标签:rda 增删改查 表达式 好的 pad 比较 class models .com
SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
|
1
|
pip3 install sqlalchemy |
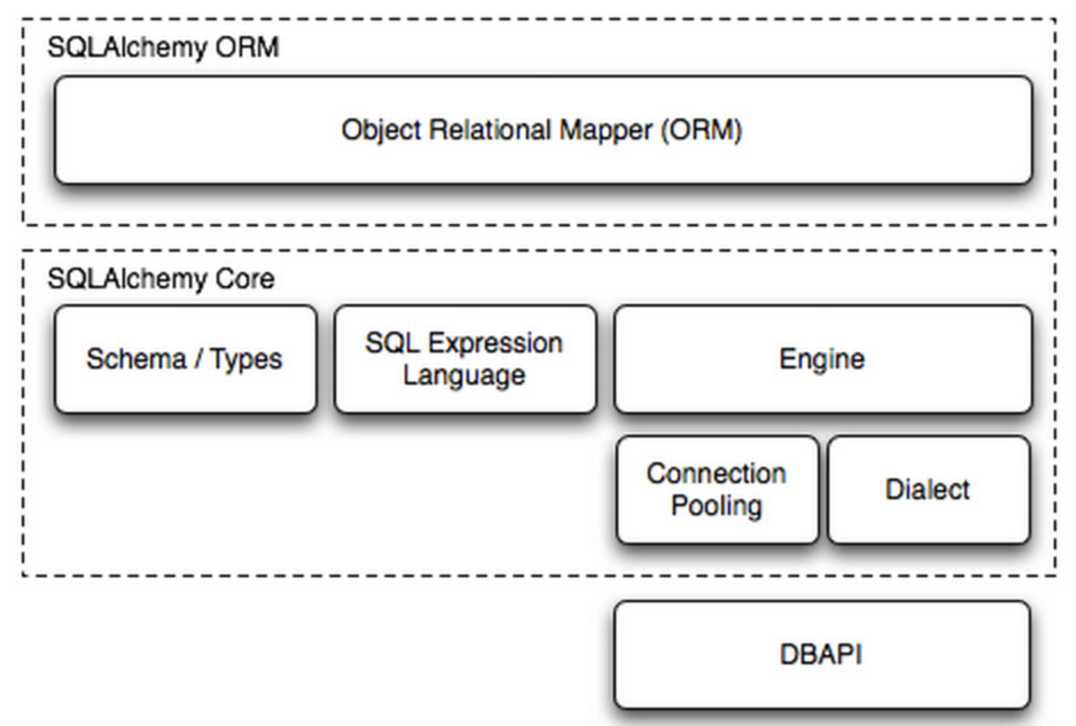
组成部分:
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
import time
import threading
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.engine.base import Engine
engine = create_engine(
"mysql+pymysql://root:123@127.0.0.1:3306/t1?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
def task(arg):
conn = engine.raw_connection()
cursor = conn.cursor()
cursor.execute(
"select * from t1"
)
result = cursor.fetchall()
cursor.close()
conn.close()
for i in range(20):
t = threading.Thread(target=task, args=(i,))
t.start()
 View Code View Code
View Code View Code注意: 查看连接 show status like ‘Threads%‘;
a. 创建数据库表
创建单表 创建多个表并包含Fk、M2M关系指定关联列:hobby = relationship("Hobby", backref=‘pers‘,foreign_keys="Person.hobby_id")
b. 操作数据库
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import Users
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
# 每次执行数据库操作时,都需要创建一个session
session = Session()
# ############# 执行ORM操作 #############
obj1 = Users(name="alex1")
session.add(obj1)
# 提交事务
session.commit()
# 关闭session
session.close()
多线程执行示例 基本增删改查示例 常用操作 原生SQL语句 基于relationship操作ForeignKey 基于relationship操作m2m 其他import threading from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from models import Users # 与数据库进行连接,并创建连接池 engine = create_engine( "mysql+pymysql://root@127.0.0.1:3306/flask?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=10, # 连接池大小,一次性最多建立的连接数 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) # 生成会话类 Session = sessionmaker(bind=engine) def task(arg): # 每次执行数据库操作时都要创建一个会话 session = Session() session.query(Users).all() session.close() for i in range(20): t = threading.Thread(target=task, args=(i,)) t.start()
对于上述方式,每个线程里执行数据库的操作都要创建一个新的session会话,以保证当前线程操作的只是自己的会话对象,防止其他会话对象对当前线程中数据库操作的影响。但是这样不足之处在于需要为每个线程都要手动的创建session会话,那有没有其他比较好的方法为我们自动创建会话而且还能保证线程之间数据的安全?答案肯定是有的。
import threading from sqlalchemy.orm import sessionmaker,scoped_session from sqlalchemy import create_engine from models import Users # 与数据库进行连接,并创建连接池 engine = create_engine( "mysql+pymysql://root@127.0.0.1:3306/flask?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=10, # 连接池大小,一次性最多建立的连接数 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) # 生成会话类 Session = sessionmaker(bind=engine) # 使用scoped_session创建一个单例的session,不需要为每次操作数据库创建会话 session = scoped_session(Session) def task(arg): session.query(Users).all() session.close() for i in range(20): t = threading.Thread(target=task, args=(i,)) t.start()
使用scoped_session创建一个全局的会话对象,该对象使用threading.local会为每一个线程开辟一个内存空间,并实例化一个原来Session类对象,将该对象保存到所创建的线程中去,从而保证了线程之间的数据安全。
标签:rda 增删改查 表达式 好的 pad 比较 class models .com
原文地址:https://www.cnblogs.com/liuyinzhou/p/9775755.html