标签:重要性 min RoCE 技术 com hide 最大 产生 编码
特征工程:本质上是一项工程活动,他目的是最大限度地从原始数据中提取特征以供算法和模型使用
特征工程的重要性:特征越好,灵活性越强、模型越简单、性能越出色。
特征工程包括:数据处理、特征选择、维度压缩
就是单位,特征的单位不一致,不能放在一起比较
通过:0-1标准化、Z标准化、Normalizer归一化


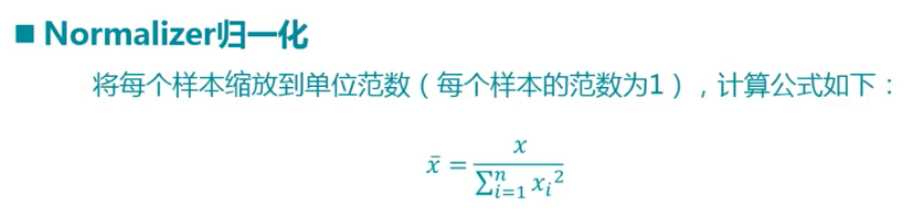

1 import pandas 2 3 data=pandas.read_csv( 4 "C:\\Users\\Jw\\Desktop\\python_work\\Python数据挖掘实战课程课件\\6.1\\data1.csv") 5 6 #Min-Max标准化 7 from sklearn.preprocessing import MinMaxScaler 8 9 scaler=MinMaxScaler() 10 11 data["标准化累计票房"]=scaler.fit_transform(data[["累计票房"]]) 12 data["标准化豆瓣得分"]=scaler.fit_transform(data[["豆瓣评分"]]) 13 14 #Z-Score标准化 15 from sklearn.preprocessing import scale 16 17 data["标准化累计票房"]=scale(data["累计票房"]) 18 data["标准化豆瓣评分"]=scale(data["豆瓣评分"]) 19 20 21 #Normalizer归一化 22 from sklearn.preprocessing import Normalizer 23 24 scaler = Normalizer() 25 26 data[‘归一化累计票房‘] = scaler.fit_transform( 27 data[‘累计票房‘] 28 )[0] 29 data[‘归一化豆瓣评分‘] = scaler.fit_transform( 30 data[‘豆瓣评分‘] 31 )[0]
虚拟变量也叫哑变量和离散特征编码,可用来表示分类变量、非数量因素可能产生的影响
使用get_dummies获取虚拟变量
如果新数据分类较少,要获取前面的category类,可以用categories=data["列名"].cat.categories来得到之前的分类,与之前的列一一对应

1 import pandas 2 3 data=pandas.read_csv( 4 "C:\\Users\\Jw\\Desktop\\python_work\\Python数据挖掘实战课程课件\\6.1\\data2.csv") 5 6 data["症状"]=data["症状"].astype("category") 7 8 dummiesData = pandas.get_dummies( 9 data, 10 columns=[‘症状‘], 11 prefix=[‘症状‘], 12 prefix_sep="_" 13 ) 14 15 16 newData=pandas.read_csv( 17 "C:\\Users\\Jw\\Desktop\\python_work\\Python数据挖掘实战课程课件\\6.1\\data2New.csv") 18 19 20 newData["症状"]=newData["症状"].astype( 21 "category", 22 categories=data["症状"].cat.categories) 23 24 dummiesNewData=pandas.get_dummies( 25 newData, 26 columns=["症状"], 27 prefix=["症状"], 28 prefix_sep="_")
缺失值产生原因:有些信息暂时无法获取、有些信息被遗漏或者错误的处理了
缺失值处理方法:数据补齐、删除缺失行、不处理
导入Imputer类,该类有三个备选项:mean、median、most_frequent
1 import pandas 2 3 data=pandas.read_csv("C:\\Users\\Jw\\Desktop\\python_work\\Python数据挖掘实战课程课件\\6.1\\data3.csv") 4 5 from sklearn.preprocessing import Imputer 6 7 #mean,median,most_frequent 8 9 imputer=Imputer(strategy="mean") 10 11 data["累计票房"]=imputer.fit_transform(data[["累计票房"]])
标签:重要性 min RoCE 技术 com hide 最大 产生 编码
原文地址:https://www.cnblogs.com/U940634/p/9748200.html
