标签:描述 ret 节点 最简 判断 ios 优点 nlog 伪代码
LCA(最近公共祖先).....可惜我只会用tarjan去做
真心感觉tarjan算法要比倍增算法要好理解的多,可能是我脑子笨吧略略略
最近公共祖先概念:在一棵无环的树上寻找两个点在这棵树上深度最大的公共的祖先节点,也就是离这两个点最近的祖先节点。
最近公共祖先的应用:求解两个有且仅有一条确定的最短路径的路径
举个例子吧,如下图所示4和5的最近公共祖先是2,5和3的最近公共祖先是1,2和1的最近公共祖先是1。 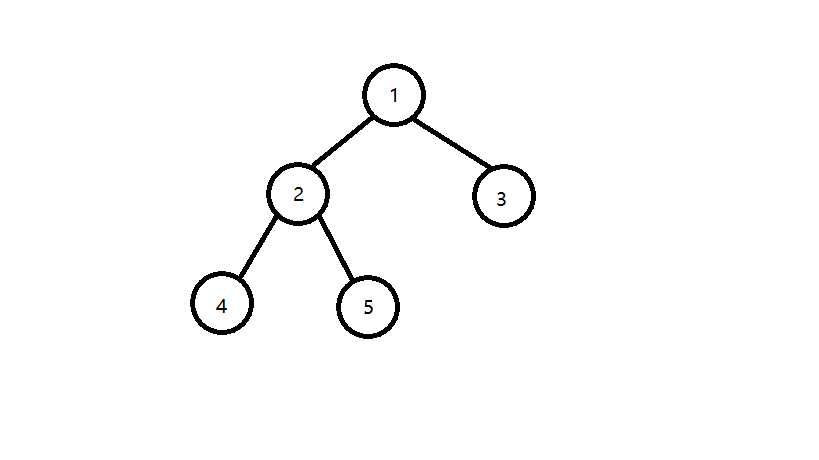
这就是最近公共祖先的基本概念了,那么我们该如何去求这个最近公共祖先呢?
Tarjan介绍:
通常初学者都会想到最简单粗暴的一个办法:对于每个询问,遍历所有的点,时间复杂度为O(n*q),那么这个复杂度当然也就呵呵了。
so, 我们有求解LCA的特殊算法:Tarjan /DFS+ST/倍增 (因为我不会,所以不喜欢)
后两个算法都是在线算法,也很相似,时间复杂度在O(logn)~O(nlogn)之间,我个人认为较难理解。
有的题目是可以用线段树来做的,但是其代码量很大,时间复杂度也偏高,在O(n)~O(nlogn)之间,优点在于也是简单粗暴。
tarjan属于离线算法,所谓的离线算法就是说我们需要将所有的询问都读入后一次性输出,而在线算法是你每读入一次询问它就计算一次结果
tarjan的时间复杂度是O(n+q)。
Tarjan算法的优点在于相对稳定,时间复杂度也比较居中,也很容易理解。
Tarjan算法的基本思路 :
1、从某一个节点开始,向下遍历它的所有子节点
2、当遍历到它的某个子节点是叶节点时,将这个叶节点与其父节点合并,然后将其打上标记
3、寻找和它有关的询问点(题目中给出的询问,这里全部以洛谷P3379 【模板】最近公共祖先(LCA)的格式讲解)
4、如果有和它相关的询问点的话,判断那个点是否标记过(为什么要判断,一会讲)
5、(1)如果没有标记,跳过,不做任何操作
(2)如果已标记,那么我们就能确定这两个询问点的最近公共祖先(一会解释原因)
学习该算法所必需的知识 :2中的遍历我们用的是DFS遍历,合并我们用的是并查集的合并操作
3中的寻找我们用的是邻接表
5中的确定最近公共祖先是并查集中的find函数
解释思路中的两点疑惑:
1、第一个小解释:我们的询问点是成对出现的,为了防止我们多算,错算,所以我们规定放在后一个询问点进行操作
第二个重要解释 :当我们在对第一个点进行操作时我们并不知道第二个点在哪,我们自然也就不知道这两个点的最近公共祖先在哪。但是如果我们两个点都找到了便可以操作了。
2、你会发现在遍历时是有规律的,某两个询问点的最近公共祖先就是最先一个 (第一个点的)父节点等于它本身的点,你想想啊当我们在找第二个点的时候我们其实已经将 第二个点以前的 遍历过的点 都找完其父节点(也就不等于本身了),如果说第二个点和第一个点的最近公共祖先在这些父节点之中的话 那么他们的最近公共祖先不就应该是这些父节点当中的点吗?且第一个等于本身的父节点 一定是最近的。所以得证,当两个点已知之后第一个点的父节点就是他们的公共祖先。
下面上伪代码:

1 Tarjan(u)//marge和find为并查集合并函数和查找函数
2 {
3 for each(u,v) //访问所有u子节点v
4 {
5 Tarjan(v); //继续往下遍历
6 marge(u,v); //合并v到u上
7 标记v被访问过;
8 }
9 for each(u,e) //访问所有和u有询问关系的e
10 {
11 如果e被访问过;
12 u,e的最近公共祖先为find(e);
13 }
14 }
模拟过程:
如果还是不明白的话,我这里借用了https://www.cnblogs.com/JVxie/p/4854719.html 的模拟
建议拿着纸和笔跟着我的描述一起模拟!!
假设我们有一组数据 9个节点 8条边 联通情况如下:
1--2,1--3,2--4,2--5,3--6,5--7,5--8,7--9 即下图所示的树
设我们要查找最近公共祖先的点为9--8,4--6,7--5,5--3;
设f[]数组为并查集的父亲节点数组,初始化f[i]=i,vis[]数组为是否访问过的数组,初始为0; 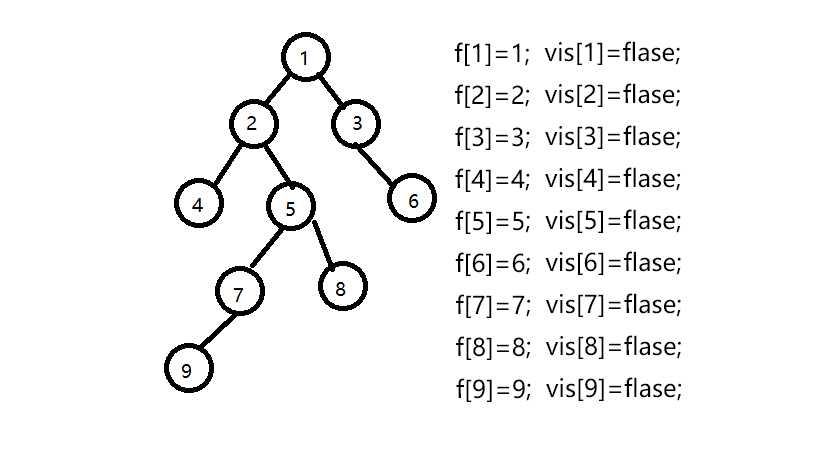
下面开始模拟过程:
取1为根节点,往下搜索发现有两个儿子2和3;
先搜2,发现2有两个儿子4和5,先搜索4,发现4没有子节点,则寻找与其有关系的点;
发现6与4有关系,但是vis[6]=0,即6还没被搜过,所以不操作;
发现没有和4有询问关系的点了,返回此前一次搜索,更新vis[4]=1;
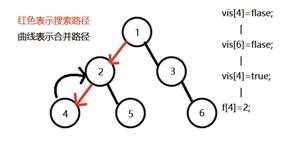
表示4已经被搜完,更新f[4]=2,继续搜5,发现5有两个儿子7和8;
先搜7,发现7有一个子节点9,搜索9,发现没有子节点,寻找与其有关系的点;
发现8和9有关系,但是vis[8]=0,即8没被搜到过,所以不操作;
发现没有和9有询问关系的点了,返回此前一次搜索,更新vis[9]=1;
表示9已经被搜完,更新f[9]=7,发现7没有没被搜过的子节点了,寻找与其有关系的点;
发现5和7有关系,但是vis[5]=0,所以不操作;
发现没有和7有关系的点了,返回此前一次搜索,更新vis[7]=1;
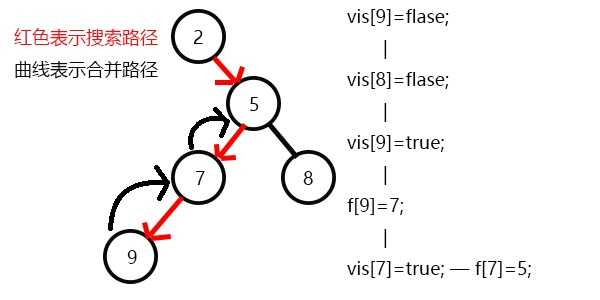
表示7已经被搜完,更新f[7]=5,继续搜8,发现8没有子节点,则寻找与其有关系的点;
发现9与8有关系,此时vis[9]=1,则他们的最近公共祖先为find(9)=5;
(find(9)的顺序为f[9]=7-->f[7]=5-->f[5]=5 return 5;)
发现没有与8有关系的点了,返回此前一次搜索,更新vis[8]=1;
表示8已经被搜完,更新f[8]=5,发现5没有没搜过的子节点了,寻找与其有关系的点;
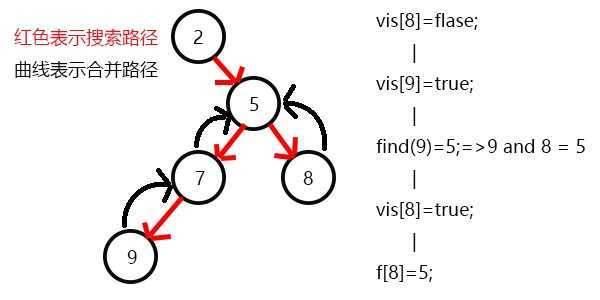
发现7和5有关系,此时vis[7]=1,所以他们的最近公共祖先为find(7)=5;
(find(7)的顺序为f[7]=5-->f[5]=5 return 5;)
又发现5和3有关系,但是vis[3]=0,所以不操作,此时5的子节点全部搜完了;
返回此前一次搜索,更新vis[5]=1,表示5已经被搜完,更新f[5]=2;
发现2没有未被搜完的子节点,寻找与其有关系的点;
又发现没有和2有关系的点,则此前一次搜索,更新vis[2]=1;
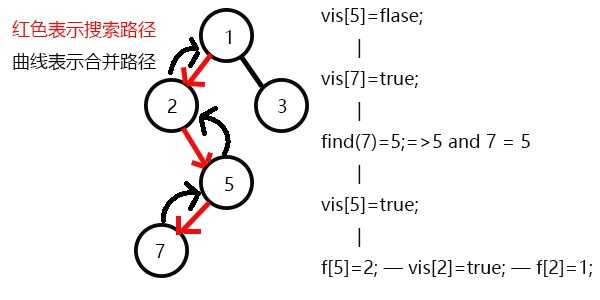
表示2已经被搜完,更新f[2]=1,继续搜3,发现3有一个子节点6;
搜索6,发现6没有子节点,则寻找与6有关系的点,发现4和6有关系;
此时vis[4]=1,所以它们的最近公共祖先为find(4)=1;
(find(4)的顺序为f[4]=2-->f[2]=1-->f[1]=1 return 1;)
发现没有与6有关系的点了,返回此前一次搜索,更新vis[6]=1,表示6已经被搜完了;
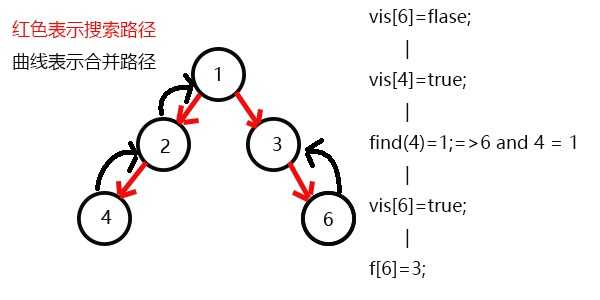
更新f[6]=3,发现3没有没被搜过的子节点了,则寻找与3有关系的点;
发现5和3有关系,此时vis[5]=1,则它们的最近公共祖先为find(5)=1;
(find(5)的顺序为f[5]=2-->f[2]=1-->f[1]=1 return 1;)
发现没有和3有关系的点了,返回此前一次搜索,更新vis[3]=1;
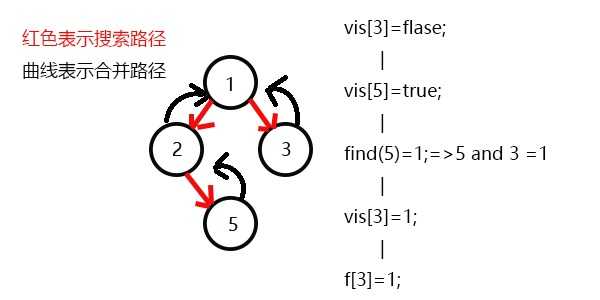
更新f[3]=1,发现1没有被搜过的子节点也没有有关系的点,此时可以退出整个dfs了。
经过这次dfs我们得出了所有的答案,有没有觉得很神奇呢?是否对Tarjan算法有更深层次的理解了呢?
代码实现:(洛谷P3379 【模板】最近公共祖先(LCA))
#include<iostream> #include<cstdio> #include<cstring> using namespace std; int head1[500010]; int head2[500010]; int father[500010]; int fa[500010]; int vis[500010]; int ans[500010<<1]; int n,m,s; int cnt,cntt; int find(int x){ if(fa[x]==x)return x; return fa[x]=find(fa[x]); } void merge(int x,int y){ int xx=find(x); int yy=find(y); if(xx!=yy){ fa[xx]=yy; } } struct Edge{ int s,t,next; }edge1[500000<<1]; struct Edge2{ int s,t,next; }edge2[500000<<1]; // 双向边 void add_bian(int u,int v){ //存我们的询问点 cnt++; edge1[cnt].s=u; edge1[cnt].t=v; edge1[cnt].next=head1[u]; head1[u]=cnt; } void add_shu(int u,int v){ //存我们的这棵树 cntt++; edge2[cntt].s=u; edge2[cntt].t=v; edge2[cntt].next=head2[u]; head2[u]=cntt; } void tarjan(int x){ for(int i=head2[x];i;i=edge2[i].next){ int v=edge2[i].t; if(v==father[x])continue; //因为我们建树是双向的,如果我们遇到了某个节点的父亲是儿子(这不胡闹嘛)就跳过 father[v]=x; tarjan(v); //遍历 merge(v,x); //合并 vis[v]=1; //这时我们打上标记 } for(int i=head1[x];i;i=edge1[i].next){ int v=edge1[i].t; if(vis[v]){ ans[i]=find(v); //如果它的另一条边已标记过,就说明他们的最近公共祖先就是v的父节点 } } } int main(){ scanf("%d%d%d",&n,&m,&s); for(int i=1;i<n;i++){ int a,b; scanf("%d%d",&a,&b); add_shu(a,b); add_shu(b,a); } for(int i=1;i<=m;i++){ int x,y; scanf("%d%d",&x,&y); add_bian(x,y); add_bian(y,x); } for(int i=1;i<=n;i++){ fa[i]=i; father[i]=i; } tarjan(s); //从s点开始 for(int i=1;i<=m;i++){ printf("%d\n",max(ans[2*i],ans[2*i-1])); //因为这里是双向边,所以我们的第i个边实际上是第2*i个和第2*i-1个 } return 0; }
End...
标签:描述 ret 节点 最简 判断 ios 优点 nlog 伪代码
原文地址:https://www.cnblogs.com/xiaoK-778697828/p/9703782.html