标签:数据 经验 机械 全连接 生成 系统 文本 起点到终点 正向匹配
英文文本词与词之间以空格分隔,方便计算机识别,但是中文以字为单位,句子所有字连起来才能表达一个完整的意思。如英文“I am writing a blog”,英文词与词之间有空格进行隔开,而对应的中文“我在写博客”,所有的词连在一起,计算机能很容易的识别“blog”是一个单词,而很难知道“博”、“客”是一个词,因此对中文文本序列进行切分的过程称为“分词”。中文分词算法是自然语言处理的基础,常用于搜索引擎、广告、推荐、问答等系统中。
中文分词算法属于自然语言处理范畴,对于一句话,人类可以通过自己的经验知识知道哪些字组成一个词,哪些字又是独立的,但是如何让计算机理解这些信息并作出正确处理的过程叫做分词,中文分词算法分成三大类:一、基于词典的分词算法,二、基于机器学习的分词算法,三、基于神经网络的分词算法。
基于词典的分词算法又称为机械分词,它是按照一定的策略将待分词的文本切分成一个个小片段在已知的词典中进行查找,如果某字符串能在词典中找到,则匹配成功,这种分词思想简单、高效,在实际分词系统中很常用。
字符串匹配算法按照其扫描方向的不同分成正向匹配和逆向匹配,按照其匹配长度的不同可以分成最大匹配和最小匹配。由于中文“单字成词”的特点,很少利用到最小匹配来作为字符串匹配算法。一般来说,正向匹配分词算法的准确度略低于逆向匹配算法,据统计单纯使用正向最大匹配算法的错误率为1/169,而单纯使用逆向最大匹配算法的错误率为1/245。即使如此,单纯的字符串匹配算法也不能满足系统的要求,通常需要利用这种算法对文本进行粗分,在此基础上结合其他的方法一起使用,提高系统分词的准确率。
以逆向最大匹配为例,首先从待分词的文本中选取最后m(字典中词条的最大长度)个字,如果能在词典匹配到,则将匹配的词切分出来,并以未切分的文本中重新选取m个字进行匹配,如果没有在词典中匹配到,则去掉最后一个字,对m-1个字在字典中进行匹配,反复上述操作,直到选取的字组能在词典中匹配到为止,待匹配的所有字都在切分完成,就得到该文本的分词结果。
N-最短路径分词算法的基本思想是根据词典匹配首先找出所有匹配的字符串,并且给每一个词赋予不同的权值,构成有向无环图,然后根据该图求出从起点到终点的前N条最短路径,如果两条或两条以上路径长度相等,那么他们的长度并列第 i,都要列入粗分结果集,而且不影响其他路径的排列序号,最后的粗分结果集合大小大于或等于N。N-最短路径可以看成是最短路径方法和全切分的结合,其出发点是尽量使得切分出来的词最少,跟寻找最短路径的方法一致,同时有尽可能考虑包含最终结果,跟全切分方法相似。通过这种综合,一方面避免了最短路径分词方法大量舍弃正确结果的可能,另一方面又大大解决了全切分搜索空间过大,运行效率差的弊端。
《基于N-最短路径方法的中文词语粗分模型》论文中有个例子,是对“他说的确实在理”这句话的图模型
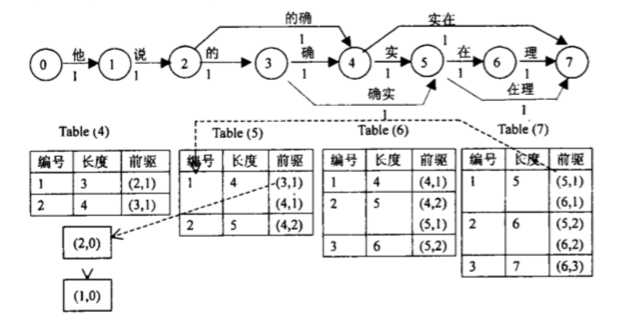
图的定点是0、1、2….7,这些顶点其实没有什么实际含义,不是词,也不是字,只是一个编号。有n个词的句子就会产生n+1个定点。图中的每条边都是一个词,边都可以是有权重的(默认为1),这个权重可以是概率,词频之类的。
基于词典的分词算法简单、高效,但是不能很好解决歧义问题,更对新词无能为力。人们很自然地把目光转向到机器学习上,分词问题转化成机器学习问题,需要解决两个问题:一、特征工程,怎么设计特征,选取哪些特征训练模型,特征的好坏直接决定分词的效果,二、训练目标,机器学习的优化目标是什么。分词特征的选取一般会考虑词本身,当然也可以整理部分字典信息,作为机器学习模型的特征。分词问题可以看成是序列标注问题,设置标签集合{S、B、M、E},其中S表示单个字,B表示某个词的开始,M表示某个词的中间,E表示某个词的结束。常用于分词的机器学习算法有HMM(隐马尔可夫模型)和CRF(条件随机场)。
近几年随着深度学习在自然语言处理领域如火如荼的应用,并取得不错的效果。目前比较常用的BiLSTM+CRF模型,相关论文也比较丰富,本文简单介绍一下原理,LSTM擅长捕捉序列的相关信息,对于待分词文本,以每个字作为输入,经过embedding层,得到对应的输入向量,通过LSTM层编码,把前向和后向得到编码拼接在一起,获得该字bi-lstm层向量,通过全连接层,生成相应的输出向量,并通过CRF得到最终的预测目标。除了常用的{S、B、M、E}标签集外,还有一些尝试把分词和词性标注结合在一起,通过深度学习模型同时输出分词和词性标注的结果。
虽然分词算法相对比较成熟,但是在实际应用中很少用某一种方法得到比较好的效果,而是通过多种方法组合而得到一个相对比较好的结果。中文是一种十分复杂的语言,让计算机理解中文语言更是困难,分词算法还是有两大难题亟待解决。
歧义是指同一段文本,有两种或者多种切词方法。例如:结合成分子,因为“结合”和“合成”都是词,那么这个短语就可以分成“结合 成 分子”和“结 合成 分子”。这种称为交叉歧义。交叉歧义在中文分词中非常常见,由于没有人的知识去理解,计算机很难识别哪一种是正确答案。根据语义信息交叉歧义相对来说还是比较容易解决,还有一个歧义属于真歧义,所谓真歧义,就是指给出一段人也无法判断到底哪一种分词属于正确的分词,如“乒乓球拍卖完了”,可以分成“乒乓球 拍卖 完了” 和“乒乓 球拍 卖 完了”,如果没有上下文其他的句子,恐怕谁也不知道“拍卖”在这里算不算一个词。
新词又称为未登录词,即词典中没有出现过的词,常见的未登录词包括人名、机构名、地名、产品名、商标名、简称、省略语等,针对未登录词,因为时时刻刻都在产生新的,同时体量也十分庞大,没法收录到字典中。一般分词系统对会有专门的模块来处理未登录词,同时评价一个系统的好坏程度,对新词识别的准确率和召回都是重要度的评价指标。知乎专栏《新词发现》通过大量历史数据统计某个词是否是新词的方法介绍得很详细,方法也比较通用。它认为判断一个词是否是新词,主要从三方面来考虑,一、历史数据中出现的次数是不是足够多,二、新词的凝固度高,主要通过熵来衡量,通俗来说新词组成的字,需要经常一起出现,三、新词的自由度高,主要通过左右熵来衡量,一个新词的左邻字集合和右邻字集合有多随机,随机组合越多,越可能成为新词。
标签:数据 经验 机械 全连接 生成 系统 文本 起点到终点 正向匹配
原文地址:https://www.cnblogs.com/sxron/p/9744530.html