标签:rgb style 含义 不同类 sort sample 最好 像素 速度
在说到人脸检测我们首先会想到利用Harr特征提取和Adaboost分类器进行人脸检测(有兴趣的可以去一看这篇博客第九节、人脸检测之Haar分类器),其检测效果也是不错的,但是目前人脸检测的应用场景逐渐从室内演变到室外,从单一限定场景发展到广场、车站、地铁口等场景,人脸检测面临的要求越来越高,比如:人脸尺度多变、数量冗大、姿势多样包括俯拍人脸、戴帽子口罩等的遮挡、表情夸张、化妆伪装、光照条件恶劣、分辨率低甚至连肉眼都较难区分等。在这样复杂的环境下基于Haar特征的人脸检测表现的不尽人意。随着深度学习的发展,基于深度学习的人脸检测技术取得了巨大的成功,在这一节我们将会介绍MTCNN算法,它是基于卷积神经网络的一种高精度的实时人脸检测和对齐技术。
搭建人脸识别系统的第一步就是人脸检测,也就是在图片中找到人脸的位置。在这个过程中输入的是一张含有人脸的图像,输出的是所有人脸的矩形框。一般来说,人脸检测应该能够检测出图像中的所有人脸,不能有漏检,更不能有错检。

获得人脸之后,第二步我们要做的工作就是人脸对齐,由于原始图像中的人脸可能存在姿态、位置上的差异,为了之后的统一处理,我们要把人脸“摆正”。为此,需要检测人脸中的关键点,比如眼睛的位置、鼻子的位置、嘴巴的位置、脸的轮廓点等。根据这些关键点可以使用仿射变换将人脸统一校准,以消除姿势不同带来的误差。
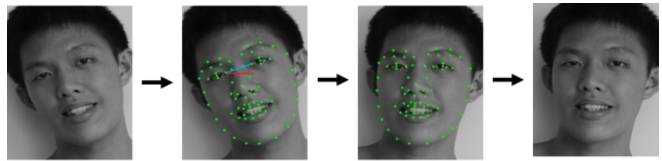
MTCNN算法是一种基于深度学习的人脸检测和人脸对齐方法,它可以同时完成人脸检测和人脸对齐的任务,相比于传统的算法,它的性能更好,检测速度更快。
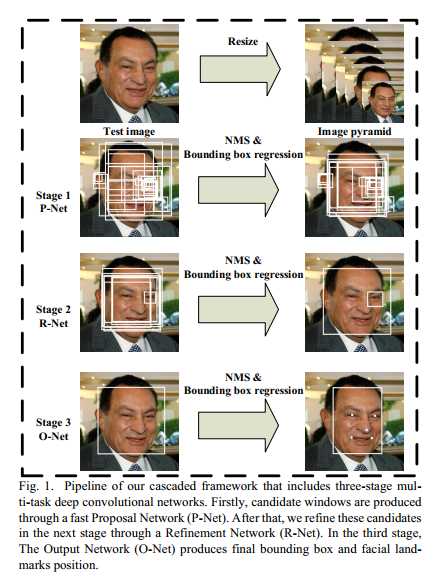
MTCNN算法包含三个子网络:Proposal Network(P-Net)、Refine Network(R-Net)、Output Network(O-Net),这三个网络对人脸的处理依次从粗到细。
在使用这三个子网络之前,需要使用图像金字塔将原始图像缩放到不同的尺度,然后将不同尺度的图像送入这三个子网络中进行训练,目的是为了可以检测到不同大小的人脸,从而实现多尺度目标检测。
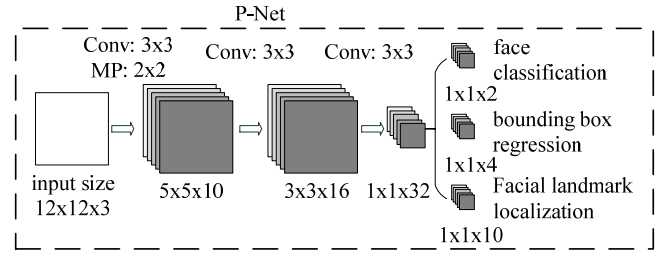
P-Net的主要目的是为了生成一些候选框,我们通过使用P-Net网络,对图像金字塔图像上不同尺度下的图像的每一个$12\times{12}$区域都做一个人脸检测。
P-Net的输入是一个$12\times{12}\times{3}$的RGB图像,在训练的时候,该网络要判断这个$12\times{12}$的图像中是否存在人脸,并且给出人脸框的回归和人脸关键点定位;
在测试的时候输出只有$N$个边界框的4个坐标信息和score,当然这4个坐标信息已经使用网络的人脸框回归进行校正过了,score可以看做是分类的输出(即人脸的概率):
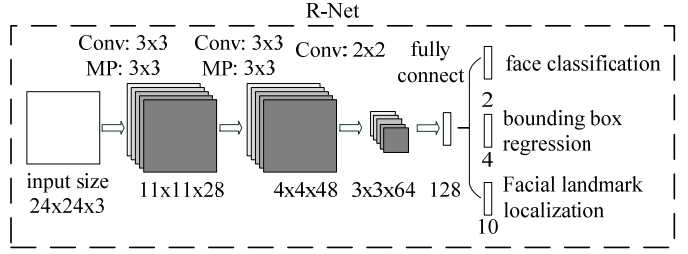
由于P-Net的检测时比较粗略的,所以接下来使用R-Net进一步优化。R-Net和P-Net类似,不过这一步的输入是前面P-Net生成的边界框,每个边界框的大小都是$24\times{24}\times{3}$,可以通过缩放得到。网络的输出和P-Net是一样的。这一步的目的主要是为了去除大量的非人脸框。
进一步将R-Net的所得到的区域缩放到$48\times{48}\times{3}$,输入到最后的O-Net,O-Net的结构与P-Net类似,只不过在测试输出的时候多了关键点位置的输出。输入大小为$48\times{48}\times{3}$的图像,输出包含$P$个边界框的坐标信息,score以及关键点位置。

从P-Net到R-Net,再到最后的O-Net,网络输入的图像越来越大,卷积层的通道数越来越多,网络的深度也越来越深,因此识别人脸的准确率应该也是越来越高的。同时P-Net网络的运行速度越快,R-Net次之、O-Net运行速度最慢。之所以使用三个网络,是因为一开始如果直接对图像使用O-Net网络,速度回非常慢。实际上P-Net先做了一层过滤,将过滤后的结果再交给R-Net进行过滤,最后将过滤后的结果交给效果最好但是速度最慢的O-Net进行识别。这样在每一步都提前减少了需要判别的数量,有效地降低了计算的时间。
由于MTCNN包含三个子网络,因此其损失函数也由三部分组成。针对人脸识别问题,直接使用交叉熵代价函数,对于框回归和关键点定位,使用$L2$损失。最后把这三部分的损失各自乘以自身的权重累加起来,形成最后的总损失。在训练P-Net和R-Net的时候,我们主要关注目标框的准确度,而较少关注关键点判定的损失,因此关键点损失所占的权重较小。对于O-Net,比较关注的是关键点的位置,因此关键点损失所占的权重就会比较大。
在针对人脸识别的问题,对于输入样本$x_i$,我们使用交叉熵代价函数:
$$L_i^{det}=-(y_i^{det}log(p_i) + (1-y_i^{det})(1-log(p_i)))$$
其中$y_i^{det}$表示样本的真实标签,$p_i$表示网络输出为人脸的概率。
对于目标框的回归,我们采用的是欧氏距离:
$$L_i^{box}=\|\hat{y}_i^{box} - y_i^{box}\|$$
其中$\hat{y}_i^{box}$表示网络输出之后校正得到的边界框的坐标,$y_i^{box}$是目标的真实边界框。
对于关键点,我们也采用的是欧氏距离:
$$L_i^{landmark}=\|\hat{y}_i^{landmark} - y_i^{landmark}\|$$
其中$\hat{y}_i^{landmark}$表示网络输出之后得到的关键点的坐标,$y_i^{landmark}$是关键点的真实坐标。
把上面三个损失函数按照不同的权重联合起来:
$$min\sum\limits_{i=1}^{N}\sum\limits_{j\in\{det,box,landmark\}}\alpha_j\beta_i^jL_i^j$$
其中$N$是训练样本的总数,$\alpha_j$表示各个损失所占的权重,在P-Net和R-net中,设置$\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=0.5$,在O-Net中,设置$\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=1$,$\beta_i^j\in\{0,1\}$表示样本类型指示符。
这段话也就是说,我们在训练的时候取前向传播损失值(从大到小)前70%的样本,来进行反向传播更新参数。
该算法训练数据来源于wider和celeba两个公开的数据库,wider提供人脸检测数据,在大图上标注了人脸框groundtruth的坐标信息,celeba提供了5个landmark点的数据。根据参与任务的不同,将训练数据分为四类:
上面滑动窗口指的是:通过滑动窗口或者随机采样的方法获取尺寸为$12\times{12}$的框:
wider数据集,数据可以从http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/地址下载。该数据集有32,203张图片,共有93,703张脸被标记,如下图所示:

celeba人脸关键点检测的训练数据,数据可从http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm地址下载。该数据集包含5,590张 LFW数据集的图片和7,876张从网站下载的图片。

在上面我们已经介绍了人脸检测,人脸检测是人脸相关任务的前提,人脸相关的任务主要有以下几种:
下面我们来详细介绍人脸识别技术:当我们通过MTCNN网络检测到人脸区域图像时,我们使用深度卷积网络,将输入的人脸图像转换为一个向量的表示,也就是所谓的特征。
那我们如何对人脸提取特征?我们先来回忆一下VGG16网络,输入的是图像,经过一系列卷积计算、全连接网络之后,输出的是类别概率。
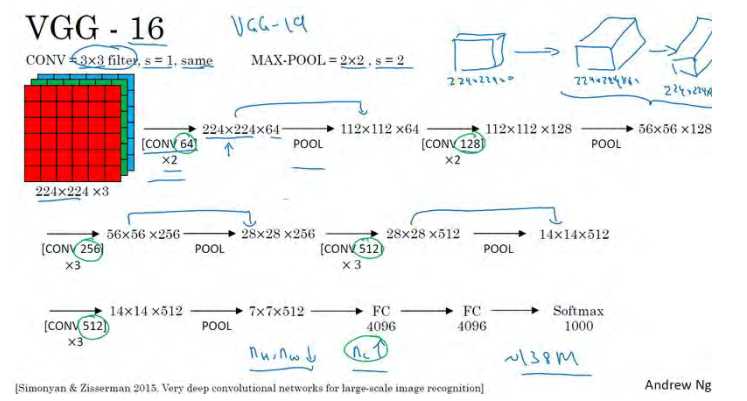
在通常的图像应用中,可以去掉全连接层,使用卷积层的最后一层当做图像的“特征”,如上图中的conv5_3。但如果对人脸识别问题同样采用这样的方法,即,使用卷积层最后一层做为人脸的“向量表示”,效果其实是不好的。如何改进?我们之后再谈,这里先谈谈我们希望这种人脸的“向量表示”应该具有哪些性质。
在理想的状况下,我们希望“向量表示”之间的距离就可以直接反映人脸的相似度:
对于同一个人的人脸图像,对应的向量的欧几里得距离应该比较小;
对于不同人的人脸图像,对应的向量之间的欧几里得距离应该比较大;
例如:设人脸图像为$x_1,x_2$,对应的特征为$f(x_1),f(x_2)$,当$x_1,x_2$对应是同一个人的人脸时,$f(x_1),f(x_2)$的距离$\|f(x_1)-f(x_2)\|_2$应该很小,而当$x_1,x_2$对应的不是同一个人的人脸时,$f(x_1),f(x_2)$的距离$\|f(x_1)-f(x_2)\|_2$应该很大。
在原始的VGG16模型中,我们使用的是softmax损失,softmax是类别间的损失,对于人脸来说,每一类就是一个人。尽管使用softmax损失可以区别每个人,但其本质上没有对每一类的向量表示之间的距离做出要求。
举个例子,使用CNN对MNIST进行分类,我们设计一个特殊的卷积网络,让最后一层的向量变为2维,此时可以画出每一类对应的2维向量表示的图(图中一种颜色对应一种类别):
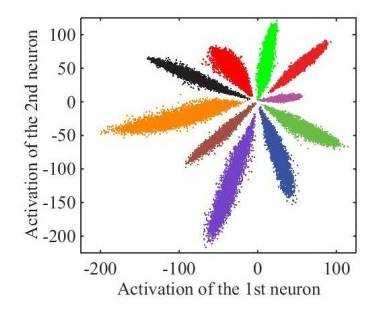
上图是我们直接使用softmax训练得到的结果,它就不符合我们希望特征具有的特点:
我们希望同一类对应的向量表示尽可能接近。但这里同一类(如紫色),可能具有很大的类间距离;
我们希望不同类对应的向量应该尽可能远。但在图中靠中心的位置,各个类别的距离都很近;
对于人脸图像同样会出现类似的情况,对此,有很改进方法。这里介绍其中两种:三元组损失函数,中心损失函数。
三元组损失函数的原理:既然目标是特征之间的距离应该具备某些性质,那么我们就围绕这个距离来设计损失。具体的,我们每次都在训练数据中抽出三张人脸图像,第一张图像标记为$x_i^a$,第二章图像标记为$x_i^p$,第三张图像标记为$x_i^n$。在这样一个"三元组"中,$x_i^a$和$x_i^p$对应的是同一个人的图像,而$x_i^n$是另外一个人的人脸图像。因此距离$\|f(x_i^a)-f(x_i^p)\|_2$应该很小,而距离$\|f(x_i^a)-f(x_i^n)\|_2$应该很大。严格来说,三元组损失要求满足以下不等式:
$$\|f(x_i^a)-f(x_i^p)\|_2^2+\alpha < \|f(x_i^a)-f(x_i^n)\|_2^2$$
即相同人脸间的距离平方至少要比不同人脸间的距离平方小$\alpha$(取平方主要是为了方便求导),据此,设计损失函数为:
$$L_i = [\|f(x_i^a)-f(x_i^p)\|_2^2+\alpha - \|f(x_i^a)-f(x_i^n)\|_2^2]_+$$
这样的话,当三元组的距离满足$\|f(x_i^a)-f(x_i^p)\|_2^2+\alpha < \|f(x_i^a)-f(x_i^n)\|_2^2$时,损失$L_i=0$。当距离不满足上述不等式时,就会有值为$\|f(x_i^a)-f(x_i^p)\|_2^2+\alpha - \|f(x_i^a)-f(x_i^n)\|_2^2$的损失,此外,在训练时会固定$\|f(x)\|_2=1$,以确保特征不会无限的"远离"。
三元组损失直接对距离进行优化,因此可以解决人脸的特征表示问题。但是在训练过程中,三元组的选择非常地有技巧性。如果每次都是随机选择三元组,虽然模型可以正确的收敛,但是并不能达到最好的性能。如果加入"难例挖掘",即每次都选择最难分辨率的三元组进行训练,模型又往往不能正确的收敛。对此,又提出每次都选择那些"半难"的数据进行训练,让模型在可以收敛的同时也保持良好的性能。此外,使用三元组损失训练人脸模型通常还需要非常大的人脸数据集,才能取得较好的效果。
与三元组损失不同,中心损失不直接对距离进行优化,它保留了原有的分类模型,但又为每个类(在人脸模型中,一个类就对应一个人)指定了一个类别中心。同一类的图像对应的特征都应该尽量靠近自己的类别中心,不同类的类别中心尽量远离。与三元组损失函数,使用中心损失训练人脸模型不需要使用特别的采样方法,而且利用较少的图像就可以达到与单元组损失相似的效果。下面我们一起来学习中心损失的定义:
设输入的人脸图像为$x_i$,该人脸对应的类别是$y_i$,对每个类别都规定一个类别中心,记作$c_{yi}$。希望每个人脸图像对应的特征$f(x_i)$都尽可能接近中心$c_{yi}$。因此定义损失函数为:
$$L_i=\frac{1}{2}\|f(x_i)-c_{yi}\|_2^2$$
多张图像的中心损失就是将它们的值累加:
$$L_{center}=\sum\limits_{i}L_i$$
这是一个非常简单的定义。不过还有一个问题没有解决,那就是如何确定每个类别的中心$c_{yi}$呢?从理论上来说,类别$y_i$的最佳中心应该是它对应所有图片的特征的平均值。但如果采用这样的定义,那么在每一次梯度下降时,都要对所有图片计算一次$c_{yi}$,计算复杂度太高了。针对这种情况,不妨近似处理下,在初始阶段,先随机确定$c_{yi}$,接着在每个batch内,使用$L_i=\|f(x_i)-c_{yi}\|_2^2$对当前batch内的$c_{yi}$也计算梯度,并使得该梯度更新$c_{yi}$,此外,不能只使用中心损失来训练分类模型,还需要加入softmax损失,也就是说,损失最后由两部分组成,即$L=L_{softmax}+\lambda{L_{center}}$,其中$\lambda$是一个超参数。
最后来总结使用中心损失来训练人脸模型的过程。首先随机初始化各个中心$c_{yi}$,接着不断地取出batch进行训练,在每个batch中,使用总的损失$L$,除了使用神经网络模型的参数对模型进行更新外,也对$c_{yi}$进行计算梯度,并更新中心的位置。
中心损失可以让训练处的特征具有"内聚性"。还是以MNIST的例子来说,在未加入中心损失时,训练的结果不具有内聚性。在加入中心损失后,得到的特征如下:
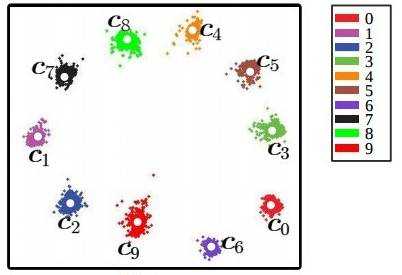
当中心损失的权重$\lambda$越大时,生成的特征就会具有越明显的"内聚性"。
先去GItHub下载facenet源码:https://github.com/davidsandberg/facenet,解压后如下图所示;
打开requirements.txt,我们可以看到我们需要安装以下依赖:
tensorflow==1.7 scipy scikit-learn opencv-python h5py matplotlib Pillow requests psutil
后面在运行程序时,如果出现安装包兼容问题,建议这里使用pip安装,不要使用conda。
将facebet文件夹加到python引入库的默认搜索路径中,将facenet文件整个复制到anaconda3安装文件目录下lib\site-packages下:
然后把剪切src目录下的文件,然后删除facenet下的所有文件,粘贴src目录下的文件到facenet下,这样做的目的是为了导入src目录下的包(这样import align.detect_face不会报错)。
在Anaconda Prompt中运行python,输入import facenet,不报错即可:

接下来将会讲解如何使用已经训练好的模型在LFW(Labeled Faces in the Wild)数据库上测试,不过我还需要先来介绍一下LFW数据集。
LFW数据集是由美国马赛诸塞大学阿姆斯特分校计算机实验室整理的人脸检测数据集,是评估人脸识别算法效果的公开测试数据集。LFW数据集共有13233张jpeg格式图片,属于5749个不同的人,其中有1680人对应不止一张图片,每张图片尺寸都是$250\times{250}$,并且被标示出对应的人的名字。LFW数据集中每张图片命名方式为"lfw/name/name_xxx.jpg",这里"xxx"是前面补零的四位图片编号。例如,前美国总统乔治布什的第十张图片为"lfw/George_W_Bush/George_W_Bush_0010.jpg"。
数据集的下载地址为:http://vis-www.cs.umass.edu/lfw/lfw.tgz,下载完成后,解压数据集,打开打开其中一个文件夹,如下:
在lfw下新建一个文件夹raw,把lfw中所有的文件(除了raw)移到raw文件夹中。可以看到我的数据集lfw是放在datasets文件夹下,其中datasets文件夹和facenet是在同一路径下。
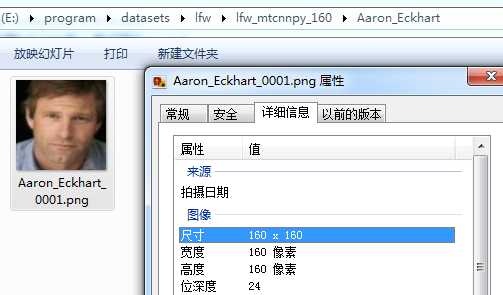
我们需要将检测所使用的数据集校准为和训练模型所使用的数据集大小一致($\160\times{160}$),转换后的数据集存储在lfw_mtcnnpy_160文件夹内,
处理的第一步是使用MTCNN网络进行人脸检测和对齐,并缩放到$160\times{160}$。
MTCNN的实现主要在文件夹facenet/src/align中,文件夹的内容如下:
使用脚本align_dataset_mtcnn.py对LFW数据库进行人脸检测和对齐的方法通过运行命令,我们打开Anaconda Prompt,来到facenet所在的路径下,运行如下命令:
python facenet/src/align/align_dataset_mtcnn.py datasets/lfw/raw datasets/lfw/lfw_mtcnnpy_160 --image_size 160 --margin 32 --random_order
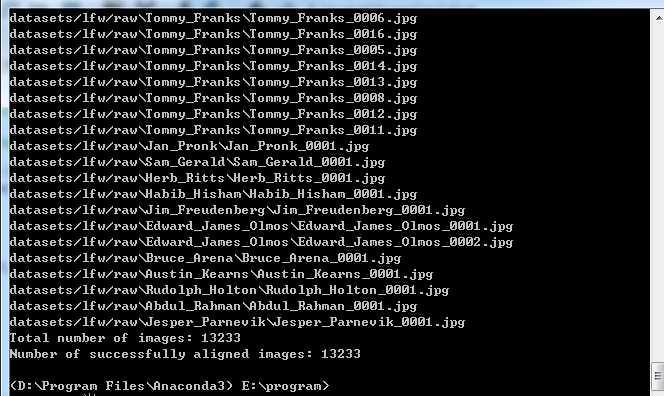
该命令会创建一个datasets/lfw/lfw_mtcnnpy_160的文件夹,并将所有对齐好的人脸图像存放到这个文件夹中,数据的结构和原先的datasets/lfw/raw一样。参数--image_size 160 --margin 32的含义是在MTCNN检测得到的人脸框的基础上缩小32像素(训练时使用的数据偏大),并缩放到$160\times{160}$大小,因此最后得到的对齐后的图像都是$160\times{160}$像素的,这样的话,就成功地从原始图像中检测并对齐了人脸。
下面我们来简略的分析一下align_dataset_mtcnn.py源文件,先上源代码如下:
标签:rgb style 含义 不同类 sort sample 最好 像素 速度
原文地址:https://www.cnblogs.com/zyly/p/9703614.html