标签:col efi 打开终端 .so 验证 enc 注意 ack rm -rf
近几年深度学习在物体检测方面出现了许多基于不同框架的网络模型,不同模型需要不同的版本的Python、TensorFlow、Keras、CUDA、cuDNN以及操作系统。不得不说,要把经典物体检测网络的源码都跑通,单配置环境就要浪费很多时间,因为目前兼容这些经典网络的框架和环境还很少。新版的TensorFlow在models的objection-detection模块中包含了fast-rcnn、rfcn、SSD几种网络,不过开发环境是基于Ubuntu的,因此我对该环境进行了配置。Ubuntu版本很多,首选LTS版本。现在已经有了18.04LTS,装上后界面丰富好看了,不过在运行Python和TensorFlow环境下的代码时出现了一些未知问题,有关排故的信息也比较少,所以我重新安装了16.04LTS。安装时可先使用深度U盘启动工具(我使用的是UEFI版)制作Ubuntu启动盘,然后在电脑安装,具体过程百度即可。我以前使用的是双系统安装,但时间长了以后Ubuntu系统会出问题,有时需要进入grub模式进行修复,操作不当会导致无法进入Windows系统。所以后来我就把两个系统安装在两个硬盘上,启动时进入引导菜单选择要进入的硬盘即可,或者启动前拔掉其中一个硬盘电源线即可。
首先安装显卡驱动。首先看自己显卡
lspci | grep -i vga
lspci | grep -i nvidia然后看显卡驱动
lsmod | grep -i nvidiaUbuntu16.04原来安装的是开源的nouveau驱动,但是CUDA要使用NVIDIA官方驱动,所以要更换显卡驱动,可点击 系统设置->软件与更新->附加驱动->选择NVIDIA官方驱动,应用更改并重启即可。借用下图,其中NVIDIA驱动版本会因显卡不同而不同。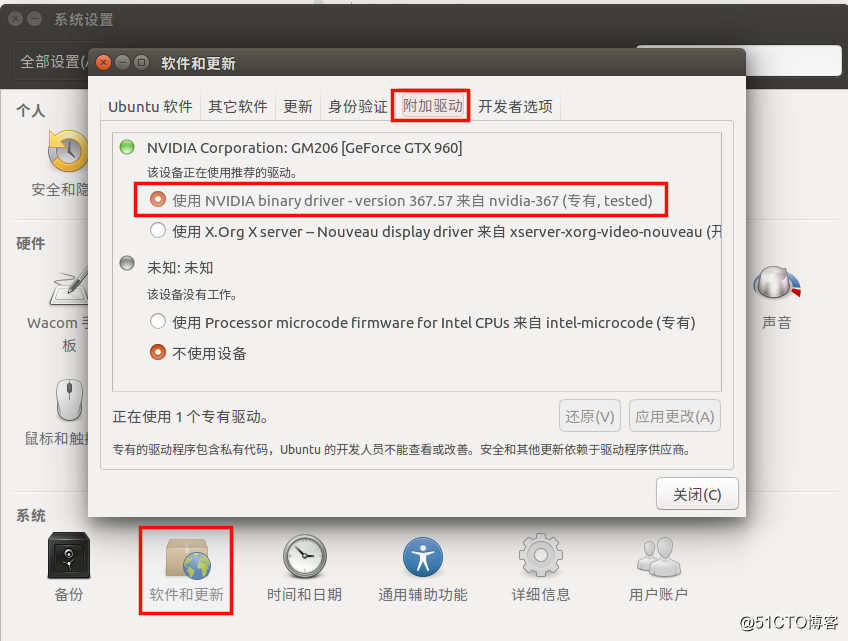
注意:
sudo apt-get remove --purge nvidia*
sudo gedit /etc/modprobe.d/blacklist.conf
blacklist nouveau
sudo update-initramfs -u
sudo service lightdm stop
sudo sh ./NVIDIA-Linux-x86_64-375.20.run我在安装过程出现了以下问题。
所以我采用在Ubuntu系统界面中改变驱动的方法。
为避免上述问题,在Ubuntu系统设置中更换显卡驱动即可。
Tensorflow1.9以后的版本需要安装CUDA9.0和cuDNN7.0,否则会出现异常。先下载CUDA9.0安装文件,借用下图。安装步骤可参考官方安装指导。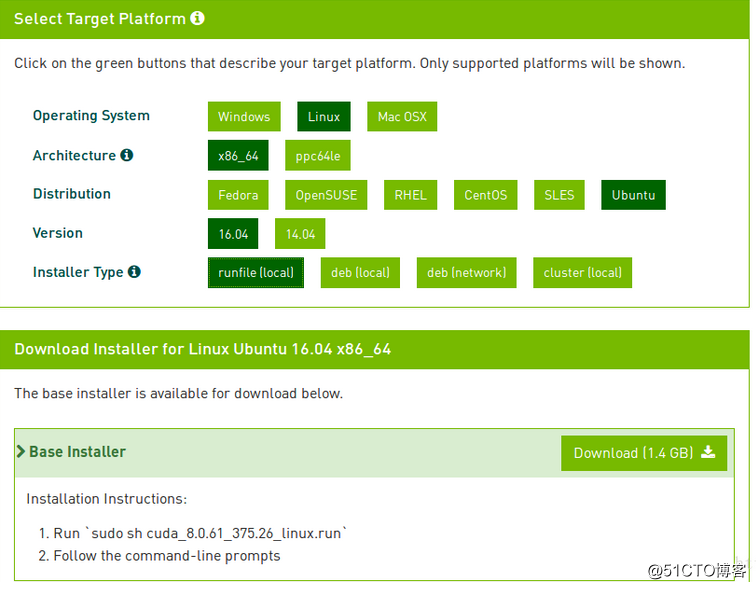
安装前可做如下准备工作,检查系统是否可以安装,Ubuntu16.04可忽略。主要有:
在ubuntu的终端中输入命令:
lspci | grep -i nvidia会显示出NVIDIA GPU版本信息,然后去CUDA的官网查看自己的GPU版本是否在CUDA的支持列表中。当前GPU基本都支持。
输入命令:
uname -m && cat /etc/*release结果显示:
x86_64
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=16.04
......
Ubuntu 16.04支持。
在终端中输入:
gcc –version结果显示:
gcc (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609
......
若未安装请使用下列命令进行安装:
sudo apt-get install build-essential
a、查看正在运行的系统内核版本:
在终端中输入:
uname –r结果显示:
4.10.0-40-generic
Ubuntu16.04不需要安装
上述检查完后可运行命令安装:
sudo dpkg -i cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.deb
sudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub
sudo apt-get update
sudo apt-get install cuda在CUDA完成安装之后,还需要添加环境变量,打开终端,输入下面的命令:
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}如果是64位系统,输入:
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}如果是32位系统,输入:
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}上述过程完成了整个的CUDA9.0的安装。
我在安装过程报错如下:
下列软件包有未满足的依赖关系: cuda : 依赖: cuda-9-0 (>= 9.0.176) 但是它将不会被安装
经检查是因为我关闭了Ubuntu的自动更新,打开后重新运行即可,如下图。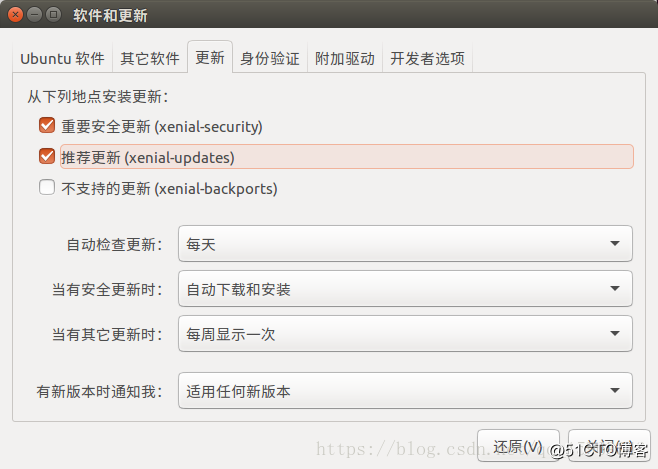
同时将附加驱动中的更新也打开。
cuDNN v7.0,下载地址
可用之前下载CUDA注册的邮箱登录。
进入之后点击Download,之后进入下载界面,选择上I Agree To the Terms of the cuDNN Software License Agreement的复选框,一次要选择上正确的版本。
我选择的是deb文件,下载界面选择的文件名为:
cuDNN v7.0.5 Runtime Library for Ubuntu16.04 (Deb)
下载后进入下载目录,打开终端,之后输入以下命令:
sudo dpkg -i libcudnn7_7.0.5.15-1+cuda9.0_amd64.deb
注意,上述命令中的可能会由于cudnn版本的细微差异而不同,注意tab键补齐就行。之后等待完成cuDNN的安装。
安装完成后可测试CUDA的Samples。
cd /usr/local/cuda-9.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery如果显示的是如下图关于GPU的信息,则说明安装成功了。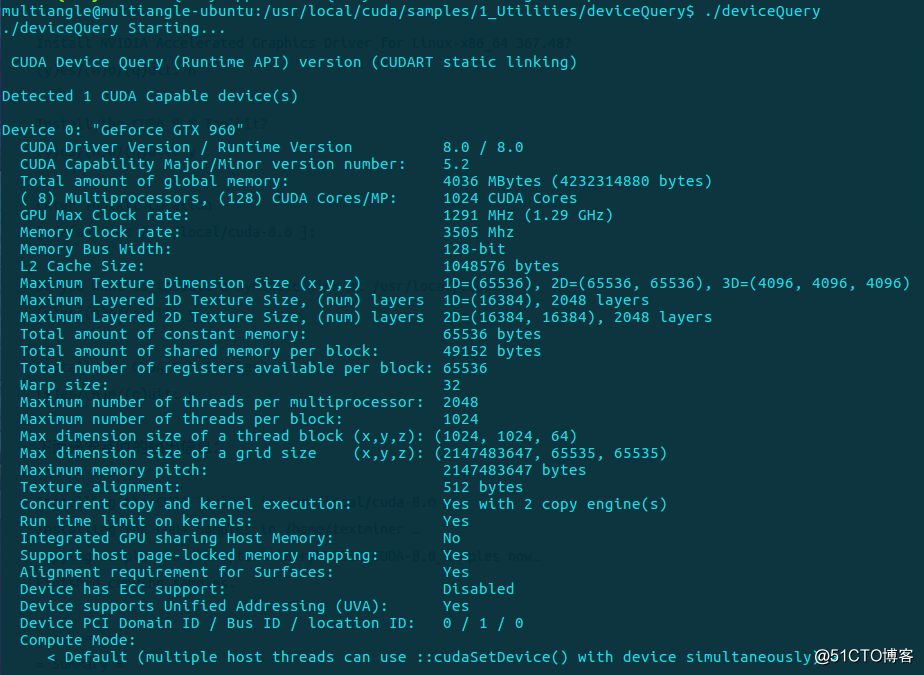
Anaconda版本与对应的Python版本列表如下。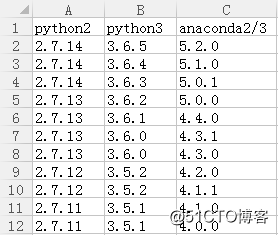
tensorflow1.5~1.10使用cuda9.0和cudnn7.0.5。我安装的是5.2.0,在官网下载文件,使用bash命令即可安装。如:
bash anaconda5.2.sh这里的安装文件名为了便于安装已修改。
为便于安装包导入时不出错,我在虚拟环境中安装tensorflow-gpu及其他相关包。使用conda新建虚拟环境。conda常用的命令有:
conda list #查看安装了哪些包
conda env list 或 conda info -e #查看当前存在哪些虚拟环境
conda update conda #检查更新当前conda创建Python虚拟环境。
conda create -n env_name python=X.X(2.7、3.6等)该命令 命令创建python版本为X.X、名字为env_name的虚拟环境。env_name文件可以在Anaconda安装目录envs文件下找到。指定python版本为2.7,也可以不指定,如:
conda create -n tf13也在可创建虚拟环境时同时安装必要的包,如:
conda create -n env_name numpy matplotlib激活(或切换不同python版本)虚拟环境。
source activate env_name(虚拟环境名称)Windows下命令为:
activate env_name(虚拟环境名称)activate your_env_name(虚拟环境名称)
对虚拟环境中安装额外的包。
使用命令conda install -n env_name [package]即可安装package到env_name中
关闭虚拟环境:
source deactivate Windows下为:
deactivate env_name删除虚拟环境:
conda remove -n env_name(虚拟环境名称) --all删除环境中的某个包:
conda remove --name env_name package_name创建虚拟环境后,进入该环境目录,安装tensorflow-gpu。由于一些源码要求tensorflow1.9.0以上版本,我安装该版本:
pip install tensorflow-gpu==1.9.0安装后,终端输入python,进入python命令行后输入:
import tensorflow as tf没有报错表示,安装成功。
但在spyder中创建文件,运行深度网络代码时提示:
SymbolAlreadyExposedError: Symbol unittest.mock is already exposed as (‘test.mock‘,).
这是由于tensorflow更新过程结构有变化,不适合所运行的代码。卸载tensorflow-gpu1.9.0,重新安装,不指定版本。
pip install tensorflow-gpu重新运行上述代码,不报错。查看版本,发现安装的是tensorflow-gpu1.3.0。
如果需要安装很多packages,conda下载的速度很慢,因为Anaconda.org的服务器在国外。清华TUNA镜像源有Anaconda仓库的镜像。可将其加入conda的配置:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes #设置搜索时显示通道地址pip安装也可设为通过修改配置文件,使用国内镜像。
# 如果不存在此文件夹,则创建之
mkdir ~/.pip
vi ~/.pip/pip.conf添加如下内容
[global]
index-url=http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
如果只需要单次使用镜像,可在安装命令后加上镜像名:
sudo pip install tensorflow-gpu==1.9.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/安装Anaconda后,运行Spyder会出现黑屏,Spyder界面没有出现。排除方法如下:
cd /etc/ld.so.conf.d目录中有 i386-linux-gnu_GL.conf and x86_64-linux-gnu_GL.conf等文件,打开后者添加驱动,运行如下代码:
cat x86_64-linux-gnu_GL.conf
/usr/lib/nvidia-340
/usr/lib32/nvidia-340但是文件i386-linux-gnu_GL.conf 是空文件,这时需要把 x86_64-linux-gnu_GL.conf中的内容复制到i386-linux-gnu_GL.conf
sudo gedit i386-linux-gnu_GL.conf 把两行内容复制,粘贴,保存,关闭。
sudo ldconfig注意:需要root权限,重启spyder, ok
这时虽然出现了界面,但在运行导入TensorFlow·语句时会报错,提示无法导入。这是因为Ubuntu在使用pip安装时把安装包安装在了自带的Python2.7的默认位置。为使用方便我在虚拟环境中安装TensorFlow和spyder、jupyter,安装spyder和jupyter代码如下:
sudo pip install jupyter
或conda install jupyter这样就不会提示导入出错。使用jupyter是执行
jupyter notebook即可。这时会打开默认位置的文件,如需永久改变打开位置需修改jupyter配置文件,如临时改变打开位置,在命令后加上文件路径即可。
Ubuntu默认安装了Python2.7,如果不切换安装目录,即使激活了
虚拟环境,安装时仍然会将包安装在默认位置。所以最好将将相关的包安装至虚拟环境所在的目录。不管是conda 还是pip,都要先切换至虚拟环境所在的目录,再用命令安装。例如spyder和jupyter都需要在该目录下重新安装,否则会提示无法导入tensoflow等导入的包。
安装完成后可新建syder文件输入以下代码验证:
import tensorflow as tf
hello = tf.constant(‘Hello, TensorFlow!‘)
sess = tf.Session()
out = sess.run(hello)
a = tf.constant(10)
b = tf.constant(32)
sess.run(a+b)输出正常结果即可。
在Windows下可使用鲁大师的软件在状态栏实时显示GPU状态信息。Ubuntu下可使用nvidia-smi命令,
输出结果借用下图,具体数字会有不同。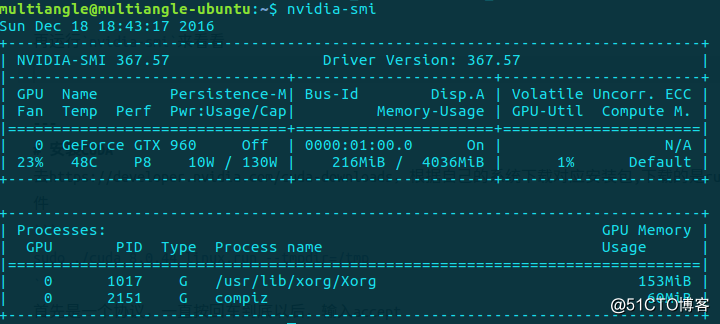
显示结果含义为:
第一行Driver Version表示驱动的版本。
第二行表示GPU序号,名字,Persisitence-M(持续模式状态)。如只有一个GPU,号为0,名字为GeForce系列的GTX960,持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态。
第三行字段如下:
Fan:N/A是风扇的转速,从0到100%之间变动。有的nvidia设备如笔记本,tesla系列不是主动散热的可能显示不了转速。
Temp:温度,48摄氏度。
Perf:是性能状态,从P0到P12,P0表示最大性能,P12表示最小性能地;
Pwr表示能耗;
Bus-Id是表示GPU总线类型;
Disp.A是DisPlay Active ,表示GPU是否有初始化
Memory-Usage表示显存的使用率;
Volatile GPU-Util表示GPU的利用率;
Uncorr.ECC是表示ECC的相关东西,ECC即 Error Correcting Code 错误检查和纠正,在服务器和工作站上的内存中才有的技术。
但是这个命令只能显示一次,如果要实时显示,配合watch命令, 让一秒刷新一次,可输入:
watch -n 1 nvidia-smi如果要卸载Anaconda,其步骤为:
由于Anaconda的安装文件都包含在一个目录中,所以直接将该目录删除即可。到包含整个anaconda目录的文件夹下,删除整个Anaconda目录:
sudo rm -rf anaconda文件夹名1.到根目录下,打开终端并输入:
sudo gedit ~/.bashrc2.在.bashrc文件末尾用#号注释掉之前添加的路径(或直接删除):
#export PATH=/home/lq/anaconda3/bin:$PATH
保存并关闭文件
3.使其立即生效,在终端执行:
source ~/.bashrc4.关闭终端,然后再重启一个新的终端,这一步很重要,不然在原终端上还是绑定有anaconda。
环境配置(近期实测)——Ubuntu16.04+CUDA9.0+tensorflow-gpu填坑记
标签:col efi 打开终端 .so 验证 enc 注意 ack rm -rf
原文地址:http://blog.51cto.com/8764888/2296248