标签:erp 等价 经历 还需要 windows normal ddr cto 初始
这一章将了解如何在DirectX 11利用硬件实例化技术高效地绘制重复的物体,以及使用视锥体裁剪技术提前将位于视锥体外的物体进行排除。
在此之前需要额外了解的章节如下:
| 章节回顾 |
|---|
| 18 使用DirectXCollision库进行碰撞检测 |
| 19 模型加载:obj格式的读取及使用二进制文件提升读取效率 |
DirectX11 With Windows SDK完整目录
硬件实例化指的是在场景中绘制同一个物体多次,但是是以不同的位置、旋转、缩放、材质以及纹理来绘制(比如一棵树可能会被多次使用以构建出一片森林)。在以前,每次实例绘制(Draw方法)都会引发一次顶点缓冲区和索引缓冲区经过输入装配阶段传递进渲染管线中,大量重复的绘制则意味着多次反复的输入装配操作,会引发十分庞大的性能开销。事实上在绘制同样物体的时候顶点缓冲区和索引缓冲区应当只需要传递一次,然后真正需要多次传递的也应该是像世界矩阵、材质、纹理等这些可能会经常变化的数据。
要能够实现上面的这种操作,还需要图形库底层API本身能够支持按对象绘制。对于每个对象,我们必须设置它们各自的材质、世界矩阵等,然后才是调用绘制命令。尽管在Direct3D 10和后续的版本已经将原本Direct3D 9的一些API重新设计以尽可能最小化性能上的开销,部分多余的开销仍然存在。因此,Direct3D提供了一种机制,不需要通过API上的额外性能开销来实现实例化,我们称之为硬件实例化。
为什么要担忧API性能开销呢?Direct3D 9应用程序通常因为API导致在CPU上遇到瓶颈,而不是在GPU。以前关卡设计师喜欢使用单一材质和纹理来绘制许多对象,因为对于它们来说需要经常去单独改变它的状态并且去调用绘制。场景将会被限制在几千次的调用绘制以维持实时渲染的速度,主要在于这里的每次API调用都会引起高级别的CPU性能开销。现在图形引擎可以使用批处理技术以最小化绘制调用的次数。硬件实例化是API帮助执行批处理的一个方面。
硬件实例化需要在输入装配阶段额外提供以二进制数据流表示的实例数据才能工作,而不仅仅是提供顶点/索引数据。然后我们将通过调用对应的Draw命令来告诉硬件需要绘制这个网格模型多少次,即绘制多少个这样的实例。对应顶点着色器来说,可以同时接受来自顶点信息和实例信息的数据作为输入:
struct InstancePosNormalTex
{
float3 PosL : POSITION;
float3 NormalL : NORMAL;
float2 Tex : TEXCOORD;
row_major matrix World : World;
row_major matrix WorldInvTranspose : WorldInvTranspose;
};
其中前面三项数据来自顶点,后面两项数据则是来自一个实例,因为对于一个实例来说,在绘制的时候它的世界矩阵是不会发生变化的。
输出的结构体和以前一样:
struct VertexPosHWNormalTex
{
float4 PosH : SV_POSITION;
float3 PosW : POSITION; // 在世界中的位置
float3 NormalW : NORMAL; // 法向量在世界中的方向
float2 Tex : TEXCOORD;
};顶点着色器代码变化如下:
VertexPosHWNormalTex VS(InstancePosNormalTex pIn)
{
VertexPosHWNormalTex pOut;
row_major matrix viewProj = mul(gView, gProj);
pOut.PosW = mul(float4(pIn.PosL, 1.0f), pIn.World).xyz;
pOut.PosH = mul(float4(pOut.PosW, 1.0f), viewProj);
pOut.NormalW = mul(pIn.NormalL, (float3x3) pIn.WorldInvTranspose);
pOut.Tex = pIn.Tex;
return pOut;
}至于像素着色器,和上一章为模型所使用的着色器的保持一致。
系统值SV_InstanceID可以告诉我们当前进行绘制的顶点来自哪个实例。通常在绘制N个实例的情况下,第一个实例的索引值为0,一直到最后一个实例索引值为N - 1.它可以应用在需要个性化的地方,比如使用一个纹理数组,然后不同的索引去映射到对应的纹理,以绘制出网格模型相同,但纹理不一致的物体。
和之前顶点着色器的做法一样,我们需要使用D3D11_INPUT_ELEMENT_DESC来描述实例的字节流对应的元素信息:
typedef struct D3D11_INPUT_ELEMENT_DESC
{
LPCSTR SemanticName; // 语义名
UINT SemanticIndex; // 语义名对应的索引值
DXGI_FORMAT Format; // DXGI数据格式
UINT InputSlot; // 输入槽
UINT AlignedByteOffset; // 对齐的字节偏移量
D3D11_INPUT_CLASSIFICATION InputSlotClass; // 输入槽类别(顶点/实例)
UINT InstanceDataStepRate; // 实例数据步进值
} D3D11_INPUT_ELEMENT_DESC;最后两个成员与实例所有联系:
1.InputSlotClass:指定输入的元素是作为顶点元素还是实例元素。枚举值含义如下:
| 枚举值 | 含义 |
|---|---|
| D3D11_INPUT_PER_VERTEX_DATA | 作为顶点元素 |
| D3D11_INPUT_PER_INSTANCE_DATA | 作为实例元素 |
2.InstanceDataStepRate:指定每份实例数据绘制出多少个实例。例如,假如你想绘制6个实例,但提供了只够绘制3个实例的数据,1份实例数据绘制出1种颜色,分别为红、绿、蓝。那么我们可以设置该成员的值为2,使得前两个实例绘制成红色,中间两个实例绘制成绿色,后两个实例绘制成蓝色。通常在绘制实例的时候我们会将该成员的值设为1,保证1份数据绘制出1个实例。对于顶点成员来说,设置该成员的值为0.
对于前面的结构体InstancePosNormalTex,与之对应的输入成员描述数组如下:
D3D11_INPUT_ELEMENT_DESC basicInstLayout[] = {
{ "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D11_INPUT_PER_VERTEX_DATA, 0 },
{ "NORMAL", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 12, D3D11_INPUT_PER_VERTEX_DATA, 0 },
{ "TEXCOORD", 0, DXGI_FORMAT_R32G32_FLOAT, 0, 24, D3D11_INPUT_PER_VERTEX_DATA, 0 },
{ "World", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 0, D3D11_INPUT_PER_INSTANCE_DATA, 1},
{ "World", 1, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 16, D3D11_INPUT_PER_INSTANCE_DATA, 1},
{ "World", 2, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 32, D3D11_INPUT_PER_INSTANCE_DATA, 1},
{ "World", 3, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 48, D3D11_INPUT_PER_INSTANCE_DATA, 1},
{ "WorldInvTranspose", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 64, D3D11_INPUT_PER_INSTANCE_DATA, 1},
{ "WorldInvTranspose", 1, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 80, D3D11_INPUT_PER_INSTANCE_DATA, 1},
{ "WorldInvTranspose", 2, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 96, D3D11_INPUT_PER_INSTANCE_DATA, 1},
{ "WorldInvTranspose", 3, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 112, D3D11_INPUT_PER_INSTANCE_DATA, 1}
};因为DXGI_FORMAT一次最多仅能够表达128位(16字节)数据,在对应矩阵的语义时,需要重复描述4次,区别在于语义索引为0-3.
除此之外,观察到有关顶点的数据占用输入槽0,而实例数据占用的则是输入槽1.这样就需要我们使用两个缓冲区以提供给输入装配阶段。第一个作为顶点缓冲区,而第二个作为实例缓冲区以存放有关实例的数据。
struct VertexPosNormalColor
{
DirectX::XMFLOAT3 pos;
DirectX::XMFLOAT3 normal;
DirectX::XMFLOAT4 color;
static const D3D11_INPUT_ELEMENT_DESC inputLayout[3];
};
struct InstancedData
{
XMMATRIX world;
XMMATRIX worldInvTranspose;
};
// ...
UINT strides[2] = { sizeof(VertexPosNormalTex), sizeof(InstancedData) };
UINT offsets[2] = { 0, 0 };
ID3D11Buffer * buffers[2] = { vertexBuffer.Get(), mInstancedBuffer.Get() };
// 设置顶点/索引缓冲区
deviceContext->IASetVertexBuffers(0, 2, buffers, strides, offsets);
deviceContext->IASetInputLayout(instancePosNormalTexLayout.Get());
通常我们使用ID3D11DeviceContext::DrawIndexedInstanced方法来绘制实例数据:
void ID3D11DeviceContext::DrawIndexedInstanced(
UINT IndexCountPerInstance, // [In]每个实例绘制要用到的索引数目
UINT InstanceCount, // [In]绘制的实例数目
UINT StartIndexLocation, // [In]起始索引偏移值
INT BaseVertexLocation, // [In]起始顶点偏移值
UINT StartInstanceLocation // [In]起始实例偏移值
);下面是一个调用示例:
deviceContext->DrawIndexedInstanced(part.indexCount, numInsts, 0, 0, 0);若没有索引数组,也可以用ID3D11DeviceContext::DrawInstanced方法来进行绘制
void ID3D11DeviceContext::DrawInstanced(
UINT VertexCountPerInstance, // [In]每个实例绘制要用到的顶点数目
UINT InstanceCount, // [In]绘制的实例数目
UINT StartVertexLocation, // [In]起始顶点偏移值
UINT StartInstanceLocation // [In]起始实例偏移值
);和之前创建顶点/索引缓冲区的方式一样,我们需要创建一个ID3D11Buffer,只不过在缓冲区描述中,我们需要将其指定为动态缓冲区(即D3D11_BIND_VERTEX_BUFFER),并且要指定D3D11_CPU_ACCESS_WRITE。
// 设置实例缓冲区描述
D3D11_BUFFER_DESC vbd;
ZeroMemory(&vbd, sizeof(vbd));
vbd.Usage = D3D11_USAGE_DYNAMIC;
vbd.ByteWidth = count * (UINT)sizeof(XMMATRIX) * 2;
vbd.BindFlags = D3D11_BIND_VERTEX_BUFFER;
vbd.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE;
// 新建实例缓冲区
HR(device->CreateBuffer(&vbd, nullptr, mInstancedBuffer.ReleaseAndGetAddressOf()));要注意这里ByteWidth每个实例使用两个矩阵,一个世界矩阵,一个是世界矩阵求逆后的转置。
因为我们不需要访问里面的数据,因此不用添加D3D11_CPU_ACCESS_READ标记。
若需要修改实例缓冲区的内容,则需要使用ID3D11DeviceContext::Map方法将其映射到CPU内存当中。对于使用了D3D11_USAGE_DYNAMIC标签的动态缓冲区来说,在更新的时候只能使用D3D11_MAP_WRITE_DISCARD标签,而不能使用D3D11_MAP_WRITE或者D3D11_MAP_READ_WRITE标签。
将需要提交上去的实例数据存放到映射好的CPU内存区间后,使用ID3D11DeviceContext::Unmap方法将实例数据更新到显存中以应用。
D3D11_MAPPED_SUBRESOURCE mappedData;
HR(deviceContext->Map(mInstancedBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData));
InstancedData * iter = reinterpret_cast<InstancedData *>(mappedData.pData);
// 省略写入细节...
deviceContext->Unmap(mInstancedBuffer.Get(), 0);在前面的所有章节中,顶点的抛弃通常发生在光栅化阶段。这意味着如果一份模型数据的所有顶点在经过矩阵变换后都不会落在屏幕区域内的话,这些顶点数据将会经历顶点着色阶段,可能会经过曲面细分阶段和几何着色阶段,然后在光栅化阶段的时候才抛弃。让这些不会被绘制的顶点还要走过这么漫长的阶段才被抛弃,可以说是一种非常低效的行为。
视锥体裁剪,就是在将这些模型的相关数据提交给渲染管线之前,生成一个包围盒,与摄像机观察空间的视锥体进行碰撞检测。若为相交或者包含,则说明该模型对象是可见的,需要被绘制出来,反之则应当拒绝对该对象的绘制调用,或者不传入该实例对象相关的数据。这样做可以节省GPU资源以避免大量对不可见对象的绘制,对CPU的性能开销也不大。
可以说,若一个场景中的模型数目越多,或者视锥体的可视范围越小,那么视锥体裁剪的效益越大。
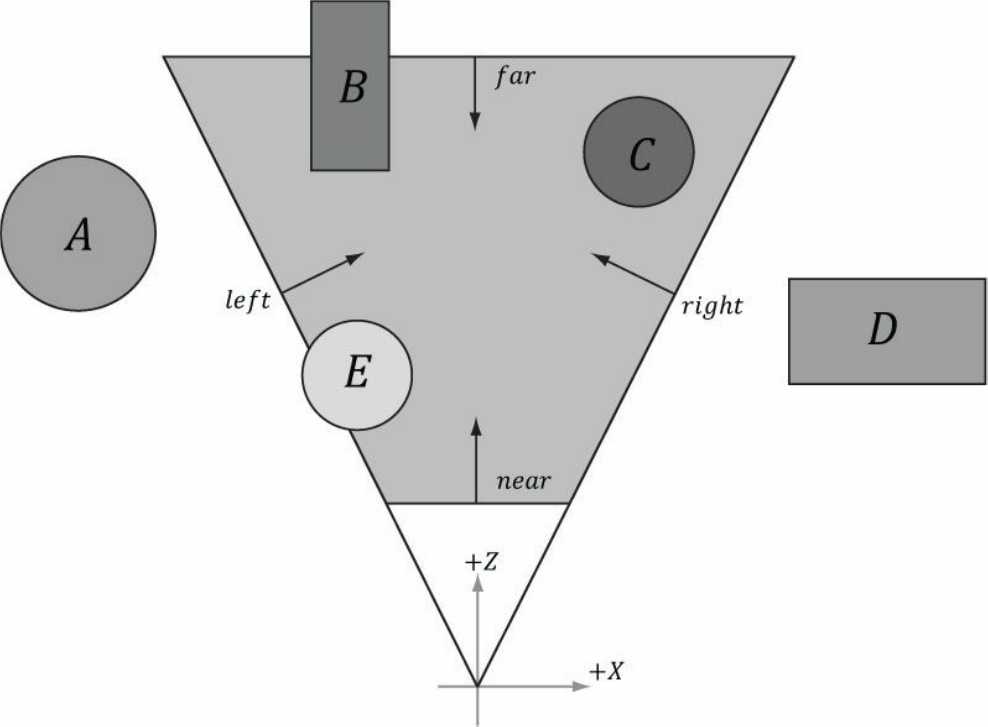
查看上图,可以知道的是物体A和D没有与视锥体发生碰撞,因此需要排除掉物体A的实例数据。而物体B和E与视锥体有相交,物体C则被视锥体所包含,这三个物体的实例数据都应当传递给实例缓冲区。
视锥体裁剪有三种等价的代码表现形式。需要已知当前物体的包围盒、世界变换矩阵、观察矩阵和投影矩阵。其中投影矩阵本身可以构造出视锥体包围盒。
下面有关视锥体裁剪的方法都放进了Collision.h中。
现在已知物体的包围盒位于自身的局部坐标系,我们可以使用世界变换矩阵将其变换到世界空间中。同样,由投影矩阵构造出来的视锥体包围盒也位于自身局部坐标系中,而观察矩阵实质上是从世界矩阵变换到视锥体所处的局部坐标系中。因此,我们可以使用观察矩阵的逆矩阵,将视锥体包围盒也变换到世界空间中。这样就好似物体与视锥体都位于世界空间中,可以进行碰撞检测了:
std::vector<XMMATRIX> XM_CALLCONV Collision::FrustumCulling(
const std::vector<XMMATRIX>& Matrices,const BoundingBox& localBox, FXMMATRIX View, CXMMATRIX Proj)
{
std::vector<DirectX::XMMATRIX> acceptedData;
BoundingFrustum frustum;
BoundingFrustum::CreateFromMatrix(frustum, Proj);
XMMATRIX InvView = XMMatrixInverse(nullptr, View);
// 将视锥体从局部坐标系变换到世界坐标系中
frustum.Transform(frustum, InvView);
BoundingOrientedBox localOrientedBox, orientedBox;
BoundingOrientedBox::CreateFromBoundingBox(localOrientedBox, localBox);
for (auto& mat : Matrices)
{
// 将有向包围盒从局部坐标系变换到世界坐标系中
localOrientedBox.Transform(orientedBox, mat);
// 相交检测
if (frustum.Intersects(orientedBox))
acceptedData.push_back(mat);
}
return acceptedData;
}
该方法对应的正是龙书中所使用的裁剪方法,基本思路为:分别对观察矩阵和世界变换矩阵求逆,然后使用观察逆矩阵将视锥体从自身坐标系搬移到世界坐标系,再使用世界变换的逆矩阵将其从世界坐标系搬移到物体自身坐标系来与物体进行碰撞检测。改良龙书的碰撞检测代码如下:
std::vector<DirectX::XMMATRIX> XM_CALLCONV Collision::FrustumCulling2(
const std::vector<DirectX::XMMATRIX>& Matrices,const DirectX::BoundingBox& localBox, DirectX::FXMMATRIX View, DirectX::CXMMATRIX Proj)
{
std::vector<DirectX::XMMATRIX> acceptedData;
BoundingFrustum frustum, localFrustum;
BoundingFrustum::CreateFromMatrix(frustum, Proj);
XMMATRIX InvView = XMMatrixInverse(nullptr, View);
for (auto& mat : Matrices)
{
XMMATRIX InvWorld = XMMatrixInverse(nullptr, mat);
// 将视锥体从观察坐标系(或局部坐标系)变换到物体所在的局部坐标系中
frustum.Transform(localFrustum, InvView * InvWorld);
// 相交检测
if (localFrustum.Intersects(localBox))
acceptedData.push_back(mat);
}
return acceptedData;
}这个方法理解起来也比较简单,直接将物体先用世界变换矩阵从物体自身坐标系搬移到世界坐标系,然后用观察矩阵将其搬移到视锥体自身的局部坐标系来与视锥体进行碰撞检测。代码如下:
std::vector<DirectX::XMMATRIX> XM_CALLCONV Collision::FrustumCulling3(
const std::vector<DirectX::XMMATRIX>& Matrices,const DirectX::BoundingBox& localBox, DirectX::FXMMATRIX View, DirectX::CXMMATRIX Proj)
{
std::vector<DirectX::XMMATRIX> acceptedData;
BoundingFrustum frustum;
BoundingFrustum::CreateFromMatrix(frustum, Proj);
BoundingOrientedBox localOrientedBox, orientedBox;
BoundingOrientedBox::CreateFromBoundingBox(localOrientedBox, localBox);
for (auto& mat : Matrices)
{
// 将有向包围盒从局部坐标系变换到视锥体所在的局部坐标系(观察坐标系)中
localOrientedBox.Transform(orientedBox, mat * View);
// 相交检测
if (frustum.Intersects(orientedBox))
acceptedData.push_back(mat);
}
return acceptedData;
}这三种方法的裁剪表现效果是一致的。
该方法创建了树的模型,并以随机的方式在一个大范围的圆形区域中生成了225棵树,即225个实例的数据(世界矩阵)。其中该圆形区域被划分成16个扇形区域,每个扇形划分成4个面,距离中心越远的扇面生成的树越多。
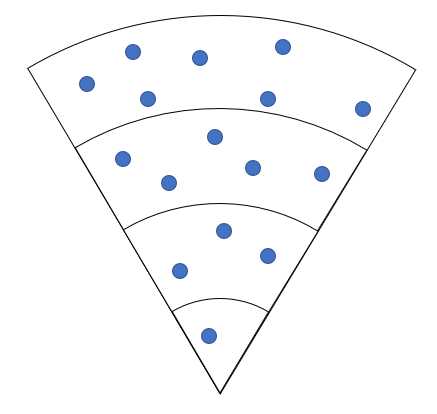
void GameApp::CreateRandomTrees()
{
// 初始化树
mObjReader.Read(L"Model\\tree.mbo", L"Model\\tree.obj");
mTrees.SetModel(Model(md3dDevice, mObjReader));
XMMATRIX S = XMMatrixScaling(0.015f, 0.015f, 0.015f);
BoundingBox treeBox = mTrees.GetLocalBoundingBox();
// 获取树包围盒顶点
mTreeBoxData = Collision::CreateBoundingBox(treeBox, XMFLOAT4(1.0f, 1.0f, 1.0f, 1.0f));
// 让树木底部紧贴地面位于y = -2的平面
treeBox.Transform(treeBox, S);
XMMATRIX T0 = XMMatrixTranslation(0.0f, -(treeBox.Center.y - treeBox.Extents.y + 2.0f), 0.0f);
// 随机生成256颗随机朝向的树
float theta = 0.0f;
for (int i = 0; i < 16; ++i)
{
// 取5-125的半径放置随机的树
for (int j = 0; j < 4; ++j)
{
// 距离越远,树木越多
for (int k = 0; k < 2 * j + 1; ++k)
{
float radius = (float)(rand() % 30 + 30 * j + 5);
float randomRad = rand() % 256 / 256.0f * XM_2PI / 16;
XMMATRIX T1 = XMMatrixTranslation(radius * cosf(theta + randomRad), 0.0f, radius * sinf(theta + randomRad));
XMMATRIX R = XMMatrixRotationY(rand() % 256 / 256.0f * XM_2PI);
XMMATRIX World = S * R * T0 * T1;
mInstancedData.push_back(World);
}
}
theta += XM_2PI / 16;
}
}若实例缓冲区的大小容不下当前增长的实例数据,则需要销毁原来的实例缓冲区,并重新创建一个更大的,以确保刚好能容得下之前的大量实例数据。
void GameObject::ResizeBuffer(ComPtr<ID3D11Device> device, size_t count)
{
// 设置实例缓冲区描述
D3D11_BUFFER_DESC vbd;
ZeroMemory(&vbd, sizeof(vbd));
vbd.Usage = D3D11_USAGE_DYNAMIC;
vbd.ByteWidth = count * (UINT)sizeof(XMMATRIX) * 2;
vbd.BindFlags = D3D11_BIND_VERTEX_BUFFER;
vbd.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE;
// 创建实例缓冲区
HR(device->CreateBuffer(&vbd, nullptr, mInstancedBuffer.ReleaseAndGetAddressOf()));
}该方法接受一个装满世界矩阵的数组,把数据装填进实例缓冲区(若容量不够则重新扩容),然后交给设备上下文进行实例的绘制
void GameObject::DrawInstanced(ComPtr<ID3D11DeviceContext> deviceContext, BasicFX & effect, const std::vector<DirectX::XMMATRIX>& data)
{
std::vector<XMMATRIX> acceptedData;
D3D11_MAPPED_SUBRESOURCE mappedData;
UINT numInsts = (UINT)data.size();
// 若传入的数据比实例缓冲区还大,需要重新分配
if (numInsts > mCapacity)
{
ComPtr<ID3D11Device> device;
deviceContext->GetDevice(device.GetAddressOf());
ResizeBuffer(device, numInsts);
}
HR(deviceContext->Map(mInstancedBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData));
InstancedData * iter = reinterpret_cast<InstancedData *>(mappedData.pData);
XMMATRIX worldInvTranspose;
for (auto& mat : data)
{
worldInvTranspose = XMMatrixTranspose(XMMatrixInverse(nullptr, mat));
iter->world = mat;
iter->worldInvTranspose = worldInvTranspose;
iter++;
}
deviceContext->Unmap(mInstancedBuffer.Get(), 0);
UINT strides[2] = { sizeof(VertexPosNormalTex), sizeof(InstancedData) };
UINT offsets[2] = { 0, 0 };
ID3D11Buffer * buffers[2] = { nullptr, mInstancedBuffer.Get() };
for (auto& part : mModel.modelParts)
{
buffers[0] = part.vertexBuffer.Get();
// 设置顶点/索引缓冲区
deviceContext->IASetVertexBuffers(0, 2, buffers, strides, offsets);
deviceContext->IASetIndexBuffer(part.indexBuffer.Get(), part.indexFormat, 0);
// 更新数据并应用
effect.SetTextureAmbient(part.texA);
effect.SetTextureDiffuse(part.texD);
effect.SetMaterial(part.material);
effect.Apply(deviceContext);
deviceContext->DrawIndexedInstanced(part.indexCount, numInsts, 0, 0, 0);
}
}剩余的代码都可以在GitHub项目中浏览。
该项目展示了一个同时存在225棵树的场景,用户可以自行设置开启/关闭视锥体裁剪或硬件实例化。若关闭硬件实例化,则是对每个对象单独调用绘制命令。
DirectX11 With Windows SDK完整目录
DirectX11 With Windows SDK--20 硬件实例化与视锥体裁剪
标签:erp 等价 经历 还需要 windows normal ddr cto 初始
原文地址:https://www.cnblogs.com/X-Jun/p/9702966.html