标签:src 静态 操作 extend 使用 索引 tac 保留 list接口
Set代表一种集合元素无序、集合元素不可重复的集合,Map则代表一种由多个key-value对组成的集合,Map集合类似于传统的关联数组。表面上看它们之间相似性很少,但实际上Map和Set之间有莫大的关联。
在看Set和Map之间的关系之前,先来看看Set集合的继承体系。
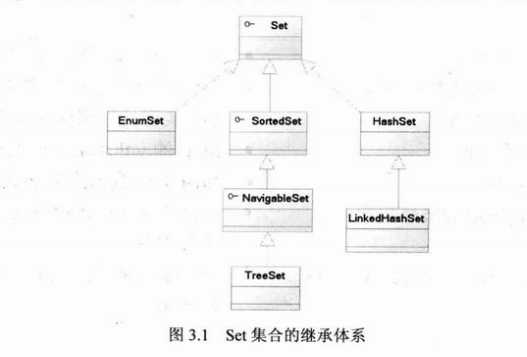
再看Map集合的类继承关系:
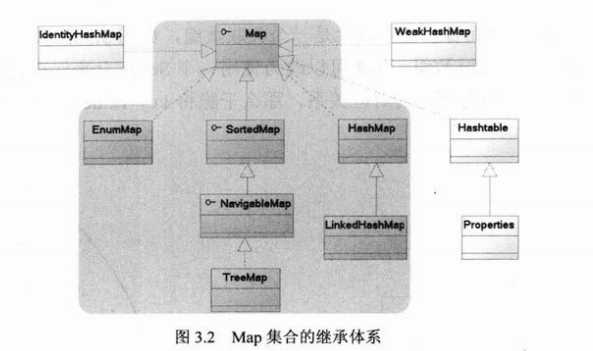
仔细观察图3.2中的Map集合的继承体系里被灰色覆盖的区域,可以发现,这些Map接口、实现类和Set集合的接口、实现类的类名完全类似,这绝不是偶然的现象,肯定有必然的原因。
考虑Map集合的key,不难发现,这些Map集合的key具有一个特征:所有的key不能重复,key之间没有顺序,也就是说,如果把Map集合的key集中起来,那这些key就组成了一个Set集合。所以,Map集合提供了如下方法来返回所有key组成的Set集合。
Set<K> keySet()
换一个思维来理解Map集合,如果把Map集合的value当成key的“附属物”(实际上也是,对于一个Map集合而言,只要给出指定的key,Map总是可以根据该key快速查询到对应的value),那么Map集合在保存key-value对时只需考虑key即可。
下面是HashMap类的put()方法源代码如下:


上面的程序用到了一个重要的内部接口Map.Entry,每个Map.Entry其实就是一个key-value对。从上面的程序可以看出:当系统决定存储HashMap中的key-value对时,完全没有考虑Entry的value,而仅仅只是根据key来计算并决定每个Entry的存储位置,这也说明了前面的结论:完全可以把Map集合中的value当成是key的附属,当系统决定了key的存储位置之后,value随之保存在那里即可。
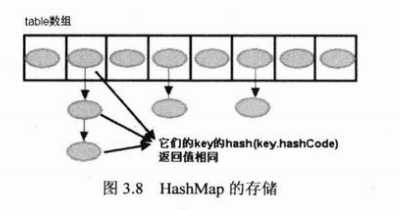
从上面的put方法的源代码可以看出,当程序试图将一个key-value对放入HashMap中时,首先根据该key的hashCode()返回值决定该Entry的存储位置:如果两个Entry的key的hashCode()返回值相同,那他们的存储位置相同;如果这两个Entry的key通过equals比较返回true,新添加Entry的value将覆盖集合中原有的Entry的value,但key不会覆盖;如果这两个Entry的key通过equals比较返回false,新添加的Entry将与集合中原有的Entry形成Entry链,而且心田家的Entry位于Entry位于Entry链的头部。下面来看addEntry方法:

代码相对来说比较简单,系统总是将新添加的Entry对象放入table数组的bucketIndex索引处。如果bucketIndex索引处已经有了一个Entry对象,新添加的Entry对象指向原有的Entry对象(产生一个Entry链);如果bucketIndex索引处没有Entry对象,也就是上面程序1行代码的e变量是null,即新放入的Entry对象指向null,就没有产生Entry链。
下面我们来看看HashSet:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
.....
}
HashSet的实现非常简单,它只是封装了一个HashMap对象来存储所有的集合元素。所有放入HashSet的集合元素实际上由HashMap的key来保存,而HashMap的value则存储一个PRESENT,它是一个静态的Object对象。HashSET的绝大部分方法都是通过调用HashMap方法来实现的。
类似于HashMap和HashSet之间的关系,HashSet底层依赖于HashMap实现,TreeSet底层则采用一个NavigableMap来保存TreeSet集合的元素。但实际上,由于NavigableMap只是一个接口,因此底层依然是是使用TreeMap来包含Set集合中的所有元素。
对于TreeMap而言,底层采用“红黑树”的排序二叉树来保存Map中的每个Entry。
在List集合的实现类中,主要有3个实现类:ArrayList、Vector、LinkedList。其中Vector还有一个Stack(栈)子类,这个Stack子类仅在Vector父类的基础上增加了5个方法。
public
class Stack<E> extends Vector<E> {
/**
* Creates an empty Stack.
*/无参构造器
public Stack() {
}
/**
* 进栈*/
public E push(E item) {
addElement(item);
return item;
}
/**
* 出栈*/
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
/**
* peek瞟一眼,取出最后一个元素,但是并不出栈*/
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
/**
* 判断是否为空*/
public boolean empty() {
return size() == 0;
}
/**
* 元素的到栈顶的距离*/
public synchronized int search(Object o) {
//获取o在集合中的位置
int i = lastIndexOf(o);
if (i >= 0) {
//集合长度减去在集合中的位置,就得到元素的到栈顶的距离
return size() - i;
}
return -1;
}
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = 1224463164541339165L;
}
可以看到,Stack新增的5个方法中有3个使用了synchronized修饰(那些需要操作集合元素的方法都添加了synchronized修饰),也就是说Stack是一个线程安全的类,这也是为了让Stack与Vector保持一致,Vector也是一个线程安全的类。
实际上即使当程序需要栈这种数据结构时,Java也不在推荐Stack类,而是推荐使用Deque实现类。从JDK1.6开始,Java提供了一个Deque接口,并为接口提供了一个ArrayDeque实现类。在无需保证线程安全的情况下,程序完全可以使用ArrayDeque代替Stack类。
Deque接口代表双端队列这种数据结构。双端队列已经不再是简单的队列了,它既具有队列的性质先进先出(FIFO),也具有栈的性质(FILO),也就是说双端队列既是队列,也是栈。ArrayList和ArrayDeque底层都是基于Java数组来实现的。
Vector和ArrayList这两个集合类的本质并没有太大不同,都实现了List接口,底层都是基于Java数组来存储集合元素。
ArrayList的部分源码:
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
Vector的部分源码:
/**
* The array buffer into which the components of the vector are
* stored. The capacity of the vector is the length of this array buffer,
* and is at least large enough to contain all the vector‘s elements.
*
* <p>Any array elements following the last element in the Vector are null.
*
* @serial
*/
protected Object[] elementData;
可以看到,ArrayList使用transient修饰了elementData数组。这保证了系统序列化ArrayList对象时不会直接序列化elementData数组,而是通过ArrayList提供的writeObject、readObject来实现定制序列化。除此之外,Vector其实就是ArrayList的线程安全版本。即使需要在多线程环境下使用List集合,依然可以避免使用Vector。Java提供了一个Collections工具类,通过该工具类synchronizedList方法就可将普通ArrayList包装成线程安全的ArrayList。
ArrayList是一种顺序存储的线性表,底层使用数组来保存集合元素;LinkedList则是一种链式存储的线性表,其本质上是一个双向链表,而它不仅实现了List接口,还实现了Deque接口,也就是说LinkedList既可以当成双向链表使用,也可以当成队列使用,还可以当成栈来使用。两者的优缺点就是数组和链表的优缺点,就经验来说,ArrayList性能总体上优于LinkedList。
当程序需要以get(int index)方法获取List集合指定索引处的元素时,ArrayList性能大大优于LinkedList,LinkedList必须一个个地搜索过去。当程序调用add(int index,Object obj)向List集合中添加元素时,ArrayList必须对底层数组元素进行“整体搬家”,如果添加元素导致集合长度将要超过数组长度,ArrayList必须创建一个为原来长度1.5倍的数组,再由垃圾回收机制回收原有数组,因此开销比较大。
对于Iterator迭代器而言,它只是一个接口,Java要求各种集合都提供一个iterator()方法,该方法可以返回一个Iterator用于遍历该集合中元素,至于返回的Iterator到底是哪种实现类,程序并不关心,这就是典型的“迭代器模式”。
迭代时删除指定元素:由于迭代器只负责对各种集合所包含的元素进行迭代,它自己并没有保留集合元素,因此迭代时,通常不应该删除集合元素,否则将引发ConcurrentModificationException异常。当然,Java里面集合是允许使用Iterator的remove()方法删除刚刚迭代过的元素。
1 public class Test {
2
3
4 public static void main(String[] args) {
5
6 List<String> list = new ArrayList<String>();
7 list.add("1");
8 list.add("2");
9 list.add("3");
10 Iterator<String> it = list.iterator();
11 while(it.hasNext()){
12 String temp = it.next();
13 it.remove();
14 }
15 }
16 }
此程序无问题,但是注意第十三行删除时,必须执行了十二行。
标签:src 静态 操作 extend 使用 索引 tac 保留 list接口
原文地址:https://www.cnblogs.com/caozx/p/9492234.html