标签:特征 初始 and 基于 info 养成 需要 方向 好的
因写作需要,再精读一下这篇文章,只说这篇文章提出的方法。
1、摘要部分:
本文提出了一种基于卷积神经网络的深层次显著性网络(deep hierarchical saliency network,DHSNet)。该网络以下统一称作“DHSNet”。工作流程大体是这样的:
1)首先,DHSNet通过自动学习各种全局结构上的显著性线索(这些线索包括全局对比度、对象性、紧凑性以及它们的优化组合),对输入的图片生成一个粗略的全局上的预测结果;
2)接着, 本文提出了一种分层递归卷积神经网络(hierarchical recurrent convolutional neural network ,HRCNN),该网络通过融合局部上下文信息,进一步分层次地逐步地细化显著图的细节。
总的来说,整个网络架构呈现出一种从全局趋于局部,从粗略趋于精细的工作模式。
最终检测效果是很不错的。
介绍部分:
这部分较为详细地介绍了本文算法的工作步骤:
1)首先提出一个global view CNN网络,简称GV-CNN。GV-CNN对输入的整幅图片进行首次处理,生成一个粗略的显著图 SmG ,用于粗略地检测和定位显著性目标;
(有全局结构化损失作为监督信息,GV-CNN可以自动学习特征表示和各种全局结构上的显著性线索---注意此处高亮部分,上下文对应起来,联系起来,读论文,养成刻意思考的习惯,串成一个整体,有助于长期记忆以及更好的理解学习,题外话了)
问题来了,那就是第一步生成的那个粗略的显著图 SmG与输入图片的相比,明显粗糙了许多,原因在于经过GV-CNN网络处理之后,丢失了一些诸如目标准确边界、细微结构等的细节信息,为何会丢失呢?熟悉深度神经网络的,应该知道,网络结构中都会有池化层,池化操作一般有两种,即平均池化和最大池化,一般多采用最大池化(本文即如此),池化操作就是为了减少计算量,只保留一部分数据,最大池化即只保留最大值,舍弃其他信息,舍弃的同时,也无可避免会丢失掉一些有用的空间信息。本文网络结构包含四个最大池化层。
2)为解决上述问题,本文进而提出了分层递归卷积神经网络(---此处同理,与上文对应。hierarchical recurrent convolutional neural network ,HRCNN)。该网络通过融合局部上下文信息,进一步分层次地逐步地细化显著图的细节。
来看一下HRCNN网络是什么组成的,该网络由几个递归卷积层(recurrent convolutional layers,RCL)和几个下采样层组成。其中,递归卷积层RCL将递归链接并入每一卷积层中,从而增强了模型如何上下文信息的能力,这一点对于得到的显著性检测模型至关重要。
前面说过,HRCNN网络通过融合局部上下文信息,进一步分层次地逐步地细化显著图的细节。这其中的每一步是这样工作的:RCL(RCL是HRCNN网络的重要组成部分)通过将下采样得到的那个粗略的显著图与经过 GV-CNN网络处理得到的较精细的特征图进行融合,来最终生成一个较精细的显著图。RCL逐步细化,为下一步打造了一个更好的初始化值。
那么,下面这些一看就很舒服啊:

请看本文所提算法整体架构:
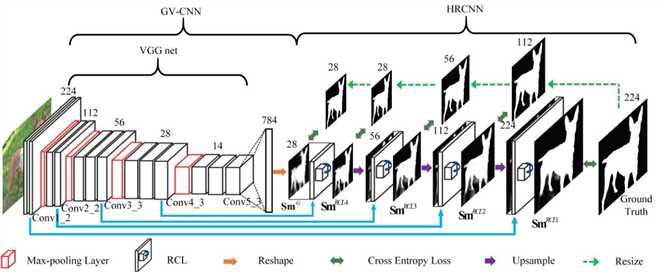
Figure 2: The architecture of the proposed DHSNet method. The spatial size of each image or feature map is given. In the VGG16 net, the names of the layers whose features are utilized in the HRCNN are shown. The name of each step-wise saliency map is also shown.
如果你想整体把握和概括this paper,下面这段话就是全文中心句:
DHSNet is composed of the GV-CNN and the HRCNN as shown in the above figure. The GV-CNN first coarsely detects salient objects in a global perspective, then the HRCNN hierarchically and progressively refines the details of the saliency map step by step. DHSNet is trained end-to-end.
2、相关工作:
这一部分以及上面介绍部分的一些简介,一般可以让我们了解一些该研究方向的历史,有心人自行检索学习,时间关系先不介绍。
3、DHSNet for Salient Object Detection(这一部分为本文算法详细介绍):
3.1. GV-CNN for Coarse Global Prediction
GV-CNN包括一个由13层卷积层组成的VGG net,接下来是一个全连接层,和一个reshape层(注:reshape layer是深度学习框架caffe中的常用层)。
简言之,输入图片大小224*224=50176,经过13层卷积层的VGG16 net后,大小变为14*14*512=100352=50176*2(对于此结果,自己可以研究一下卷积层的工作方式以及VGG16);接着经过一个拥有sigmoid激活函数的全连接层,输出结果拥有784个节点(同样,学习一下全连接层的工作方式);最后经过一个reshape层,得到一个上文提到的粗略的全局显著性图 SmG,其大小被reshape为28*28。
3.2. HRCNN for Hierarchical Saliency Map Refinement
为何会提出HRCNN 网络呢?为了进一步细化提升上一步得到的那个粗略的全局显著性图SmG的细节。
1)Recurrent Convolutional Layer
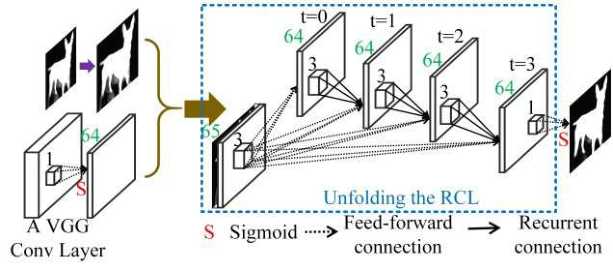
Figure 3: The detailed framework of a refinement step. The RCL is unfolded along with the time steps in the blue dotted box.
引入递归卷积层Recurrent Convolutional Layer,RCL。它是HRCNN 网络的核心组成部分。
递归卷积层将递归连接并入每一卷积层中,对于RCL网络中第K个特征图上坐标为(i,j)的单元,其在时间t时的状态为:

f为激活函数,采用整流线性单元ReLU;g为本地响应归一化函数(local response normalization (LRN) function)---有时候感觉还是原文更好理解,翻译出来怪怪的。该LRN函数用于防止出现梯度爆炸:
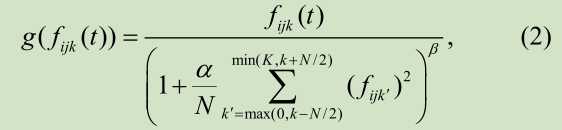


2) Hierarchical Saliency Map Refinement
看图2:首先将SmG和VGG net的Conv4_3层结合,生成一个较精细的显著图,将其命名为SmRCL4,命名规则下同。和大小为56*56的Conv3_3相比,SmRCL4大小较小,只有28*28。我们首先对SmRCL4进行上采样,将其大小翻倍;然后将翻倍后的SmRCL4与Conv3_3结合,生成SmRCL3;继续将上采样后的SmRCL3与Conv2_2结合,生成SmRCL2;最后,将上采样后的SmRCL2与Conv1_2结合,生成SmRCL1。SmRCL1是我们最终得到的显著图。
图3显示了一个精调步骤的细节框架。
论文阅读:DHSNet: Deep Hierarchical Saliency Network for Salient Object Detection
标签:特征 初始 and 基于 info 养成 需要 方向 好的
原文地址:https://www.cnblogs.com/ariel-dreamland/p/9714484.html