标签:标记 多核 中间件 int enum 组成 ini 提高 关系
1、并发和并行的区别
并行:parallel
同一时刻上,有多件互不干扰的事要做。
并发:concurrency
同一时间内,多少事要做。
补充:
buffer(缓冲)是为了提高内存和硬盘或其他I/0设备之间的数据交换的速度而设计的。 cache(缓存)是为了提高cpu和内存之间的数据交换速度而设计。
2、并发的解决
什么是高并发:同一个时间段,发起大量的数据请求
2.1、队列、缓冲区:
使用队列就是,其实就是一个缓冲地带,即缓冲区,当然根据优先级别,设置不同的队列,优先级高的的先处理。例如queue模块中的类Queue , LifoQueue, PriorityQueue
2.2、争抢型:
资源争抢型,当争抢到资源后,就不会为其他请求提供服务,这就是:锁机制 其他请求只能等待。
但是这样并不好,因为有可能有的请求一直抢不到资源。
2.3、预处理:
一种提前加载用户所需数据的思路,即预处理思想,也就是缓存思想
常用的是字典,如果数据量大的时候,使用内存数据库,即Redis 或者memcached。
2.4、并行:
日常可以通过购买更多的服务器,或多开进程,线程实现并行处理,来解决并发问题。
注意这些都是水平扩展 思想
但是 这样成本上升。
注:
每个cpu称为一路,一个cpu有多核,如果 单cpu单核 是无法并行,看起来是像 并行,但并不是,只是轮询。
2.5、提速:
提高单个cpu的性能,或者单个服务器安装更多的cpu,或者提高程序的效率。
垂直扩展思想
2.6、消息中间件:
即系统之外的队列,常见的消息中间件:RabbitMQ, ActvieMQ(Apache),RocketMQ( 阿里Apache), kafka(Apavhe)。
通过消息中间件,成为分布式系统,对生产者和消费者(程序之间), 解耦同时做缓冲,将数据平滑起来。
2.7、多地区:多地服务器
3、进程和线程
在实现了线程的操作系统中(并不是所有的os都实现了 线程),线程是操作系统能够进行运算调度的最小单位,它被包含在进程中,是进程中的实际运作单位,一个程序的执行实例就是一个进程。
进程(process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
进程和程序的区别:
程序是源代码编译后的文件,而这些文件存放在磁盘上,当程序被操作系统加载到内存中,就是进程,进程中存放着指令和数据(资源),它也是线程的容器。
Linux是分父进程和子进程,Windows的进程时平等关系。
线程,有时 被称为轻量级进程( Lightweight Process , LWP),是程序执行流的最小单元。
一个标准的线程由线程ID ,当前指令指针(PC),寄存器集合和堆栈组成。
在许多系统中,创建一个线程比创建一个进程块 10 --- 100 倍,但这并不是说线程越多越好。
进程和线程的理解:
现代操作系统提出进程的概念,没一个进程都认为自己独自占有所有的计算机硬件资源,
进程就是独立的王国,进程间不可以随便共享数据。
线程可以共享进程的资源,但是线程之间也不是可以随便共享数据。
每一个线程拥有自己独立的堆栈。不一定都实现堆,但是一定实现栈。
4、线程的状态:
| 状态 | 含义 |
| 就绪(ready) | 线程能够运行,但在等待被调度,可能线程刚刚创建启动,或刚刚从阻塞中恢复,或被其他线程抢占。 |
| 运行(running) | 线程正在运行 |
| 阻塞(blocked) | 线程等待外部事件发生而无法运行,如I/O操作 |
| 终止(terminal) | 线程完成,或者退出,或被取消 |
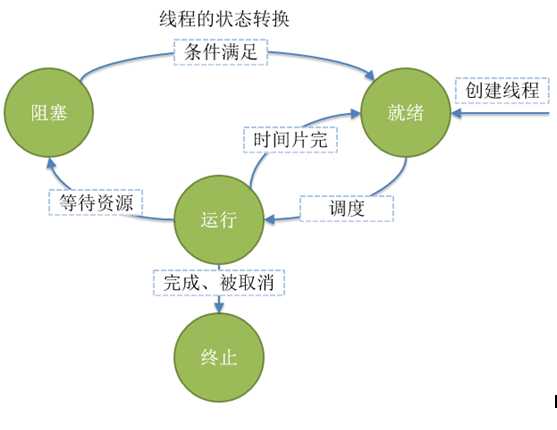
注:针对单cpu单核:cpu一次只能调度一个线程,要不抢占,要不优先,要不排队。
单cpu单核,轮询对线程调度,每个线程调度时间片由于优先级也有不同。
5、Python中的进程和线程。
进程会启动一个解释器进程,线程共享一个解释器进程。
6、Python的线程开发:
Python的线程开发使用标准库threading
7、Thread类
Thread原码: def __init__(self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None):
target:线程调用的对象,就是目标函数
name:为线程起一个名字
args:为目标函数传递实参,元组(注意一个元素的时候,逗号)
kwarg:为目标函数关键字传参,字典
8、线程启动:
1 import threading 2 3 # 最简单的线程程序 4 def work(): 5 print(‘working‘) 6 print(‘finished‘) 7 8 t = threading.Thread(target=work, name=‘work1‘) 9 10 t.start()
线程之所以执行函数是因为线程中就是执行代码的,而最简单的封装就是函数,所以还是函数调用。
函数执行完,线程也就退出了。
如果不让线程退出,或者让线程一直工作。通过死循环。
1 import threading 2 import time 3 4 def work(): 5 while True: 6 time.sleep(1) 7 print(‘working‘) 8 print(‘finished‘) 9 10 t = threading.Thread(target=work, name=‘work1‘) 11 12 t.start()
9、线程退出:
Python没有提供线程退出的方法,线程在下面的情况下退出:
1、线程函数内语句执行完毕
2、线程函数中抛出未处理的异常。
1 import threading 2 import time 3 4 def work(): 5 count = 0 6 while True: 7 if count > 5: 8 break 9 # raise Exception(‘count‘) 10 # return 也是可以的 11 time.sleep(1) 12 print(‘working‘) 13 count += 1 14 15 t = threading.Thread(target=work, name=‘work1‘) 16 t.start() 17 print(‘--------------------‘) 18 print(‘======= end =======‘)

1 -------------------- 2 ======= end ======= 3 working 4 working 5 working 6 working 7 working 8 working
注:Python的线程没有优先级,没有线程组的概念,也不能销毁、停止、挂起,那也就没有恢复、中断了。
10、线程的传参
1 import threading 2 import time 3 4 def add(x, y): 5 print(‘{} + {} = {}‘.format(x, y, x + y), threading.current_thread().ident) 6 7 t1 = threading.Thread(target=add, name=‘add‘, args=(4, 5)) 8 t1.start() 9 10 time.sleep(2) 11 12 t2 = threading.Thread(target=add, name=‘add‘, args=(5,), kwargs={‘y‘:4}) 13 t2.start() 14 15 time.sleep(2) 16 17 t3 = threading.Thread(target=add, name=‘add‘, kwargs={‘x‘:4, ‘y‘:5}) 18 t3.start()
1 4 + 5 = 9 8604 2 5 + 4 = 9 9836 3 4 + 5 = 9 10932
注:线程传参和函数传参没有什么区别,本质上就是函数传参。
threading的属性和方法:
| 名称 | 含义 |
| current_thread() | 返回当前线程对象 |
| main_thread() | 返回主线程对象 |
| active_count() | 当前处于alive状态的线程个数 |
| enumerate() | 返回所有活着的线程列表,不包括已经终止的线程和未开始的线程 |
| get_ident() | 返回当前线程的ID ,非0 的整数 |
active_cont, enumerate方法返回的值还包括主线程。
测试:
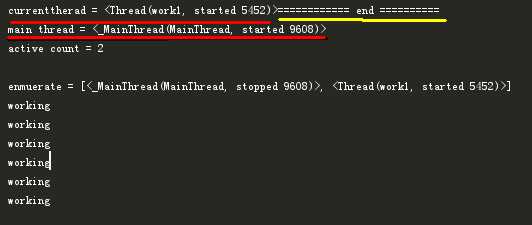
1 import threading 2 import time 3 4 def showthreadinfo(): 5 print(‘currenttherad = {}‘.format(threading.current_thread())) 6 print(‘main thread = {}‘.format(threading.main_thread())) 7 print(‘active count = {}‘.format(threading.active_count())) 8 print(‘enmuerate = {}‘.format(threading.enumerate())) 9 10 def work(): 11 count = 0 12 showthreadinfo() 13 while True: 14 if count > 5: 15 break 16 time.sleep(1) 17 count += 1 18 print(‘working‘) 19 20 t = threading.Thread(target=work, name=‘work1‘) 21 t.start() 22 23 print(‘============ end ==========‘)
结果:可以看到有并行的影子,虽然这是假并行!!!
11、Thread实例的属性和方法
name:只是一个名字,只是个标记,名称可以重名。getName(), setName() 获取,设置这个名词
ident:线程ID, 非0整数,线程启动后才会有ID,否则为None,线程退出,此 ID 依旧可以访问,此ID 可以重复使用。
is_alive(): 返回线程是否活着。
注: 线程的name这是一个名称,可以重复,ID 必须唯一,但是在线程退出后,可以再利用。
测试:
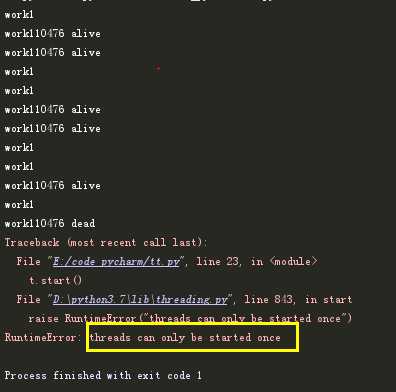
1 import threading 2 import time 3 4 def work(): 5 count = 0 6 while True: 7 if count > 5: 8 break 9 time.sleep(1) 10 count += 1 11 print(threading.current_thread().name) 12 13 14 t = threading.Thread(target=work, name=‘work1‘) 15 t.start() 16 17 while True: 18 time.sleep(1) 19 if t.is_alive(): 20 print(‘{}{} alive‘.format(t.name, t.ident)) 21 else: 22 print(‘{}{} dead‘.format(t.name, t.ident)) 23 t.start()
结果:结果很明确, 线程对象,只能执行一次start,尽管对象还存在。
start(): 启动线程,每一个线程必须且只能执行该方法 一次
run(); 运行线程函数
测试 start():
1 import threading 2 import time 3 4 def work(): 5 count = 0 6 while True: 7 if count > 5: 8 break 9 time.sleep(1) 10 count += 1 11 print(‘working------------‘) 12 13 class MyThread(threading.Thread): 14 def start(self): 15 print(‘start -----------------‘) 16 super().start() 17 18 def run(self): 19 print(‘run -------------------‘) 20 super().run() 21 22 23 t = MyThread(target=work, name=‘work1‘) 24 t.start()
结果:
1 start ----------------- 2 run ------------------- 3 working------------ 4 working------------ 5 working------------ 6 working------------ 7 working------------ 8 working------------
测试 run():
1 import threading 2 import time 3 4 def work(): 5 count = 0 6 while True: 7 if count > 5: 8 break 9 time.sleep(1) 10 count += 1 11 print(‘working------------‘) 12 13 class MyThread(threading.Thread): 14 def start(self): 15 print(‘start -----------------‘) 16 super().start() 17 18 def run(self): 19 print(‘run -------------------‘) 20 super().run() 21 22 23 t = MyThread(target=work, name=‘work1‘) 24 t.run()
结果:
1 run ------------------- 2 working------------ 3 working------------ 4 working------------ 5 working------------ 6 working------------ 7 working------------
总结:start() 方法会调用run() 方法,而run() 方法可以运行函数。
1 ## run() 2 import threading 3 import time 4 5 def work(): 6 count = 0 7 while True: 8 if count > 5: 9 break 10 time.sleep(1) 11 count += 1 12 print(‘working------------‘) 13 print(threading.current_thread().name) 14 15 class MyThread(threading.Thread): 16 def start(self): 17 print(‘start -----------------‘) 18 super().start() 19 20 def run(self): 21 print(‘run -------------------‘) 22 super().run() 23 24 25 t = MyThread(target=work, name=‘work1‘) 26 t.run() 27 28 ## start() 29 import threading 30 import time 31 32 def work(): 33 count = 0 34 while True: 35 if count > 5: 36 break 37 time.sleep(1) 38 count += 1 39 print(‘working------------‘) 40 print(threading.current_thread().name) 41 42 class MyThread(threading.Thread): 43 def start(self): 44 print(‘start -----------------‘) 45 super().start() 46 47 def run(self): 48 print(‘run -------------------‘) 49 super().run() 50 51 52 t = MyThread(target=work, name=‘work1‘) 53 t.start()
结果:
1 ## start 2 start ----------------- 3 run ------------------- 4 working------------ 5 work1 6 working------------ 7 work1 8 working------------ 9 work1 10 working------------ 11 work1 12 working------------ 13 work1 14 working------------ 15 work1 16 17 ## run 18 run ------------------- 19 working------------ 20 MainThread 21 working------------ 22 MainThread 23 working------------ 24 MainThread 25 working------------ 26 MainThread 27 working------------ 28 MainThread 29 working------------ 30 MainThread
使用start方法启动线程,启动了一个新的线程,名字叫work1 运行,但是使用run方法的,并没有启动新的线程,就是在主线程中调用了一个普通的函数而已。
因此,启动线程使用start方法,才能启动多个线程。
run就是单线程的,start是多线程的。
线程适可而止,不能太多,否则时间都浪费到切换上了。
start只能一次,其次ID 在线程消亡后 还会留给之前的线程
run 只是运行线程函数,不会创建线程,依旧还是主线程,在主线程中运行线程函数,
单线程 是 顺序执行,从上往下执行。
start 创建子线程,并通过run执行线程函数。
标签:标记 多核 中间件 int enum 组成 ini 提高 关系
原文地址:https://www.cnblogs.com/JerryZao/p/9763515.html
