整合pnp url超链接到nagios web界面
1.给被监控的所有主机添加超链接图标
[root@hd1 objects]# vim hosts.cfg
define host{
use linux-server
host_name web01
alias web01
address 192.168.1.12
process_perf_data 1
action_url /nagios/pnp/index.php?host=$HOSTNAME$
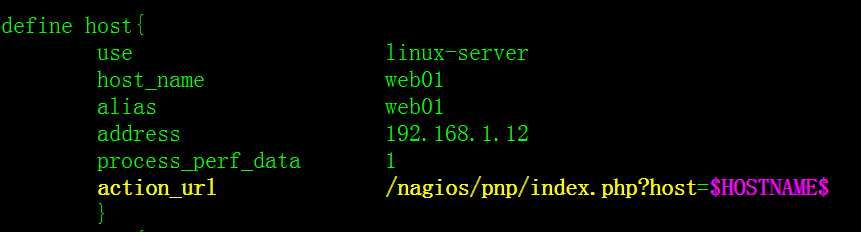
2.给被监控的主机指定的服务添加超链接图标
删除空行 : sed ‘/^$/d‘ services.cfg
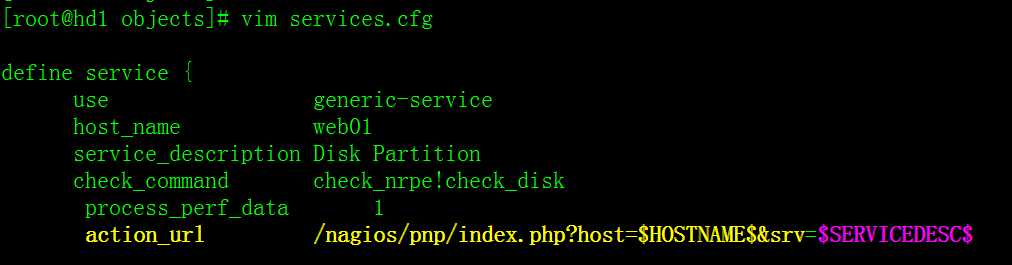
重新加载配置
[root@hd1 objects]# /etc/init.d/nagios reload
测试一下
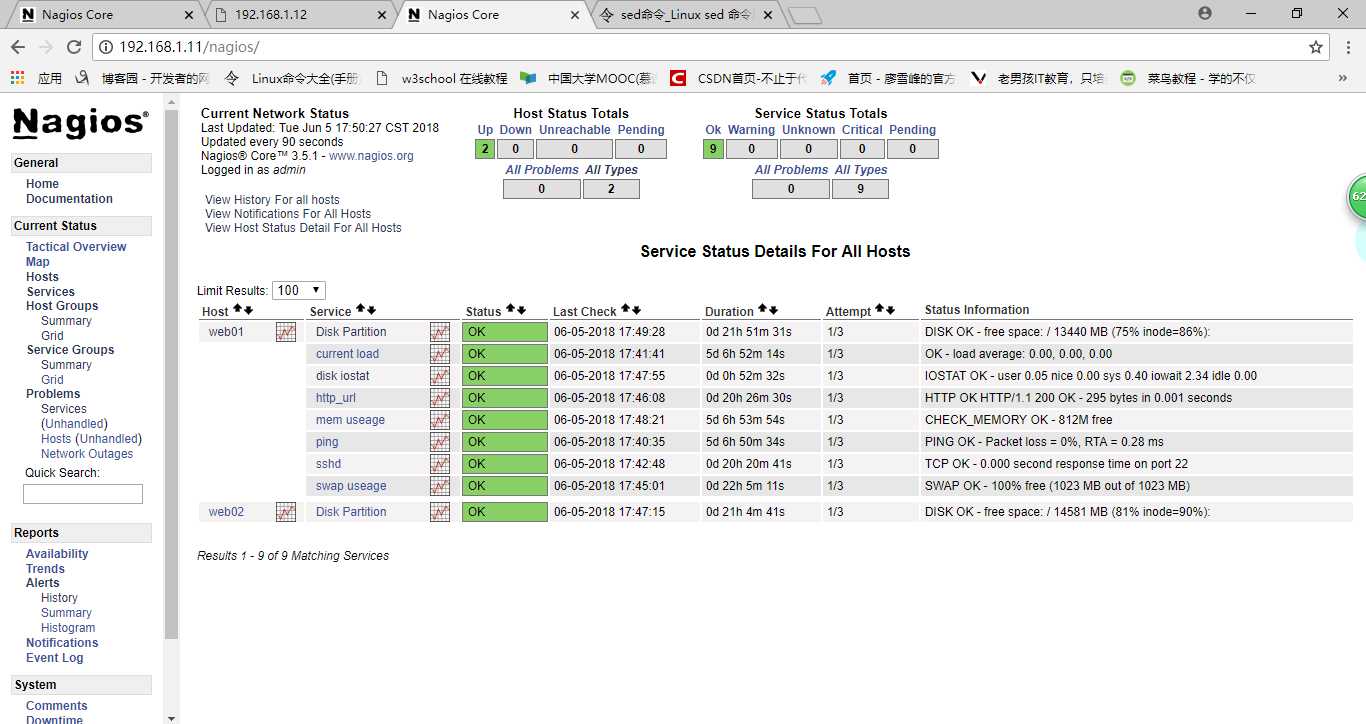
14.7 实现对nagios故障报警给管理员
将要nagios故障报警给管理员时,常用的方式包括邮件报警和手机报警,下面分别介绍
1.邮件报警
普通邮件报警就是在故障发生或恢复时,将报警信息发到系统管理员或相关维护人的信箱中,最好是公司内部邮箱。
定义收邮件的邮箱
[root@hd1 ~]# vim /usr/local/nagios/etc/objects/contacts.cfg
常见的发送邮件的方法有两种 ,一种是启动本机的邮件服务postfix ,另外一种是使用网上第三方邮件服务提供商的服务,例如:qq邮件服务或网易邮件服务
法1的配置
[root@hd1 nagios]# /etc/init.d/postfix restart
Shutting down postfix: [ OK ]
Starting postfix: [ OK ]
[root@hd1 nagios]# lsof -i :25
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
master 32807 root 12u IPv4 57932 0t0 TCP localhost:smtp (LISTEN)
master 32807 root 13u IPv6 57934 0t0 TCP localhost:smtp (LISTEN)
如果postfix启动比较慢,可以修改/etc/hosts做好本机ip和主机名的映射
提示:此环境下由于没有外网ip,并且邮件服务没有做好mx记录及反向解析,因此,邮件经常会收不到,或者当做垃圾邮件
法二:使用网上第三方邮件服务提供商比如163的邮箱
注意:这里的163邮箱作为报警的发件人,相当于htf1304@163.com 用户登录邮箱,然后给人发信,收件人就是在contact.cfg里定义的
[root@hd1 ~]# vim /etc/mail.rc

[root@hd1 nagios]# /etc/init.d/postfix restart
在这里说一下有些运营商 可以开启邮件短信提醒也比较方便
14.8 nagios插件开发
14.8.1 概述
1.什么是nagios插件
前文在部署nagios服务时已经安装了nagios-plugins-1.4.6.tar.gz这个软件包就是nagios插件安装包
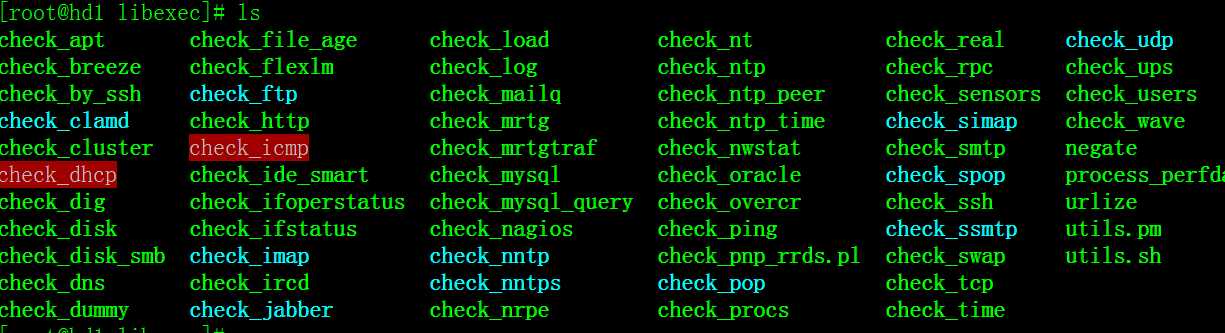
可以看到有很多插件,其实,nagios软件本身仅仅是一个监控的平台,如果要监控具体的主机及服务的状态和数据信息,还必须配置或调用插件或程序文件才能完成任务,因此,如果没有插件,nagios就是一个空壳,什么都做不了
2.为什么要开发nagios插件
大部分服务都不需要开发插件,但有部分我们要监控的服务,是nagios里没有插件,需要我们自己开发编写脚本
14.8.2 编写nagios插件的规则
1.编写nagios插件说明
nagios插件是nagios提供的一种通过可扩展的方式部署的程序组件,该插件可通过shell、java、c++、php、python等多种开发语言开发,运维或系统架构人员只要通过修改nagios配置文件和相应的参数,就能很方便地将该插件集成到nagios中,实现对目标系统的监控
nagios服务为插件程序提供了两个返回值接口和插件交互:一个是插件执行后的退出状态码,另一个是插件执行过程中在控制台打印的第一行数据,退出状态码可以被nagios主程序作为判断被监控系统服务状态的依据,控制台打印的第一行数可以被nagios主程序作为被监控系统服务状态的补充说明,会显示在web管理界面里
注意:如果是一个主动监控插件,需要放在nagios服务器端/usr/local/nagios/liexec,并且需要在commands.cfg文件中定义本插件,然后需要在services.cfg 中添加一个新的监控服务,在这个服务里,调用这个插件,如果是一个被动监控插件,需要放在nagios客户端/usr/local/nagios/liexec,并且需要在客户端的nrpe.cfg里定义这个插件,然后需要在nagios服务器端services.cfg 里添加一个新的监控服务,并且在这个服务里,调用这个插件,注意调用的时候,别忘了前面有check_nrpe!chanjian
退出状态码和说明如下:
ok 退出代码,0表示服务工作正常
warning 退出代码,1表示服务处于警告状态
critical 退出代码,2表示服务处于紧急、严重状态
unknown 退出状态码,3表示服务出于未知状态
[root@hd1 libexec]# head -7 utils.sh
#! /bin/sh
STATE_OK=0
STATE_WARNING=1
STATE_CRITICAL=2
STATE_UNKNOWN=3
STATE_DEPENDENT=4
2.nagios插件开发原理
nagios插件程序中需要调用监控服务规定的操作序列,并根据预选定义的规则,对返回结果进行分析,判断服务的当前状态,然后以指定的状态码退出程序,同时将对该状态的说明不换行输出到控制台
14.8.3 使用shell开发nagios插件
1.编写检查webrul地址的插件
[root@hd1 libexec]# cat check_url.sh
#!/bin/sh
#get the shell script name
progname=`basename $0`
#get the file path
progpath=`dirname $0`
usage() {
echo "usage: /bin/sh $progname url"
exit 1
}
#
[ $# -ne 1 ] && usage
wget -T 10 --spider $1 >/dev/null 2>&1
#此处解释 wget命令
#-T, --timeout=SECONDS设定读取时超过的时间为SECONDS秒.
#-t 设置重试次数。当连接中断(或超时)时,wget将试图重新连接。如果指定-t0,则重#试次数设为无穷多。
#-c指定断点续传功能。实际上,wget默认具有断点续传功能,只有当你使用别的ftp工具#下载了某一文件的一部分,并希望wget接着完成此工作的时候,才需要指定此参数。
if [ $? -eq 0 ]
then
echo "url $1 ok "
exit 0
else
echo "url $1 critical"
exit 2
fi
上述脚本中 basename、dirname是系统命令
[root@hd1 libexec]# basename /usr/local/nagios/libexec
libexec
[root@hd1 libexec]# dirname /usr/local/nagios/libexec
/usr/local/nagios
测试一下webrul插件脚本
[root@hd1 libexec]# sh check_url.sh 192.168.1.12
url 192.168.1.12 ok
2.weburl插件脚本部署过程
1)将check_url.sh放到/usr/local/nagios/libexec中,并授权为可执行
[root@hd1 libexec]# chmod +x check_url.sh
2)在command.cfg建立check_url命令;

3)在services.cfg里添加监控上述url地址的服务
define service {
use generic-service
host_name web01
service_description http_zhudong_url
check_command check_url
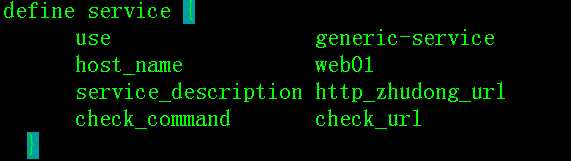
4.重新加载nagios ,查看结果
[root@hd1 objects]# /etc/init.d/nagios reload
Running configuration check...done.
Reloading nagios configuration...done
5.重新查看nagios服务页面的监控结果

注意:此次属于主动监控的方式,所以可以停掉客户端的nrpe进程
3.利用被动模式的nrpe方式监控/etc/passwd 文件是否变化
nagios被动模式下的所有插件都需要部署在被监控的nagios客户端,部署步骤如下:
1)在nagios客户端web01 上取/etc/passwd的文件指纹,即md5值
[root@hd2 ~]# md5sum /etc/passwd >/root/ps.md5
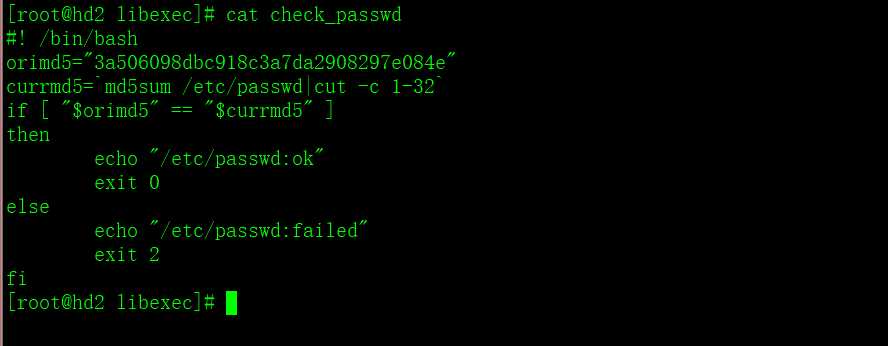
2)在nagios客户端上web01上开发插件脚本,并测试
[root@hd2 libexec]# cat check_passwd
#!/bin/bash
orimd5="f7e63f1940dba72443afc319dfadc7f6"
currmd5=`md5sum /etc/passwd|cut -c 1-32`
if [ "$orimd5" == "$currmd5" ]
then
echo "/etc/passwd:ok"
exit 0
else
echo "/etc/passwd:failed"
exit 2
fi
测试脚本
[root@hd2 libexec]# sh check_passwd
/etc/passwd:ok
给脚本权限
[root@hd2 libexec]# chmod +x check_passwd
1)在nagios客户端web01上编辑nrpe.cfg,插入如下的内容后保存
command[check_passwd]=/usr/local/nagios/libexec/check_passwd

4)在nagios客户端上重启nrpe,并检查是否重启成功
[root@hd2 etc]# /usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d
[root@hd2 etc]# ps -ef|grep nrpe|grep -v grep
nagios 126175 1 0 09:00 ? 00:00:00 /usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d
5)在nagios服务器端上上进入services.cfg 文件添加如下集行内容
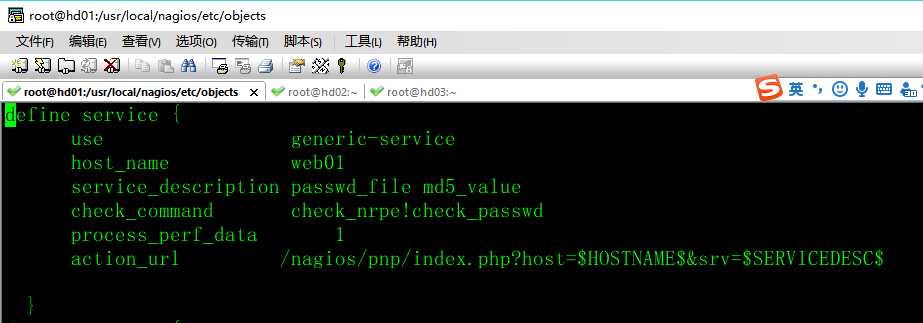
6)在nagios服务端检查语法并重启服务
[root@hd1 objects]# /etc/init.d/nagios reload
Running configuration check...done.
Reloading nagios configuration...done
7)进入服务器端的/usr/local/nagios/libexec 目录,手动测试

8)在客户端进行测试

9)通过页面进行检查
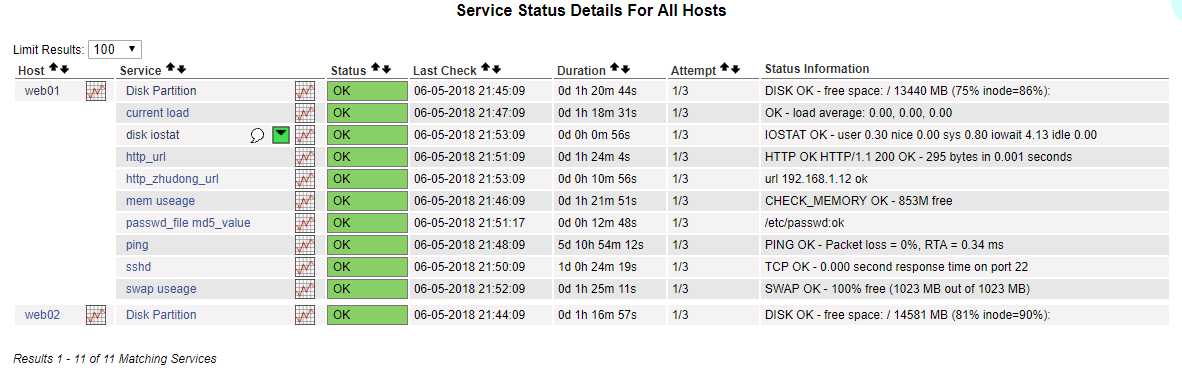
到此,nagios结束了。
常见问题
1.出现nrpe:unable to read output
可能是:客户端对应插件命令不存在或者无执行权限等原因导致
2.出现nrpe:command ·check_passwd· not defined 类似的问题
可能是:服务器端的服务里配置的命令与客户端的nrpe.cfg里配置的命令名不匹配导致的
开发一个主动监控的插件
1.在libexec下编写插件并给执行权限
[root@hd1 libexec]# cat check_htf_ping
#! /bin/bash
ping 192.168.1.12 -c 4 >/dev/null 2>&1
if [ $? -eq 0 ]
then
echo "web01 is online"
else
echo "web01 no online"
fi
[root@hd1 libexec]# chmod 755 check_htf_ping
2.在commands.cfg 定义插件命令
[root@hd1 libexec]# cat ../etc/objects/commands.cfg
# ‘check_ping‘ command definition
define command{
command_name check_htf_ping
command_line $USER1$/check_htf_ping
}
3.在services.cfg里配置服务,调用这个插件
[root@hd1 libexec]# cat ../etc/objects/services.cfg
define service {
use generic-service
host_name web01
service_description ping 192.168.1.12
check_command check_htf_ping
process_perf_data 1
action_url /nagios/pnp/index.php?host=$HOSTNAME$&srv=$SERVICEDESC$
}
4.重启服务,去浏览器上查看并验证
[root@hd1 libexec]# /etc/init.d/nagios restart

编写一个被动插件,监控客户端的/dev/sda3分区的如果磁盘占用率超过7%报警exit 1
如果不大于7%不报警,exit 0
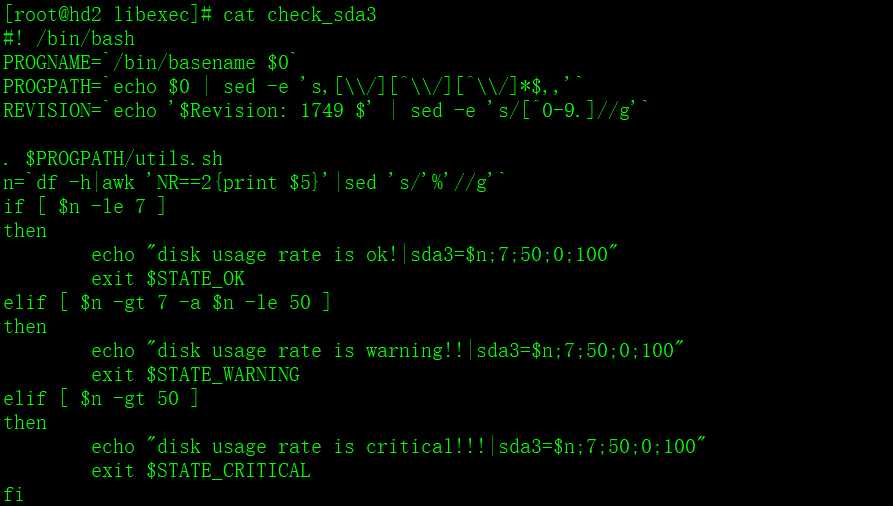
在web01 的nrpe.cfg 中添加一行
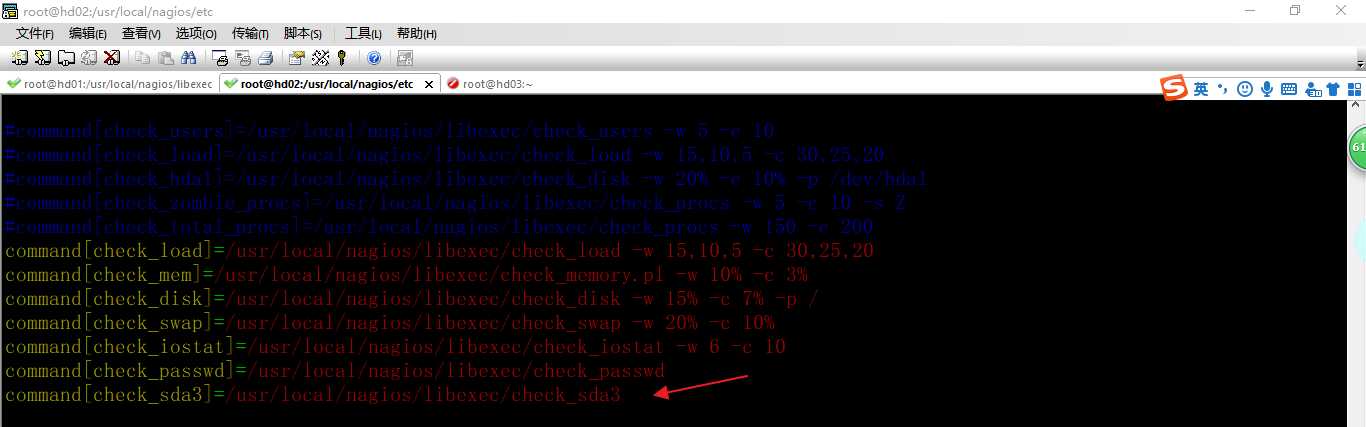
然后重启 nrpe
在服务器端 services.cfg中添加
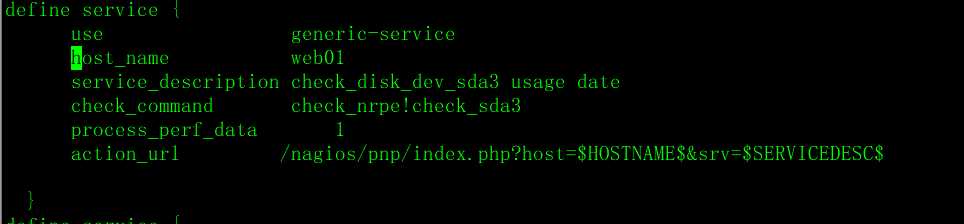
然后重新加载nagios
/etc/init.d/nagios reload
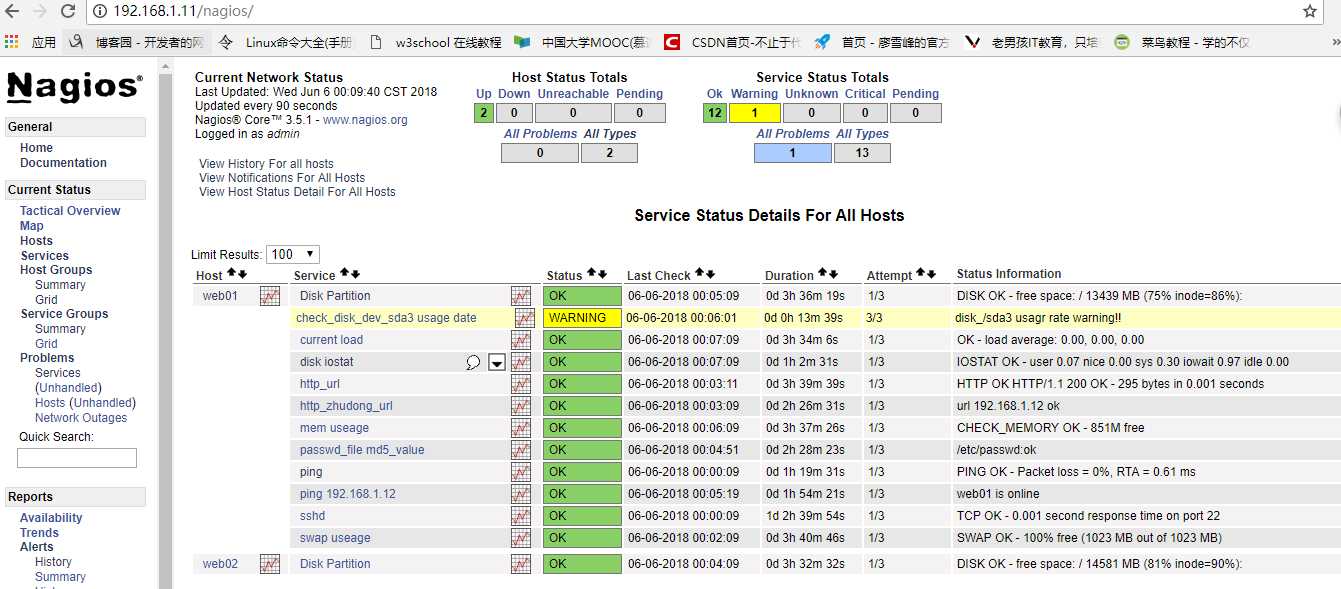
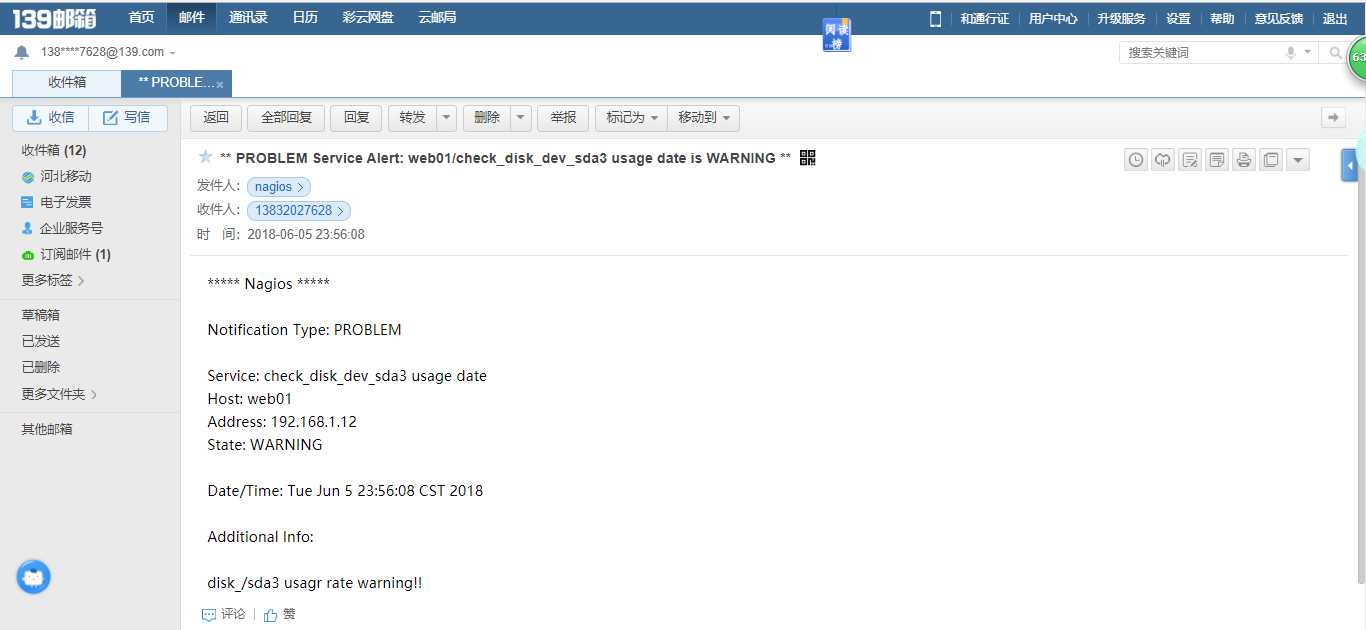

收到邮件也受到了短信通知 服务搭建ok!!
提示:
ok 退出代码,0表示服务工作正常
warning 退出代码,1表示服务处于警告状态
critical 退出代码,2表示服务处于紧急、严重状态
如果有什么不太好解决的问题,建议大家多分析系统日志。
/var/log/messages
标签:apr 安装nagios cin bak 指定 tin 联系人 tar user
原文地址:https://www.cnblogs.com/xh-blog/p/9643507.html