标签:ESS 删除 war 存储目录 下载jdk 日志文件 界面 dfs 重要
指导手册02:伪分布式安装Hadoop(ubuntuLinux)
Part 1:安装及配置虚拟机
1.安装Linux.
1.安装Ubuntu1604 64位系统
2.设置语言,能输入中文
3.创建hadoop账户
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
//输入2遍密码
sudo adduser hadoop sudo #设置hadoop用户的管理员权限
5.更新apt
设置更新和服务中,更新站点选中国阿里云,执行“sudo apt-get update”,更新成功(系统设置里-)软件更新)。
sudo apt-get update
6.安装vim编辑器
sudo apt-get install vim
2.安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了。
Part 2: 配置Hadoop环境
重要知识的提示:
1. Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件
2. Hadoop 的配置文件位于 hadoop/etc/hadoop/ 中,伪分布式需要修改5个配置文件hadoop-env.sh、 core-site.xml 、 hdfs-site.xml 、mapred-site.xml和yarn-site.xml
3. Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现
实验步骤:
1. 修改配置文件:hadoop-env.sh、core-site.xml,hdfs-site.xml,mapred-site.xml、yarn-site.xml
2. 初始化文件系统hadoop namenode -format
4. 启动所有进程start-all.sh或者start-dfs.sh、start-yarn.sh
5. 访问web界面,查看Hadoop信息
6. 运行实例
7. 停止所有实例:stop-all.sh
1:下载Hadoop安装包并解压
1.下载地址:http://hadoop.apache.org/releases.html
可以自己选择版本,最新版是hadoop-3.1.1.tar.gz
2.解压安装包
先新建文件夹bigdata,解压到该目录下。sudo mkdir /bigdata
解压Hadoop安装包
sudo tar -zxvf hadoop-3.1.1.tar.gz -C /bigdata/
在Hadoop安装包目录下有几个比较重要的目录
sbin : 启动或停止Hadoop相关服务的脚本
bin :对Hadoop相关服务(HDFS,YARN)进行操作的脚本
etc : Hadoop的配置文件目录
share :Hadoop的依赖jar包和文档,文档可以被删掉
lib :Hadoop的本地库(对数据进行压缩解压缩功能的)
检查是否可用:
hadoop version
3.修改文件夹权限:

2:配置Hadoop环境
1.配置Hadoop(伪分布式),修改其中的5个配置文件即可
1) 进入到Hadoop的etc目录下
cd /bigdata/hadoop-3.1.1/etc/hadoop
ls
可以看到需该目录下的几个本置文件
2) 修改第1个配置文
sudo vi hadoop-env.sh

export JAVA_HOME=/opt/java/jdk1.8.0_181
找到第54行,修改JAVA_HOM如下:

3) 修改第2个配置文件
sudo vi core-site.xml
|
<configuration> <!-- 配置hdfs的namenode(老大)的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>
<!-- 配置Hadoop运行时产生数据的存储目录,不是临时的数据 --> <property> <name>hadoop.tmp.dir</name> <value>file:/bigdata/hadoop-3.1.1/tmp</value> </property> </configuration> |
4) 修改第3个配置文件
sudo vi hdfs-site.xml
|
<configuration> <!-- 指定HDFS存储数据的副本数据量 --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.http-address</name> <value>localhost:50070</value> </property>
<property> <name>dfs.namenode.name.dir</name> <value>file:/bigdata/hadoop-3.1.1/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/bigdata/hadoop-3.1.1/tmp/dfs/data</value> </property>
</configuration>
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。 |
5) 修改第4个配置文件:
sudo vi mapred-site.xml
|
<configuration> <!-- 指定mapreduce编程模型运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
|
6) 修改第5个配置文件
sudo vi yarn-site.xml
|
<configuration> <!-- 指定yarn的老大(ResourceManager的地址) --> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property>
<!-- mapreduce执行shuffle时获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
|
7) 对hdfs进行初始化(格式化HDFS)
cd /bigdata/hadoop-3.1.1/bin/
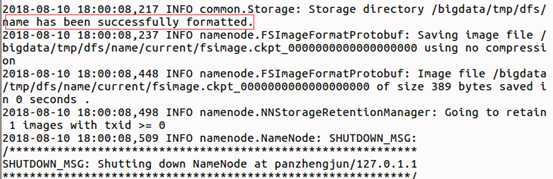
sudo ./hdfs namenode -format
8) 如果提示如下信息,证明格式化成功:
3:启动并测试Hadoop
1) cd /bigdata/hadoop-3.1.1/sbin/
sbin/start-dfs.sh或者./start-dfs.sh
sbin/start-yarn.sh或者./start-yarn.sh
如果报以上错误,请修改下面4个文件如下:
在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
修改后重启 ./start-dfs.sh,成功!
2) 使用jps命令检查进程是否存在,总共5个进程(jps除外),每次重启,进程ID号都会不一样。如果要关闭可以使用 stop-all.sh命令。
4327 DataNode
4920 NodeManager
4218 NameNode
4474 SecondaryNameNode
4651 ResourceManager
5053 Jps
3) 访问hdfs的管理界面
localhost:50070
4) 访问yarn的管理界面
localhost:8088
5) 如果点击节点Nodes,发现panzhengjun:8042也可访问
6) 如果想停止所有服务,请输入sbin/stop-all.sh
4:Hadoop无法正常启动的解决方法
一般可以查看启动日志来排查原因,注意几点:
1)启动时会提示形如 “panzhengjun: starting namenode, logging to /bigdata/hadoop-3.1.1/logs/hadoop-hadoop-namenode-panzhengjun.out”,其中 panzhengjun 对应你的机器名,但其实启动日志信息是记录在 /bigdata/hadoop/logs/hadoop-hadoop-namenode-panzhengjun.log 中,所以应该查看这个后缀为 .log 的文件;
2)每一次的启动日志都是追加在日志文件之后,所以得拉到最后面看,对比下记录的时间就知道了。一般出错的提示在最后面,通常是写着 Fatal、Error、Warning 或者 Java Exception 的地方。可以在网上搜索一下出错信息,看能否找到一些相关的解决方法。
3)此外,若是 DataNode 没有启动,可尝试如下的方法(注意这会删除 HDFS 中原有的所有数据,如果原有的数据很重要请不要这样做):
# 针对 DataNode 没法启动的解决方法
./sbin/stop-dfs.sh # 关闭
rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据
./bin/hdfs namenode -format # 重新格式化 NameNode
./sbin/start-dfs.sh # 重启
Hadoop环境搭建参考:http://dblab.xmu.edu.cn/blog/install-hadoop/
Part 3: 安装Eclipse编程环境
1:下载并安装JDK(FTP或在线都可)
1.在线下载JDK或直接本地拷贝到Linux虚拟机当前用户Downloads目录
2.进入/opt目录,创建java文件夹,然后解压JDK到该文件夹。
sudo mkdir /opt/java
sudo tar -zxvf jdk-8u181-linux-x64.tar.gz -C /opt/java/
3.配置jdk环境变量(有2种方式,修改profile或者.bashrc,任选一即可,二者区别自行学习)
sudo vim /etc/profile
增加如下内容:
export JAVA_HOME=/opt/java/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin
4.重新加载环境变量脚本
source /etc/profile
5.验证Java是否生效
java -version
2:下载eclipse并安装
1.在线下载或者FTP下载并拷贝到当前用户Downloads目录下面
下载地址:https://www.eclipse.org/downloads/
2.解压eclipse到/opt目录下
3.查看解压结果
ls
4.在linux系统中设置eclipse快捷方式
1) sudo gedit /usr/share/applications/eclipse.desktop
2) 向eclipse .desktop中添加以下内容:
[Desktop Entry]
Encoding=UTF-8
Name=Eclipse
Comment=Eclipse IDE
Exec=/opt/eclipse/eclipse
Icon=/opt/eclipse/icon.xpm
Terminal=false
StartupNotify=true
Type=Application
Categories=Application;Developmet;
3) 给eclipse .desktop文件赋权 :
sudo chmod u+x eclipse.desktop
此时我们会看到,刚才建立的eclipse.desktop文件变成了Eclipse的图标。
4) 找到/usr/share/applications/eclipse.desktop,右键选择 copy to desktop,即可。
注:1、Exec代表应用程序的位置(视实际情况修改)
Icon代表应用程序图标的位置(视实际情况修改)
附录:练习常用linux命令
l cd命令:切换目录
(1)切换到目录“/usr/local”
cd /usr/local
(2)切换到当前目录的上一级目录
cd ..
(3) 切换到当前登录Linux系统的用户的自己的主文件夹
cd ~
l ls命令:查看文件与目录
(4) 查看目录“/usr”下的所有文件和目录
cd /usr
ls -al
l mkdir命令:新建目录
(5) 进入“/tmp”目录,创建一个名为“a”的目录,并查看“/tmp”目录下已经存在哪些目录
$ cd /tmp
$ mkdir a
$ ls -al
(6) 进入“/tmp”目录,创建目录“a1/a2/a3/a4”
$ cd /tmp
$ mkdir -p a1/a2/a3/a4
l rmdir命令:删除空的目录
(7) 将上面创建的目录a(在“/tmp”目录下面)删除
$ cd /tmp
$ rmdir a
(8) 删除上面创建的目录“a1/a2/a3/a4” (在“/tmp”目录下面),然后查看“/tmp”目录下面存在哪些目录
$ cd /tmp
$ rmdir -p a1/a2/a3/a4
$ ls -al
l cp命令:复制文件或目录
(9) 将当前用户的主文件夹下的文件.bashrc复制到目录“/usr”下,并重命名为bashrc1
$ sudo cp ~/.bashrc /usr/bashrc1
(10) 在目录“/tmp”下新建目录test,再把这个目录复制到“/usr”目录下
$ cd /tmp
$ mkdir test
$ sudo cp -r /tmp/test /usr
l mv命令:移动文件与目录,或更名
(11) 将“/usr”目录下的文件bashrc1移动到“/usr/test”目录下
$ sudo mv /usr/bashrc1 /usr/test
(12) 将“/usr”目录下的test目录重命名为test2
$ sudo mv /usr/test /usr/test2
l rm命令:移除文件或目录
(13) 将“/usr/test2”目录下的bashrc1文件删除
$ sudo rm /usr/test2/bashrc1
(14) 将“/usr”目录下的test2目录删除
$ sudo rm -r /usr/test2
l cat命令:查看文件内容
(15) 查看当前用户主文件夹下的.bashrc文件内容
$ cat ~/.bashrc
l tac命令:反向查看文件内容
(16) 反向查看当前用户主文件夹下的.bashrc文件的内容
$ tac ~/.bashrc
l more命令:一页一页翻动查看
(17) 翻页查看当前用户主文件夹下的.bashrc文件的内容
$ more ~/.bashrc
l head命令:取出前面几行
(18) 查看当前用户主文件夹下.bashrc文件内容前20行
$ head -n 20 ~/.bashrc
(19) 查看当前用户主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行
$ head -n -50 ~/.bashrc
l tail命令:取出后面几行
(20) 查看当前用户主文件夹下.bashrc文件内容最后20行
$ tail -n 20 ~/.bashrc
(21) 查看当前用户主文件夹下.bashrc文件内容,并且只列出50行以后的数据
$ tail -n +50 ~/.bashrc
l touch命令:修改文件时间或创建新文件
(22) 在“/tmp”目录下创建一个空文件hello,并查看文件时间
$ cd /tmp
$ touch hello
$ ls -l hello
(23) 修改hello文件,将文件时间整为5天前
$ touch -d “5 days ago” hello
l chown命令:修改文件所有者权限
(24) 将hello文件所有者改为root帐号,并查看属性
$ sudo chown root /tmp/hello
$ ls -l /tmp/hello
l find命令:文件查找
(25) 找出主文件夹下文件名为.bashrc的文件
$ find ~ -name .bashrc
l tar命令:压缩命令
(26) 在根目录“/”下新建文件夹test,然后在根目录“/”下打包成test.tar.gz
$ sudo mkdir /test
$ sudo tar -zcv -f /test.tar.gz test
(27) 把上面的test.tar.gz压缩包,解压缩到“/tmp”目录
$ sudo tar -zxv -f /test.tar.gz -C /tmp
l grep命令:查找字符串
(28) 从“~/.bashrc”文件中查找字符串‘examples‘
$ grep -n ‘examples‘ ~/.bashrc
Ubuntu 常用命令整理
https://www.jianshu.com/p/1340bb38e4aa
指导手册02:伪分布式安装Hadoop(ubuntuLinux)
标签:ESS 删除 war 存储目录 下载jdk 日志文件 界面 dfs 重要
原文地址:https://www.cnblogs.com/soft2408/p/9745274.html