标签:target 分组 表达 应用 server bre 详情 内容 意思
shell命令行的解析原理(单双无引号与字符及通配符的关系):http://www.cnblogs.com/f-ck-need-u/p/7426371.html
正则表达式里是如何表达字符集:https://www.cnblogs.com/f-ck-need-u/p/9621130.html
grep的应用:https://www.cnblogs.com/f-ck-need-u/p/7462706.html
sed的应用:https://www.cnblogs.com/f-ck-need-u/p/7499471.html
传闻中三剑侠的威名响彻云霄,传说中若没有正则表达式的神功,三剑侠也是芸芸众生,江湖中传言"欲成剑侠,先练神功",不管传说或传闻我都信。
度度果然不是盖的,一下就拔出了正则的历史,不看不知道,一看就大有来头,大约就是国外几位猛人科学家在搞一个伟大的工程时诞生了正则数学表达式,随后被目光深远的Ken,将这正则表达式引入于Unix的编辑器中。后面的事情大家都很清楚了,三剑侠大闹搜索界,传说由此开始,而故事远远没有落幕,......
从正则的历史中,可以看出正则表达式对英文是100%的原生,也就是为英文的而生(会不会因英文而灭,不好说,或许明天你就嫁给我了,会有中文的笔画正则也说不定,拼音正则也行),主要应用于按某规则搜索匹对英文中的内容,所以对英文的26个字母不熟悉的同志要努力下了(俺初中英语非常6,所以这26个英文字母,蒙着眼睛也知道谁是谁,谁跟谁,一点不模糊。),那么对英文的结构,就需要了解下,英文单词由英文字母排列组合并以空格来分隔每一个单词,这个就是我们下工夫及体会的本质(英文字母,单词[ 每个字母所在的位置决定了单词意义 ],空格构成英语文本的三剑豪)。
对所爱,要重复大声说:trust me , I love you
1 字符(我思故我在,能想的,都是字符)
2 字母的不同排序组合构成不同的单词
3 空格分隔单词(只要有某字符分隔单词,采用什么字符都可以)
图解正则表达式的对英语文本的看法
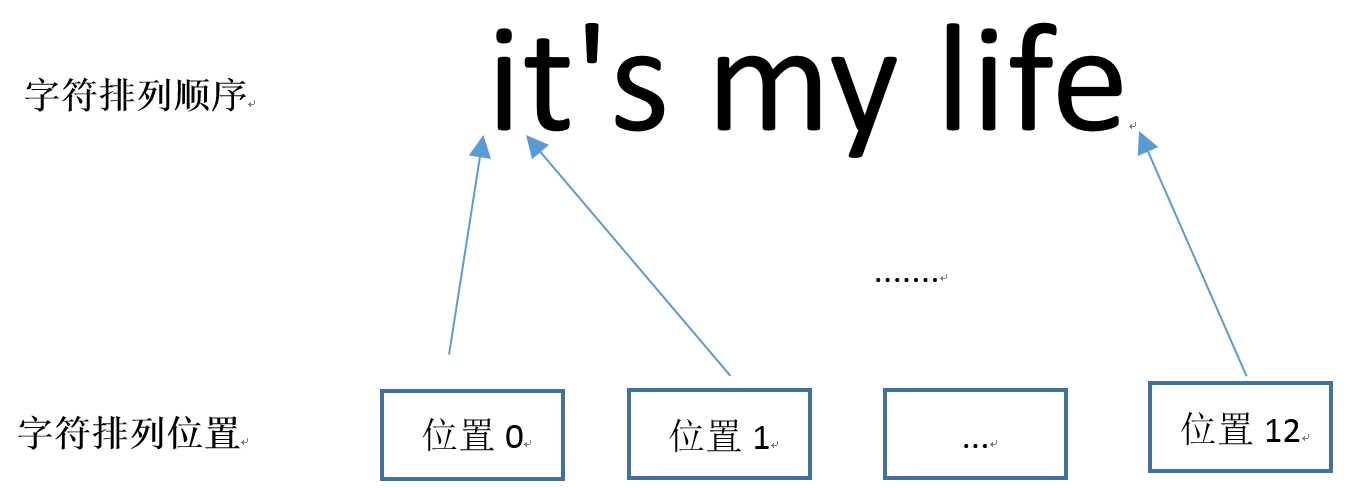
| 字符 | I | 空格 | l | o | v | e | 空格 | u | |||||||||
| 位置 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
对英文(其他字符集)搜索的两种模式(字符[ 组合 ]位置,字符[ 组合 ]的排序)
字符 [ 组合 ] 位置搜索方式
位置搜索方式比较单一,目的是确定字符(单词)在整行字符排列位置上,常用^来表示字符(单词)在一行文本的最开始位置(一行的顶格位置), $ 来表示字符(单词)在一行文本的最末尾的位置(一行的最末尾位置),任意单字符*表示所有的位置,\b作用就是单词与单词之间的位置,\B作用就是某单词内字母与字母之间的位置,这两个大小傻B不能用说,要直接上才明白。
这里有个知识点,就是shell的通配符及单引号、双引号、无引号与正则表达的元字符的应用
shell 命令行输入命令且回车 --> shell会对输入命令及参数进行解析 (为了让你的意图能正确到达正则,了解shell的解析是必要的)--> 正则表达式解析工作
| ^、$、任意字符* |
* 表示重复前一个字符(单词)0~无限次,当等于0的情况,z*就表示位置了(其中z可以是任意的字符)。 通过sed的替换,将一句话的所有位置都替换6,替换后的位置比之前的位置又扩容了。 |
[root@server01 ~]# echo "It‘s my life.It‘s my life." | grep --color ‘It‘
It‘s my life.It‘s my life.
|
[root@server01 ~]# echo "It‘s my life.It‘s my life." | sed ‘s/z*/6/g‘
6I6t6‘6s6 6m6y6 6l6i6f6e6.6I6t6‘6s6 6m6y6 6l6i6f6e6.6
|
[root@server01 ~]# echo "It‘s my life.It‘s my life." | grep --color ‘fe\.$‘
It‘s my life.It‘s my life.
|
[root@server01 ~]# echo "It‘s my life.It‘s my life." | sed -r ‘s/(yf)*$/6/g‘
It‘s my life.It‘s my life.6
|
| \B、\b | |
| \B:一单词内的字母,不含首或尾字母(组合) | \b:单词与单词之间的分隔,以单词的首或尾字母(组合)及非\w字符来明确分隔。注意要明确是你认为的单词 |
[root@server01 ~]# echo ‘live love life ifthen thenif‘ |grep --color ‘\Bi\B‘
live love life ifthen thenif
[root@server01 ~]#
|
[root@server01 ~]# echo ‘live love life left list‘ |grep --color ‘\bl\w\+e\b‘
live love life left list
[root@server01 ~]#
|
|
常用的组合: ^$ 表示空行。第一个位置同时是开始也是结束。 |
[root@server01 ~]# echo ‘live love life left list‘ |grep --color ‘\bl.*\+e\b‘
live love life left list
[root@server01 ~]#
注意: \bl.*\+e\b 的写法是认为"live love life"是一个整体,可以理解为一个单词,因为.*的意思是表示所有的字符 \bl\w\+\e\b 的写法是认为live love life 是三个词。
[root@server01 ~]# echo ‘live,love-life;left:list‘ |grep --color ‘\bl\w\+e\b‘ live,love-life;left:list [root@server01 ~]#
|
字符 [ 组合 ] 的排序搜索方式
这个相对比中文的笔画组合要好很多了,欲知详情(正则的元字符用法)请点击文章首部的相关文件推荐,我只做一下分类总结(没法子,功力不足,小弟我目前只站在他们的脚尖上。)。
由于英文单词由字母组成,所以字母对单词的特性就显现出现了,如在一个单词中,某字母或某组字母出现的次数、自定义范围内的字符、各种字符的分类。无论如何捣鼓,都是人类书写的习惯。放大招如下表:
| shell通配符 | 正则表达式元字符 | |||||
| 说明 | 数量 | 符号 | 数量 | 说明 | 特点 | 所属 |
| 任意字符及数量 | 0 ~ 无限个 | * | 0~ 无限 | 对前一个字符或一组字符定义至少重复出现的次数范围0~无限次 | 数量类 | 基础正则 |
| . | 1 | 一个任意的字符 | 数量类 | 基础正则 | ||
| + | 1 ~ 无限 | 对前一个字符或一组字符定义至少重复出现的次数范围1~无限次 | 数量类 | 扩展正则 | ||
| 一个任意的字符 | 1 | ? | 0 ~ 1 | 对前一个字符或一组字符定义至少出现0或1次 | 数量类 | 扩展正则 |
| {n,m} | n ~ m | 对前一个字符或一组字符定义至少重复出现的次数范围n~m次 | 数量类 | 扩展正则 | ||
| {n,} | n~ 无限 | 对前一个字符或一组字符定义至少重复出现的次数范围n~无限次 | 数量类 | 扩展正则 | ||
| {,m} | 0~m次 | 对前一个字符或一组字符定义至少重复出现的次数范围0-m次 | 数量类 | 扩展正则 | ||
| {m} | m | 对前一个字符或一组字符定义重复出现m次 | 数据类 | 扩展正则 | ||
|
touch {1..2}.txt touch {a..c}.txt |
序列1 ~ 序列2 | { 序列1..序列2 } | ||||
| [ 字符1 ... 字符n ] | 1 |
中括号内的任意一个字符 [a-z] 表示小写字母的任意一个 [A-Z] 表示大写字母的任意一个 [0-9] 表示数字的任意一个 [^0-9] 表示任意一个字符但不能是数字 [i s,_-] 表示只能是字母i,s,空格,逗号,减号中的任意一个 |
范围类 (集合类) |
基础正则 | ||
| [:alpha:] | 1 |
等价于[a-zA-Z],即是26个大小写英文字母 调用方式 [[:alpha:]] |
字符分类 | 基础正则 | ||
| 其余的字符分类 |
其他[:系列:]的,到推荐的文章或度一下就有一吨粮食了。 |
字符分类 | 基础正则 | |||
| \W |
1 |
非\w的所有可见或不可见的任意字符 |
字符分类 |
基础正则 | ||
| \w | 1 | 大小写英文字母,数字,下划线 |
字符分类 |
基础正则 | ||
| \S | 1 | 任意一个可见的字符(理解用笔在纸上能写出的符号都是可见) |
字符分类 |
基础正则 | ||
| \s | 1 | 非可写的字符(理解无需用笔在纸上写出的字符,如空格) |
字符分类 |
基础正则 | ||
| ^ | 位置类 | 基础正则 | ||||
| 获取变量值 | $ | 位置类 | 基础正则 | |||
| \b | \< 单词首 ;\> 单词尾,使用方式与 \b 基本一致 | 位置类 | 基础正则 | |||
| \B | 位置类 | 基础正则 | ||||
| 字符或组 | 字符或组 | 1 | 左边或右边的字符或一组字符只能出现其一 | 2选1 | 扩展正则 | ||
| (1或多个字符) | 1 |
功能一:将括号里面的字符组成一组 功能二:可以给某些搜索命令(sed,grep)做反向引用 |
分组 | 扩展正则 | ||
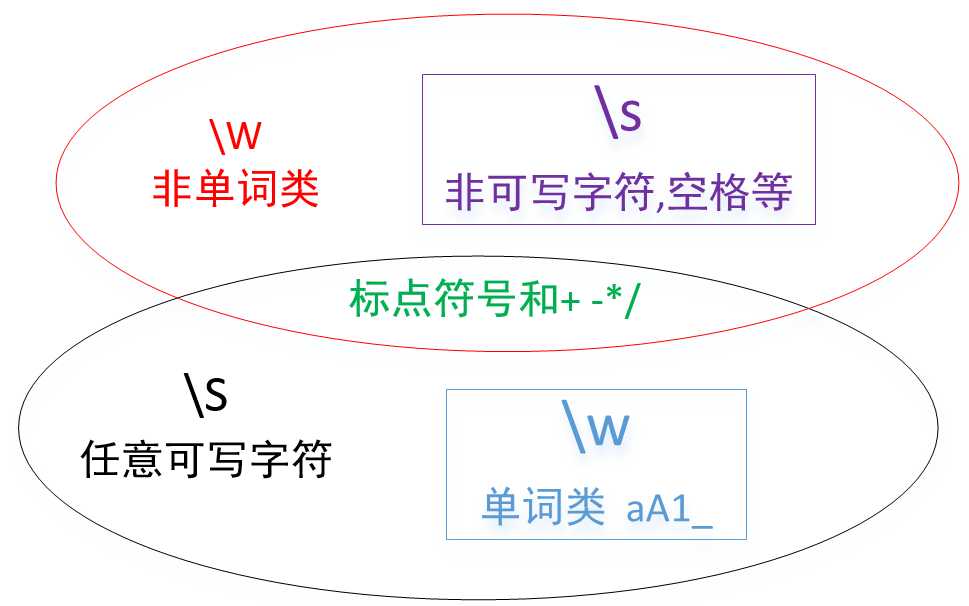
\W,\S,\w,\s,及其他的字符分类都很好用。下图是关于大S配小w,小S配大W的人脉关系图。
正则表达式工作写真
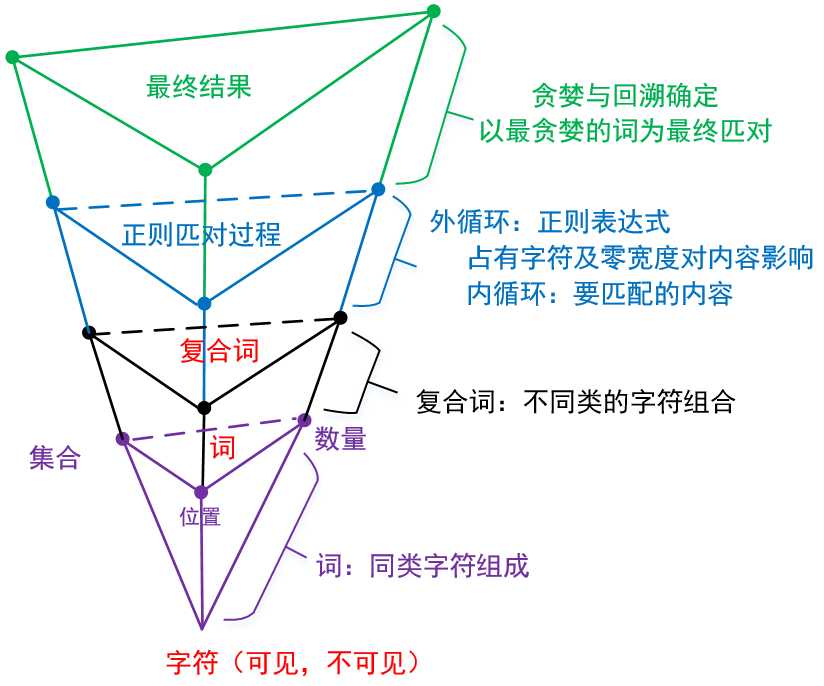
| 正则的工作原理概念模型 |
可以在度度找一下RegexBuddy 这个正则软件,能反映出正则表达式匹对内容大约需要多少次,正则表达式的性能调优参考 |
 |
举例:http://www.oldboyedu.com:80/html/html-tutorial.html 提取:http,www.oldboyedu.com,80,/html/html-tutorial.html,四段内容 分析:该url是一个复合词(字母数字标点符号混合),从要求中,发现有两个词是同类词, 一个是http,一个是80,另两个是复合词,一个是字母与点号,一个是字母斜线减号点号组成。其中,:或//要去掉 基本思路,使用二选一的方式,将二选一变成多选 基础解题关键:如何将内容分解对应的词或复合词 1:同类词http、80,是同属一类字符 --> \w+ 或 [a-z0-9]+ 就可以轻松啪它下来了 2:复合词www.oldboyedu.com.cn 域名类 --> 特点就是.xxx是重复的 --> \w+(\.\w+)+ 3:复合词/html/html-tutorial.html 路径类 --> 固定/html/后面可以无限任意字符 -->/\w+/.* 答案: [root@s1 ~]# a=http://www.oldboyedu.com:80/html/html-tutorial.html [root@s1 ~]# echo $a | grep -oE ‘[a-z]+|\w+(\.\w+){2}|[0-9]{2}|/\w+/.*‘ #四个表达式的顺序与url的四个内容一致,解法一:一一对应 [root@s1 ~]# echo $a | grep -Eo ‘\w+|\w+(\.\w+)+|/\w+/.*‘ #\w+ 匹配出 http 及 80,解法二:提取同类的字符为一类 [root@s1 ~]# echo $a | grep -oE ‘[a-z.0-9]+|[^0-9]+$‘ #[^0-9]+$ 匹配出 /html/html-tutorial.html ,解法三:与解法二类似,引用位置关系 机制解题的关键:在理解基础解题的基础上,搭配*可变0及正则匹配流程 [root@s1 ~]# echo $a | grep -oE ‘(/\w+/.*)*([^:/])*‘ 解题过程: 1 (/\w+/.*)* 由于有*,整个表达式可以变0,所以从url的第一个字符开始匹对都失败,直到/html/html-tutorial.html 才匹对成功,产生占有字符。 2 匹对过程: (/\w+/.*)* 已经匹对完整个内容了,但正则表达式 ([^:/])* 还没有匹对,所以 ([^:/])*从头开始匹对 3 贪婪与回溯:当 ([^:/])* 将/html/html-tutorial.html分解多个单词,而 (/\w+/.*)* 就一个单词,按贪婪原则 ,(/\w+/.*)*胜出。 注意:一个正则表达式产生占有字符,不代表其他表达式就不会对该占有字符对应的内容重新匹对,因为占有字符的最终确定是贪婪机制。 |
占有字符与零宽度是正则匹对原理的基础
占有字符主要是对字符 [ 组合 ] 的排序搜索方式的工作机制:核心就是正则表达式不会重复匹对已经匹配出结果的内容,及得出临时的结果(占有字符)。
[root@server01 ~]# echo "abc123" | grep -E --color ‘a.*1.*‘
abc123
[root@server01 ~]#
匹对过程 a #正则表达式第一个是字符a本身,这个直接匹对上 abc123 # 表达式a.*中的.*直接匹对后续的bc123,因为.*代表任意无限的字符组合,体现的贪婪机制 abc123 #回溯开始。因为1.*表达式中的1是字符本身,优先级比上一个表达式a.*中的.*要高,所以要产生回溯。 abc12 #回溯要回溯到那个地点才行能?理论上要证明表达式的字符1是在内容的字符排序中的第一个出现,并且在与a.*所对应的字符串中没有1,那么a.*所对应的字符串就是占有字符。 abc12 #回溯开始。 abc1 #还不能证明表达式字符1是在内容的字符排序中的第一个出现,但记录下第一次遇到字符1及位置 abc1 #回溯开始。 abc #a.*中.*匹对成功,并且没有字符1,故a.*的占有字符产生(就是内容的abc)。也就是a.*可以退出这个正则匹对的舞台了。那么剩下的就到1.*上阵了 abc1 #1.*正则表达式中的字符1与内容的字符1匹对成功 abc123 #1.*完成匹对内容的123(数字123就是占有字符),到此正则的比对完成。 |
零宽度主要是对字符 [ 组合 ] 位置搜索方式的工作机制:核心就是让正则表达式在那个位置开始匹对,后续工作交由对字符 [ 组合 ] 的排序搜索方式接管
[root@server01 ~]# echo "abc123" | grep -Eo --color ‘^(a..|1..)‘ abc [root@server01 ~]# echo "abc123" | grep -Eo --color ‘a..|1..‘ abc 123 [root@server01 ~]# 分析过程 正则表达式 ^(a..|1..)中的 a.. 在内容的开始位置开始比较,1.. 依然在内容的开始位置开始比较,所以最终结果只能是 a.. 正则表达式能匹对abc123中的abc 正则表达式 a..|1.. 的原理基本上,同上述的对字符 [ 组合 ] 的排序搜索方式差不多了。 |
GNU/Linux 正则表达式与三剑侠(grep,sed,awk)(精)
标签:target 分组 表达 应用 server bre 详情 内容 意思
原文地址:https://www.cnblogs.com/BoNuo/p/9736666.html