标签:overwrite 方法 prope otto 磁盘 ase http self idt
rtree模块有2个常用的类:rtree.index.Index和rtree.index.Property。其中rtree.index.Index用于进行数据操作,rtree.index.Property用于对index进行属性的设定。
当用rtree包进行三维及以上的维度索引数据到磁盘时会创建俩个索引文件,Rtree默认使用扩展名dat和idx。可以使用rtree.index.Property.dat_extension和rtree.index.Property.idx_extension来控制索引文件的扩展名。其中.idx是索引文件,.dat是数据文件
下面是简单的实例:
from rtree import index
class RtreeCase():
def __init__(self):
self.p = index.Property()
self.p.dimension = 3
self.p.dat_extension = ‘data‘
self.p.idx_extension = ‘index‘
self.idx3d = index.Index(‘case’,properties=self.p)
self.idx3d.insert(1, (0, 60, 23))
self.idx3d.insert(2, (0, 60, 24))
self.idx3d.insert(3, (0, 60, 25))
self.idx3d.insert(4, (0, 60, 26))
self.idx3d.insert(5, (0, 60, 27))
def handle(self,width,num):
res=list(self.idx3d.nearest(width,num))
return res
def main():
ass=RtreeCase()
print(ass.handle((0,60,25),3))
print(ass.handle((0,60,1),2))
if __name__ == ‘__main__‘:
main()
在上面实例中,通过rtree.index.Property.dimension = 3确定index的属性为三维数据,通过rtree.index.Index.insert()来插入数据,insert方法中需要传递俩个参数,第一个为一个长整数,表示这条数据的id,
但这里的id可以重复。第二个参数是一个元祖表示数据的位置。所有函数的坐标排序对索引的交错数据成员都很敏感 。如果 interleaved为False,则坐标必须采用[xmin,xmax,ymin,ymax,...,...,kmin,kmax]的形式。
如果 interleaved为True,则坐标必须采用[xmin,ymin,...,kmin,xmax,ymax,...,kmax]的形式。
插入一个点,即left == right && top == bottom,将基本上将单个点条目插入到索引中,而不是复制额外的坐标并插入它们。但是,没有明确插入单个点的快捷方式。
rtree.index.Index()是创建一个rtree实例,可以传俩个参数,第一个参数是字符型表示生成的索引文件的名称,第二个参数为properties=P,表示将rtree.index.Property定义的属性
传递给index对象。
rtree.index.nearest()可以获取离目标点位距离最近的几条数据,该方法有俩个参数,第一个参数是输入一个元祖即目标的坐标。第二个参数是一个整型,表示要返回几个坐标。例如如果第二个参数为1时
只会返回离他最近的一条数据的id,没错返回的是插入时输入的第一个参数。但当离他最近的数据有多条时,这些数据都会被返回,哪怕你设置的第二个参数为1。
第一次运行的结果为:
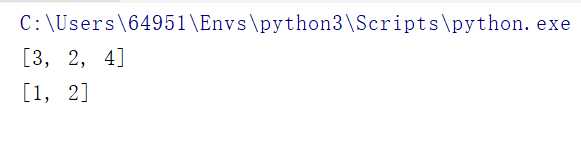

找出了对应的数据id,并且生成了索引文件。但如果重新执行一遍会发现输出结果为:

天啊!一样的代码,为何结果不一样?造成这个结果的罪魁祸首是第一次生成的索引文件,默认情况下,如果文件系统中已存在上述示例中具有给定名称rtree的索引文件,则它将以追加模式打开而不能重新创建。可以使用可以赋予rtree.index.Index构造函数的index属性的rtree.index.Property.overwrite属性来控制此行为 。
当然也可以在创建index实例时,第一个参数即字符型索引文件名称那个不写,就不会生成索引文件了,自然也就不会造成结果的追加。
标签:overwrite 方法 prope otto 磁盘 ase http self idt
原文地址:https://www.cnblogs.com/xuzijie/p/9719639.html