标签:文件 EDA 程序 完整 人性 config 读写分离 nosql数据库 错误
本文介绍了热门的NoSQL数据库MongoDB的副本集这种分布式架构的一些概念和操作。主要内容包括:
MongoDB副本集相关概念
MongoDB副本集环境搭建
MongoDB副本集的读写分离
MongoDB副本集的故障转移
MongoDB副本集的优点
MongoDB副本集的缺点
1.副本集相关概念
主节点。
在一个副本集中,只有唯一一个主节点。主节点可以进行数据的写操作和读操作。副本集中各个节点的增伤改等配置必须在主节点进行。
从节点。
在一个副本集中,可以有一个或者多个从节点。从节点只允许读操作,不允许写操作。在主节点宕机后,会自动在从节点中产生一个新的主节点。
仲裁者。
在一个副本集中,仲裁者节点不保存数据,既不能读数据,也不能写数据。作用仅仅限于在从从节点选举主节点时担任仲裁作用。
副本集的工作原理。
(i)副本集中的主节点的oplog集合中记录了主节点中所有引起数据变化的变更操作,包括更新和插入数据。副本集中的从节点从主节点的oplog集合中复制这些操作,从而在从节点上重现这些操作。这就是副本集的数据同步的基本原理。
(ii)在 oplog集合中的每个记录都是有一个时间戳,从节点据此判断需要更新哪些数据。主节点的local数据库中的数据不会被复制到从节点上。
(iii)对于主节点而言,这些复制操作时异步进行的,相当于MySQL数据库中的异步复制模式,即主节点在写入数据时无需等待任何从节点复制操作完成,即可进行其它数据的写入操作。
(iv)从节点第1次同步时会做完整的数据同步,后续通常只做一部分最新数据的同步工作。当时当从节点复制延迟太大时会重新进行完整的数据同步。因为oplog集合是一个固定集合,即里面的文档数量的大小是有固定的限制的,不能超过某个大小。因此,当主节点上oplog集合写满了后,会清空这个oplog集合。如果在写满oplog之前,从节点没有跟上这个速度,则无法再利用oplog进行增量复制工作,这就是需要完整的数据同步的原因。
(v)数据回滚。
在主节点宕机后自动产生了新的主节点,这时整个副本集认为这个新的主节点的数据是最新的有效数据。如果其他从节点中的数据复制进度超过了这个心的主节点的进度,那么这些从节点将会自动回滚这些超过新主节点的数据。这个操作就是Mongodb中的数据回滚。
2.副本集环境搭建
现在通过在一台机器(Centos7)上部署三个mongodb节点,从而搭建一个最简单的mongodb副本集环境。
端口27017 主节点
端口27018 从节点
端口27019 仲裁节点
假定mongodb相关软件包已经安装完毕。
(1)首先建立如下图的目录结构,其中data和log都是空目录。
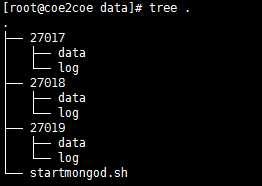
图1
建立如下所示的脚本文件,用于快速启动这3个节点。
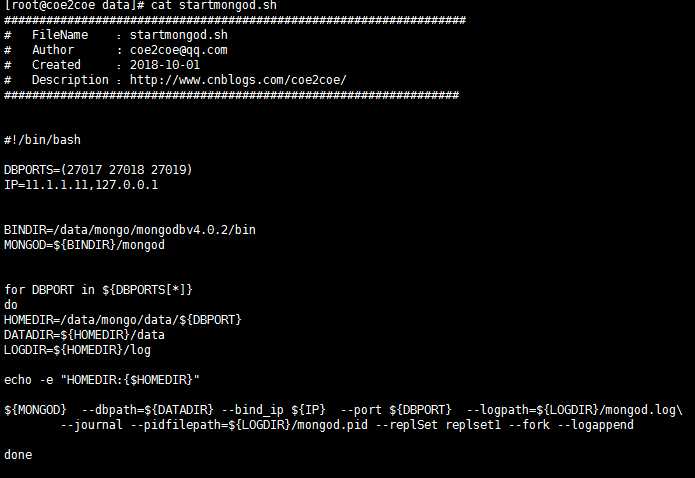
图2
启动3个节点。
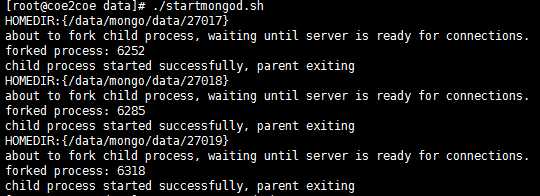
图3
配置副本集。
连接到主节点27017上,然后初始化副本集并且将另外的一个从节点27018和一个仲裁者节点27019加入到副本集中。
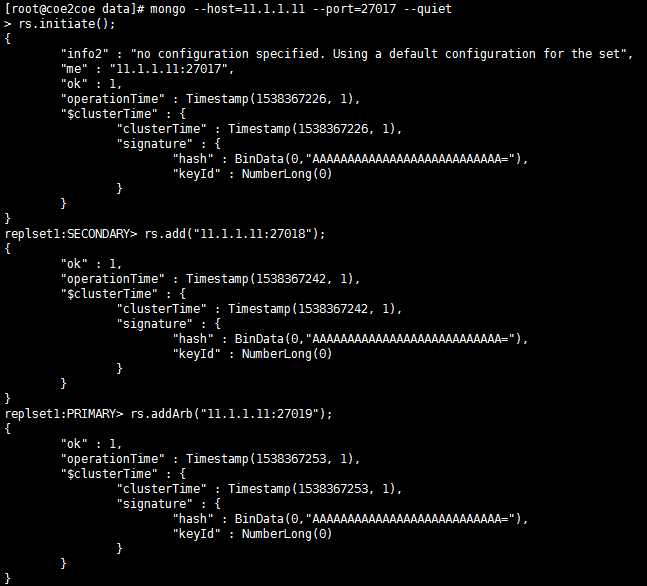
图4
查看副本集状态。
replset1:PRIMARY> rs.status();
{
"set" : "replset1",
"date" : ISODate("2018-10-01T04:14:17.567Z"),
"myState" : 1,
"term" : NumberLong(1),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"appliedOpTime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
}
},
"lastStableCheckpointTimestamp" : Timestamp(1538367228, 4),
"members" : [
{
"_id" : 0,
"name" : "11.1.1.11:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 260,
"optime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2018-10-01T04:14:13Z"),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "could not find member to sync from",
"electionTime" : Timestamp(1538367226, 2),
"electionDate" : ISODate("2018-10-01T04:13:46Z"),
"configVersion" : 3,
"self" : true,
"lastHeartbeatMessage" : ""
},
{
"_id" : 1,
"name" : "11.1.1.11:27018",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 14,
"optime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2018-10-01T04:14:13Z"),
"optimeDurableDate" : ISODate("2018-10-01T04:14:13Z"),
"lastHeartbeat" : ISODate("2018-10-01T04:14:17.405Z"),
"lastHeartbeatRecv" : ISODate("2018-10-01T04:14:16.418Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "11.1.1.11:27017",
"syncSourceHost" : "11.1.1.11:27017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 3
},
{
"_id" : 2,
"name" : "11.1.1.11:27019",
"health" : 1,
"state" : 7,
"stateStr" : "ARBITER",
"uptime" : 4,
"lastHeartbeat" : ISODate("2018-10-01T04:14:17.405Z"),
"lastHeartbeatRecv" : ISODate("2018-10-01T04:14:17.424Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"configVersion" : 3
}
],
"ok" : 1,
"operationTime" : Timestamp(1538367253, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1538367253, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
副本集中三个节点的状态应该是:
端口
节点
状态
27017
主节点
1,PRIMARY
27018
从节点
2,SECONDARY
27019
仲裁节点
7,ARBITER
3.副本集的读写分离
在Mongodb副本集中,主节点负责数据的全部写入操作,也可以读取数据。从节点只能读取数据,而仲裁节点不能读和写数据。
因此,在主节点27017上可以进行数据的读取和写入操作。
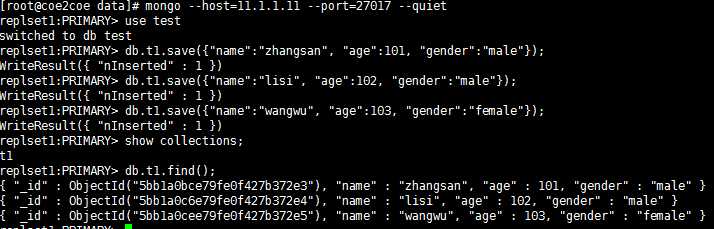
图5
但是这个时候从节点上并没有真正的成为这个副本集的正式成员。在从节点执行任何有关数据的操作将会产生一个错误:
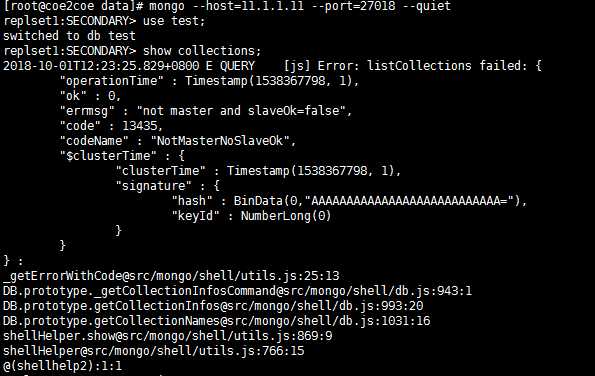
图6
只需要在从节点上执行一下这个而操作即可解决问题:

图7
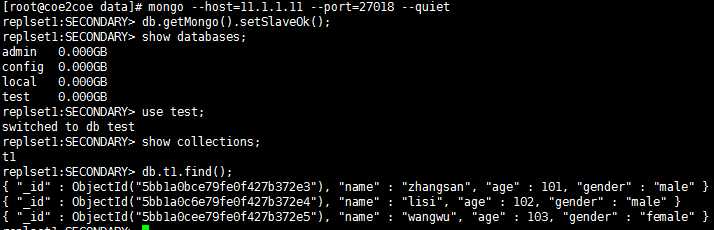
图8
在仲裁者节点上同样需要执行类似的操作,但是仲裁者节点是不保存副本集中的数据的。
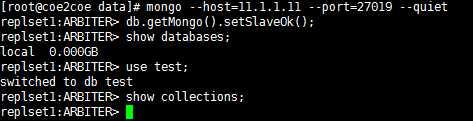
图9
在从节点或者仲裁者节点上写入数据将会失败。
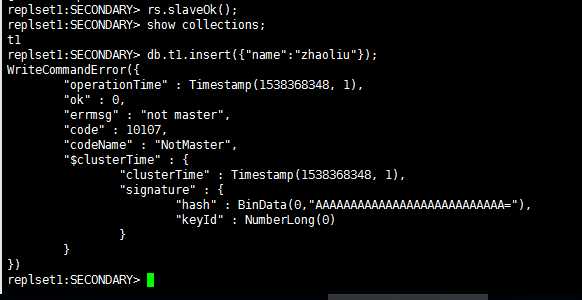
图10
4.副本集的故障转移
现在通过将副本集中的主节点27017节点停止运行来演示mongodb副本集的故障转移功能。
(1)停止主节点27017。
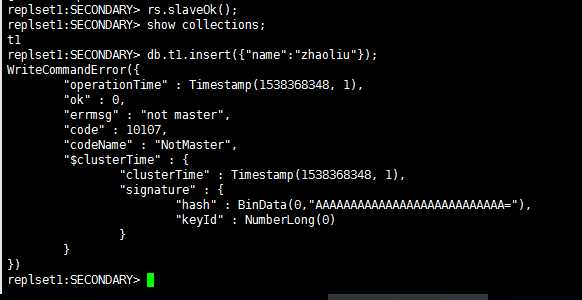 图1
图1
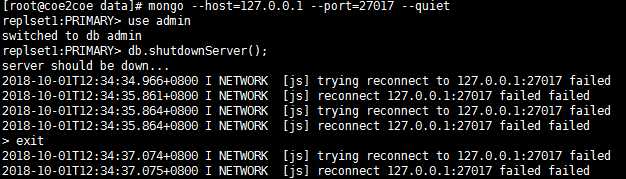
图11
查看节点状态。
此时原来的主节点27017处于不可用状态,而原来的从节点27018节点成为了新的主节点。

图12
三个节点的新状态如下所示:
端口
节点
状态
27017
主节点
8,(not reachable/healthy)
27018
从节点
1,PRIMARY
27019
仲裁节点
7,ARBITER
因为27018节点成为了新的主节点,因此可以进行写数据的操作了。
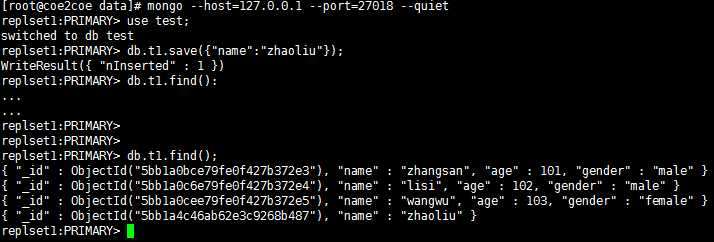
图13
在重新启动27017节点后发现这个原来的主节点成为了从节点。

图14
至此,Mongodb的副本集方式的集群部署成功。
4.副本集的优点
(1)部署简单。
Mongodb的副本集方式的集群,相对于MySQL的MHA或者MM方式的集群而言,部署方面简单,仅仅使用Mongodb官方软件的内置功能进行安装部署,不需要第三方的脚本或者软件即可完成部署。
(2)故障转移后,主节点的IP地址发生变化。因此需要客户端程序来处理这种IP变化。Mongodb的java客户端 SDK正好提供了这种功能,因此只需要将一个副本集中的主节点和全部从节点都加入到连接地址中即可自动完成这种读写分离和故障转移的功能,即不需要程序员自己写代码来检测和判断副本集中节点的状态。
Mongodb的副本集的Java SDK和Redis Cluster的Java SDK对于故障转移的自动化处理方式,都相当的人性化。
5.副本集的缺点
Mongodb的副本集方式的集群架构有如下的缺点:
(1)整个集群中只有一个主节点。因此写操作集中于某一个节点上,无法进行对写操作的负载均衡。
标签:文件 EDA 程序 完整 人性 config 读写分离 nosql数据库 错误
原文地址:https://www.cnblogs.com/coe2coe/p/9734596.html