标签:分享图片 因此 利用 产生 分数 分类器 方法 spec 精确
目录
@
??最近读完了R-CNN三部曲+SPP-Net,算是Detection里比较经典的一个系列,最近也在读CVPR或者ECCV的其他Detection相关的论文,发现很多都是在改进R-CNN系列的一些细节。因此在这将这4篇论文先分别进行一些讲解,再进行一些比较,阐述一些自己的想法,以便加深自己对这系列论文的理解,也希望可以帮到其他人。
??R-CNN算是很经典的一篇论文,当时很多Detection algorithm都是利用图片本身的颜色,纹理,梯度等low-level图片特征进行检测。R-CNN引进了CNN以及proposal等来进行检测,同时也利用pre-training来解决一些样本量很少的任务。
?R-CNN提出了一种全新的训练结构,它的整体流程如下:
??针对很多数据集样本很少,很难单独的使用一个数据集进行训练跟检测,R-CNN首先在其他样本较多与目标数据集任务相似的副本数据集进行有监督预训练,保留其训练的模型参数,利用目标数据集对某些网络进行微调(domain-specific fine-tuning),这样可以产生更好的性能,这也是本文的亮点之一。
??首先在fine-tuning阶段,IOU阈值为0.5,即大于0.5的都是目标,小于0.5的都是背景,而在SVM训练时,小于0.3的都是负样本,正样本为GT。
??为什么要分开设置阈值呢?在fine-tuning期间,为了防止过拟合,阈值设置的宽松一点,就是就算有一半左右的物体与GT相交,那也是算是物体,而不是背景。在训练SVM的时候,则正样本只有GT,阈值大于0.3的忽略掉,小于0.3的算负样本(0.3也是通过实验挑选出来的)。之所以要重新训练SVM,也是因为在之前fine-tuning网络的时候设置的阈值较为宽松,所以softmax进行分类的性能其实并不是很理想。因此重新训练了一个SVM分类器,效果相比softmax更理想了。
??fine-tuning用来微调一些参数,毕竟在副本任务训练不是当前数据集本身,肯定还是有差距的,CNN通常第一层提取出一些线条,边缘,之后更深的层则将这些基础特征组合起来,副本任务可以理解为提取大多数图像的共同的基本特征(这也就要求副本任务与目标任务要相近),通过在目标任务fine-tuning进行微调,使得detector对提取到目标数据集独特的特征与信息,同时文章中的实验也体现了fine-tuning的重要性与必要性,本文在fine-tuning时将原来网络1000个分类改为N+1(N为类别数量,1为背景)个分类,为了防止过大的影响原来的参数,学习率为预训练学习率的1/10。
1.我读完文章的时候就在想,对于每一个proposal进行CNN提取特征,一个图片2k左右proposals,一个数据集通常有更多的图片,那是不是有点太费力了?同时一个图片通常没有那么多“物体”,2000个proposal是不是有点太多了,应该会在物体附近很密集。
2.再单独训练一个SVM,是否有一些冗余,虽然文章中给出了单独训练SVM必要性的有力证据, 那是否可以改变一下网络模型使得softmax可行。
3.CNN网络之前必须将proposal进行变形称为固定的227*227是否可以接受任意形状的图片呢。
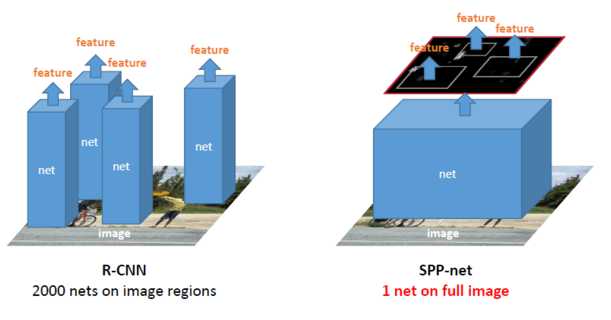
??R-CNN在当时取得了很大的成果,但是他还是有一些问题,最突出的就是效率问题,SPP-Net主要就是解决R-CNN的几个问题: 1. 对于每张图片的每个proposal跑一边CNN,SVM分类器,做了很多冗余的操作。2.proposal在送进网络之前都要进行拉伸(warp),这样会影响图片的质量以及内容,同时也比较费时费力。
?SPP-Net的改进如下:
相比R-CNN需要对每个proposal做卷积,SPP-Net只做一次卷积,将相应的sub-image映射到full-image卷积后的feature map上从而得到sub-image通过卷积层得到的feature,下图可以很形象的表达:
标签:分享图片 因此 利用 产生 分数 分类器 方法 spec 精确
原文地址:https://www.cnblogs.com/kk17/p/9748378.html