标签:produce 数据库服务器 替换 archive .com cached redis revoke 设置
存储引擎:如何存储data,为存储的data建立索引,如何更新、查询data等技术的实现方法
数据库的表有不同的类型,对应mysql不同的存取机制,表类型又称存储引擎
NDB存储引擎
是一个集群存储引擎,类似于 Oracle 的 RAC 集群
BLACKHOLE 黑洞存储引擎
应用于--主备复制中的---分发主库
事务(Transaction)是并发控制的基本单位。
将某些操作的多个sql作为原子性操作,这些操作要么都执行,要么都不执行,一旦某一个出现错误,即可回滚到原来的状态,从而保证数据库数据的完整性
ACID
事务的三个常用命令
Begin Transaction、Commit Transaction、RollBack Transaction。
多表连接查询、有外键关联
相当于函数,封装了,一系列预编译可执行的sql语句,存放在MySQL中。
直接调用它的名字,可以执行其内部的一堆sql
优点:
1.程序与sql解耦。一个存储过程替代大量sql语句
2.执行效率高。存储过程是预编译的一个代码块
3.网络传输量小。传别名的数据量小,传sql数据量大
4.确保数据安全。执行存储过程需要用户有一定权限
缺点:
1.程序猿拓展功能不方便
2.移植性差create procedure p1()
BEGIN
SELECT * FROM TABLE1;
END
#在mysql中调用
call p1() 视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增删改查
create view table1_view as select * from table1; 触发器是一种特殊的存储过程,通过事件来触发而被执行的。
使用触发器可以定制用户对表进行增、删、改操作前后的行为
create trigger tri_after_insert_table1 after insert on table1 for each row
BEGIN
SELECT * FROM TABLE1;
END相当于,新华字典的,音序表
数据库管理系统中,一个排序好的数据结构,协助快速查询data,范围查询data
create index ix_age on table1(age);
create index 索引名1,索引名2 on 表名('字段1','字段2')优势
1.可以大大加快数据的检索速度,(这也是创建索引的最主要的原因)
2.分组和排序,显著减少时间
3.加速表和表之间的连接
4.创建唯一性索引,保证每一行数据的唯一性
代价
1.增加了数据库的存储空间,(每一个索引需要占用物理空间)
2.插入与修改data要花费较多时间,(index索引也跟着变动)什么时候用?
1. 经常select查询
2. 表记录超级多
3. 列。经常搜索的列、主键列、外键列、排序的列、where上的列、范围查找的列 age in [20,40]
什么时候不用?
1. 经常update、delete、insert
2. 表记录少
3. 列。不经常使用的列、数据值很少的列(固定电话)、定义为文本,图片,bit的列、修改性能远远大于检索性能的列B+树:二叉树---平衡二叉树---B树---B+树---B-树---B*树---红黑树
http://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
https://blog.csdn.net/samjustin1/article/details/52664514
https://blog.csdn.net/xiaqunfeng123/article/details/52534468
https://blog.csdn.net/qq_26768741/article/details/53164202
B+树
用途:用于数据库索引,操作系统的文件系统中
特点:保持data稳定有序,插入与修改有较稳定的对数时间复杂度O(logN)
1.所有关键字的信息,都出现在叶子节点
2.所有非叶子节点,不存储data,只存储key,递增排列
3.为所有叶子节点增加一个链指针
4.非叶子节点的key,是其子树的最大或最小关键字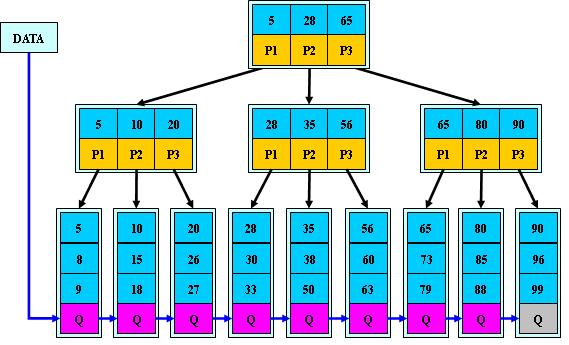
Mysql如何衡量查询效率呢?– 磁盘IO次数
1.B+树节点小,磁盘I/O次数少
B+树。叶节点存放data,其他节点用来索引
B-树。每个索引节点都会有data区域
红黑树。树的深度过大,IO读写频繁
2.B+树,支持范围查询,B树不支持
所有的叶子节点用指针串起来,遍历叶子节点,就能获得全部数据,可以进行区间访问https://blog.csdn.net/xiedelong/article/details/81417049
DDL (define) 数据库定义语言 database、table、view、index、producer、drop
DML(manager) 数据库操纵语言 insert、delete、update、select
DCL (control) 数据库控制语言 grant,revoke 权限
SQL中的drop、delete、truncate都表示删除,但是三者有一些差别
1.delete和truncate只删除表的数据不删除表的结构
2.速度,一般来说: drop> truncate >delete
3.delete语句是dml,这个操作会放到rollback segement中,事务提交之后才生效;如果有相应的trigger,执行的时候将被触发.
4.truncate,drop是ddl, 操作立即生效,原数据不放到rollback segment中,不能回滚. 操作不触发trigger.
5.安全性:小心使用drop 和truncate,尤其没有备份的时候 ,不可回滚分别在什么场景之下使用?
1.不再需要一张表的时候,用drop
2.想删除部分数据行时候,用delete,并且带上where子句
3.保留表而删除所有数据的时候用truncate 查询来自杭州,并且订单数少于2的客户。
select a.customer_id, count(b.order_id) as total_orders
from table1 as a left join table2 as b
on a.customer_id = b.customer_id
where a.city = 'hangzhou'
group by a.customer_id
having count(b.order_id) < 2
order by total_orders desc
limit 1;char是固定长度的类型
vachar是可变长度的类型
char(10):定长,字符长度为10,浪费空间,存取速度快
root存成root000000,数据不足时,右边用空格填充
varchar(10):变长,字符长度10,,精准,节省空间,存取速度慢
存储数据的真实内容,不会填充,
1-2bytes的数据字节数 + 真实数据root(1)服务层面:配置mysql性能优化参数;
(2)系统层面:优化数据表结构、字段类型、字段索引、分表,分库、读写分离等等。
(3)数据库层面:优化SQL语句,合理使用字段索引。
(4)代码层面:使用缓存和NoSQL数据库方式存储,MongoDB/Memcached/Redis来缓解高并发下数据库查询的压力。
(5)减少数据库操作次数,尽量使用数据库访问驱动的批处理方法。
(6)不常使用的数据迁移备份,避免每次都在海量数据中去检索。
(7)提升数据库服务器硬件配置,或者搭建数据库集群。
(8)编程手段防止SQL注入1.建索引
2.减少表之间的关联
3.优化sql,尽量让sql很快定位数据,不要让sql做全表查询,应该走索引,把数据 量大的表排在前面
4.简化查询字段,没用的字段不要,尽量返回少量数据
1.SQL语句优化
用Where子句替换HAVING 子句,因为HAVING 只会在检索出所有记录之后才对结果集进行
2.索引优化
看上文索引
3.数据库结构优化
1)范式优化: 比如消除冗余(节省空间。。)
2)反范式优化:比如适当加冗余等(减少join)
3)拆分表、拆分库
4)读写分离
4.服务器硬件优化标签:produce 数据库服务器 替换 archive .com cached redis revoke 设置
原文地址:https://www.cnblogs.com/venicid/p/9747043.html