一 介绍
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
1、安装
pip3 install sqlalchemy
2、架构与流程
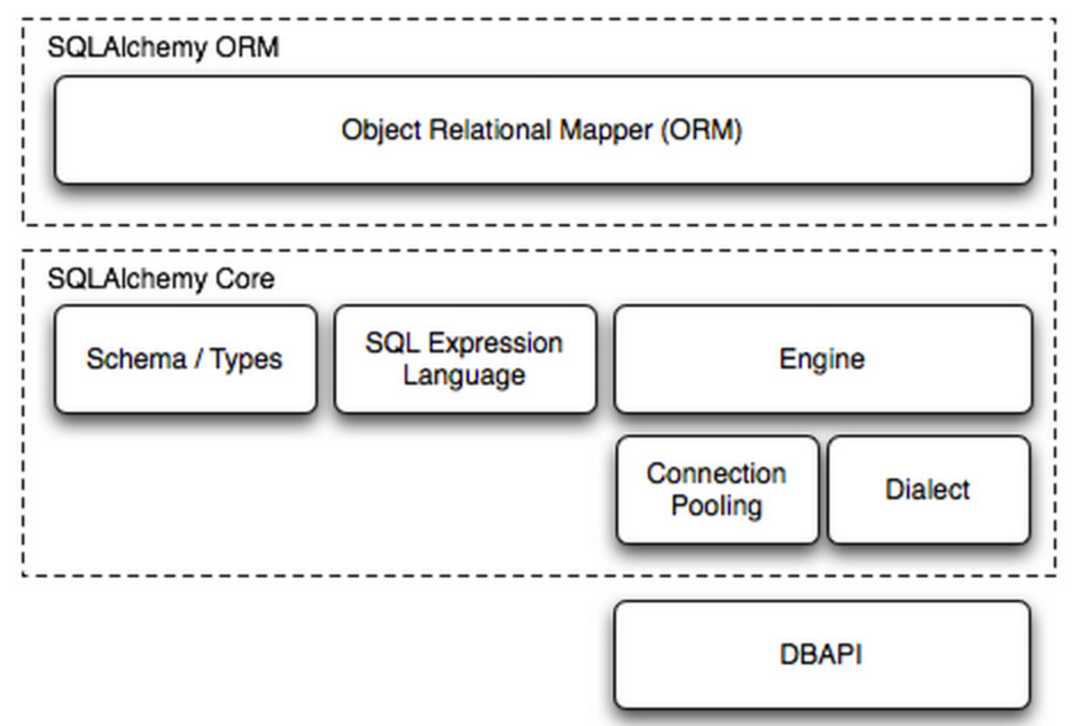
#1、使用者通过ORM对象提交命令 #2、将命令交给SQLAlchemy Core(Schema/Types SQL Expression Language)转换成SQL #3、使用 Engine/ConnectionPooling/Dialect 进行数据库操作 #3.1、匹配使用者事先配置好的egine #3.2、egine从连接池中取出一个链接 #3.3、基于该链接通过Dialect调用DB API,将SQL转交给它去执行
!!!上述流程分析,可以大致分为两个阶段!!!:
#第一个阶段(流程1-2):将SQLAlchemy的对象换成可执行的sql语句 #第二个阶段(流程3):将sql语句交给数据库执行
如果我们不依赖于SQLAlchemy的转换而自己写好sql语句,那是不是意味着可以直接从第二个阶段开始执行了,事实上正是如此,我们完全可以只用SQLAlchemy执行纯sql语句,如下


from sqlalchemy import create_engine #1 准备 # 需要事先安装好pymysql # 需要事先创建好数据库:create database db1 charset utf8; #2 创建引擎 egine=create_engine(‘mysql+pymysql://root@127.0.0.1/db1?charset=utf8‘) #3 执行sql # egine.execute(‘create table if not EXISTS t1(id int PRIMARY KEY auto_increment,name char(32));‘) # cur=egine.execute(‘insert into t1 values(%s,%s);‘,[(1,"egon1"),(2,"egon2"),(3,"egon3")]) #按位置传值 # cur=egine.execute(‘insert into t1 values(%(id)s,%(name)s);‘,name=‘egon4‘,id=4) #按关键字传值 #4 新插入行的自增id # print(cur.lastrowid) #5 查询 cur=egine.execute(‘select * from t1‘) cur.fetchone() #获取一行 cur.fetchmany(2) #获取多行 cur.fetchall() #获取所有行
3、DB API
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:

#1、MySQL-Python mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> #2、pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] #3、MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> #4、cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
二 创建表
ORM中:
#类===>表 #对象==>表中的一行记录
四张表:业务线,服务,用户,角色,利用ORM创建出它们,并建立好它们直接的关系
View Code注:设置外键的另一种方式 ForeignKeyConstraint([‘other_id‘], [‘othertable.other_id‘])
三 增删改查
表结构
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer,String,ForeignKey from sqlalchemy.orm import sessionmaker egine=create_engine(‘mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8‘,max_overflow=5) Base=declarative_base() #多对一:假设多个员工可以属于一个部门,而多个部门不能有同一个员工(只有创建公司才把员工当骆驼用,一个员工身兼数职) class Dep(Base): __tablename__=‘dep‘ id=Column(Integer,primary_key=True,autoincrement=True) dname=Column(String(64),nullable=False,index=True) class Emp(Base): __tablename__=‘emp‘ id=Column(Integer,primary_key=True,autoincrement=True) ename=Column(String(32),nullable=False,index=True) dep_id=Column(Integer,ForeignKey(‘dep.id‘)) def init_db(): Base.metadata.create_all(egine) def drop_db(): Base.metadata.drop_all(egine) drop_db() init_db() Session=sessionmaker(bind=egine) session=Session()
增
#增 row_obj=Dep(dname=‘销售‘) #按关键字传参,无需指定id,因其是自增长的 session.add(row_obj) session.add_all([ Dep(dname=‘技术‘), Dep(dname=‘运营‘), Dep(dname=‘人事‘), ]) session.commit()
删
#删 session.query(Dep).filter(Dep.id > 3).delete() session.commit()
改
#改 session.query(Dep).filter(Dep.id > 0).update({‘dname‘:‘哇哈哈‘}) session.query(Dep).filter(Dep.id > 0).update({‘dname‘:Dep.dname+‘_SB‘},synchronize_session=False) session.query(Dep).filter(Dep.id > 0).update({‘id‘:Dep.id*100},synchronize_session=‘evaluate‘) session.commit()
查
#查所有,取所有字段 res=session.query(Dep).all() #for row in res:print(row.id,row.dname) #查所有,取指定字段 res=session.query(Dep.dname).order_by(Dep.id).all() #for row in res:print(row.dname) res=session.query(Dep.dname).first() print(res) # (‘哇哈哈_SB‘,) #过滤查 res=session.query(Dep).filter(Dep.id > 1,Dep.id <1000) #逗号分隔,默认为and print([(row.id,row.dname) for row in res])
四 其他查询相关
一 准备表和数据
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer,String,ForeignKey from sqlalchemy.orm import sessionmaker egine=create_engine(‘mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8‘,max_overflow=5) Base=declarative_base() #多对一:假设多个员工可以属于一个部门,而多个部门不能有同一个员工(只有创建公司才把员工当骆驼用,一个员工身兼数职) class Dep(Base): __tablename__=‘dep‘ id=Column(Integer,primary_key=True,autoincrement=True) dname=Column(String(64),nullable=False,index=True) class Emp(Base): __tablename__=‘emp‘ id=Column(Integer,primary_key=True,autoincrement=True) ename=Column(String(32),nullable=False,index=True) dep_id=Column(Integer,ForeignKey(‘dep.id‘)) def init_db(): Base.metadata.create_all(egine) def drop_db(): Base.metadata.drop_all(egine) drop_db() init_db() Session=sessionmaker(bind=egine) session=Session() # 准备数据 session.add_all([ Dep(dname=‘技术‘), Dep(dname=‘销售‘), Dep(dname=‘运营‘), Dep(dname=‘人事‘), ]) session.add_all([ Emp(ename=‘林海峰‘,dep_id=1), Emp(ename=‘李杰‘,dep_id=1), Emp(ename=‘武配齐‘,dep_id=1), Emp(ename=‘元昊‘,dep_id=2), Emp(ename=‘李钢弹‘,dep_id=3), Emp(ename=‘张二丫‘,dep_id=4), Emp(ename=‘李坦克‘,dep_id=2), Emp(ename=‘王大炮‘,dep_id=4), Emp(ename=‘牛榴弹‘,dep_id=3) ]) session.commit()
二 条件、通配符、limit、排序、分组、连表、组合
#一、条件 sql=session.query(Emp).filter_by(ename=‘林海峰‘) #filter_by只能传参数:什么等于什么 res=sql.all() #sql语句的执行结果 res=session.query(Emp).filter(Emp.id>0,Emp.ename == ‘林海峰‘).all() #filter内传的是表达式,逗号分隔,默认为and, res=session.query(Emp).filter(Emp.id.between(1,3),Emp.ename == ‘林海峰‘).all() res=session.query(Emp).filter(Emp.id.in_([1,3,99,101]),Emp.ename == ‘林海峰‘).all() res=session.query(Emp).filter(~Emp.id.in_([1,3,99,101]),Emp.ename == ‘林海峰‘) #~代表取反,转换成sql就是关键字not from sqlalchemy import and_,or_ res=session.query(Emp).filter(and_(Emp.id > 0,Emp.ename==‘林海峰‘)).all() res=session.query(Emp).filter(or_(Emp.id < 2,Emp.ename==‘功夫熊猫‘)).all() res=session.query(Emp).filter( or_( Emp.dep_id == 3, and_(Emp.id > 1,Emp.ename==‘功夫熊猫‘), Emp.ename != ‘‘ ) ).all() #二、通配符 res=session.query(Emp).filter(Emp.ename.like(‘%海_%‘)).all() res=session.query(Emp).filter(~Emp.ename.like(‘%海_%‘)).all() #三、limit res=session.query(Emp)[0:5:2] #四、排序 res=session.query(Emp).order_by(Emp.dep_id.desc()).all() res=session.query(Emp).order_by(Emp.dep_id.desc(),Emp.id.asc()).all() #五、分组 from sqlalchemy.sql import func res=session.query(Emp.dep_id).group_by(Emp.dep_id).all() res=session.query( func.max(Emp.dep_id), func.min(Emp.dep_id), func.sum(Emp.dep_id), func.avg(Emp.dep_id), func.count(Emp.dep_id), ).group_by(Emp.dep_id).all() res=session.query( Emp.dep_id, func.count(1), ).group_by(Emp.dep_id).having(func.count(1) > 2).all() #六、连表 #笛卡尔积 res=session.query(Emp,Dep).all() #select * from emp,dep; #where条件 res=session.query(Emp,Dep).filter(Emp.dep_id==Dep.id).all() # for row in res: # emp_tb=row[0] # dep_tb=row[1] # print(emp_tb.id,emp_tb.ename,dep_tb.id,dep_tb.dname) #内连接 res=session.query(Emp).join(Dep) #join默认为内连接,SQLAlchemy会自动帮我们通过foreign key字段去找关联关系 #但是上述查询的结果均为Emp表的字段,这样链表还有毛线意义,于是我们修改为 res=session.query(Emp.id,Emp.ename,Emp.dep_id,Dep.dname).join(Dep).all() #左连接:isouter=True res=session.query(Emp.id,Emp.ename,Emp.dep_id,Dep.dname).join(Dep,isouter=True).all() #右连接:同左连接,只是把两个表的位置换一下 #七、组合 q1=session.query(Emp.id,Emp.ename).filter(Emp.id > 0,Emp.id < 5) q2=session.query(Emp.id,Emp.ename).filter( or_( Emp.ename.like(‘%海%‘), Emp.ename.like(‘%昊%‘), ) ) res1=q1.union(q2) #组合+去重 res2=q1.union_all(q2) #组合,不去重 print([i.ename for i in q1.all()]) #[‘林海峰‘, ‘李杰‘, ‘武配齐‘, ‘元昊‘] print([i.ename for i in q2.all()]) #[‘林海峰‘, ‘元昊‘] print([i.ename for i in res1.all()]) #[‘林海峰‘, ‘李杰‘, ‘武配齐‘, ‘元昊‘] print([i.ename for i in res2.all()]) #[‘林海峰‘, ‘李杰‘, ‘武配齐‘, ‘元昊‘, ‘元昊‘, ‘林海峰‘]
三 子查询
有三种形式的子查询,注意:子查询的sql必须用括号包起来,尤其在形式三中需要注意这一点
#示例:查出id大于2的员工,当做子查询的表使用 #原生SQL: # select * from (select * from emp where id > 2); #ORM: res=session.query( session.query(Emp).filter(Emp.id > 8).subquery() ).all()
#示例:#查出销售部门的员工姓名 #原生SQL: # select ename from emp where dep_id in (select id from dep where dname=‘销售‘); #ORM: res=session.query(Emp.ename).filter(Emp.dep_id.in_( session.query(Dep.id).filter_by(dname=‘销售‘), #传的是参数 # session.query(Dep.id).filter(Dep.dname==‘销售‘) #传的是表达式 )).all()
#示例:查询所有的员工姓名与部门名 #原生SQL: # select ename as 员工姓名,(select dname from dep where id = emp.dep_id) as 部门名 from emp; #ORM: sub_sql=session.query(Dep.dname).filter(Dep.id==Emp.dep_id) #SELECT dep.dname FROM dep, emp WHERE dep.id = emp.dep_id sub_sql.as_scalar() #as_scalar的功能就是把上面的sub_sql加上了括号 res=session.query(Emp.ename,sub_sql.as_scalar()).all()
五 正查、反查
一 表修改
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer,String,ForeignKey from sqlalchemy.orm import sessionmaker,relationship egine=create_engine(‘mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8‘,max_overflow=5) Base=declarative_base() class Dep(Base): __tablename__=‘dep‘ id=Column(Integer,primary_key=True,autoincrement=True) dname=Column(String(64),nullable=False,index=True) class Emp(Base): __tablename__=‘emp‘ id=Column(Integer,primary_key=True,autoincrement=True) ename=Column(String(32),nullable=False,index=True) dep_id=Column(Integer,ForeignKey(‘dep.id‘)) #在ForeignKey所在的类内添加relationship的字段,注意: #1:Dep是类名 #2:depart字段不会再数据库表中生成字段 #3:depart用于Emp表查询Dep表(正向查询),而xxoo用于Dep表查询Emp表(反向查询), depart=relationship(‘Dep‘,backref=‘xxoo‘) def init_db(): Base.metadata.create_all(egine) def drop_db(): Base.metadata.drop_all(egine) drop_db() init_db() Session=sessionmaker(bind=egine) session=Session() # 准备数据 session.add_all([ Dep(dname=‘技术‘), Dep(dname=‘销售‘), Dep(dname=‘运营‘), Dep(dname=‘人事‘), ]) session.add_all([ Emp(ename=‘林海峰‘,dep_id=1), Emp(ename=‘李杰‘,dep_id=1), Emp(ename=‘武配齐‘,dep_id=1), Emp(ename=‘元昊‘,dep_id=2), Emp(ename=‘李钢弹‘,dep_id=3), Emp(ename=‘张二丫‘,dep_id=4), Emp(ename=‘李坦克‘,dep_id=2), Emp(ename=‘王大炮‘,dep_id=4), Emp(ename=‘牛榴弹‘,dep_id=3) ]) session.commit()
二 标准连表查询
# 示例:查询员工名与其部门名 res=session.query(Emp.ename,Dep.dname).join(Dep) #迭代器 for row in res: print(row[0],row[1]) #等同于print(row.ename,row.dname)
三 基于relationship的正查、反查
#SQLAlchemy的relationship在内部帮我们做好表的链接 #查询员工名与其部门名(正向查) res=session.query(Emp) for row in res: print(row.ename,row.id,row.depart.dname) #查询部门名以及该部门下的员工(反向查) res=session.query(Dep) for row in res: # print(row.dname,row.xxoo) print(row.dname,[r.ename for r in row.xxoo])