标签:else rev 技术 员工 结构图 table 获取 关键字 元组
TDSQL 全时态数据库系统--核心技术Design
本节讨论T-TDSQL的关键之处,即影响T-TDSQL架构的设计之处。一是新的数据模型—全时态数据模型,表达了T-TDSQL的双时态语义,其中对于数据的事务时态,首次提出全态数据的概念,以刻画数据的生命周期。二是对于新的数据模型,如何在基于关系模型的数据库中实现存储,全时态数据的存储,使得具有全时态语义的数据有了计算的依据;本文提出的全时态数据模型的实现,以MySQL为载体。第三是全态数据的读取,关键是历史态数据的可见性判断算法的实现,文献对此进行了详细的描述,本文对核心算法介绍。
全时态数据模型
本文采用了基于关系数据模型而设计的双时态数据模型。其与普通的关系数据模型主要的区别在于以下两点,一是数据具有状态属性,二是数据具有时态属性。具有这两种属性的数据模型,称为全时态数据模型。
数据模型
数据的状态属性,标识数据的生命周期轨迹。数据的生命周期分为三个阶段,每个阶段刻画数据的不同状态属性,以标识数据的生命周期轨迹中所处的状态。
当前态(Current State):数据项的最新版本的数据,是处于当前阶段的数据。处于当前阶段的数据的状态,称为当前态。
历史态(Historical state):数据项在历史上的一个状态,其值是旧值,不是当前值。处于历史阶段的数据的状态,称为历史态。一个数据项的历史态,可以有多个,反映了数据的状态变迁的过程。处于历史态的数据,只能被读取不能再被修改或删除。
这三个状态,涵盖了一个数据项的生命周期,合称为数据全态(full-state),或称为全态数据。在MVCC机制下,数据的三种状态均存在;在非MVCC机制下,数据只存在历史态和当前态。
当前态:MVCC或封锁并发访问控制机制下,事务提交后的数据的新值处于当前态。
历史态:MVCC机制下,当前活跃事务列表中最小的事务之前的事务生成的数据,其状态处于历史态。在封锁并发访问控制机制下,事务提交后,提交前的数据的值变为历史态的值,即数据项的旧值处于历史态。
数据的双时态属性,分别为有效时间属性、事务时间属性。
有效时间属性表示数据表示的对象在时间属性上的情况。如Kate中学起止时间是2000-09-01到2003-07-30,而大学起止时间是2003-09-01到2007-07-30,这里的时间就是有效时间。
事务时间属性表示数据的某个状态的时间发生时刻。数据具有其时态属性,即在何时数据库系统进行了什么样的操作。某项操作在数据库系统内被封装为事务,而事务具有原子性。因此,我们采用了事务标志来标识一个数据的事务时态属性。
从形式上看,有效时间属性和事务时间属性,在数据模型中用普通的用户自定义字段进行表示,只是用特定的关键字加以描述,供数据库引擎进行约束检查和赋值。
但是,一个定义有或不定义有双时态属性的数据项,其生命周期中一定存在全态形态,只是其全态形态的形成是通过事务时间属性和DML操作触发的。
数据模型示例
例如:对于员工-薪水这一关系,我们可以建立对应的双时态数据模型,如图2所示。其中,有效时间中表达“至今有效”,用关键字NOW;事务时间中表达“尚未更改”,用关键字UC,(Until Changed)。之后,数据经历如下操作:
op1. 2011-02-01 00:00:00添加新账户(4, ‘Jimmy’, 100, 2010-01-01,NOW);
op2. 2012-01-01 00:00:00更新Kim的余额为200;
op3. 2013-01-01 00:00:00调整Kim的余额为300;
图2中的数据经过上述操作,结果变迁为图3所示,图3表示了上述操作完成后的时刻处于全时态的数据状况和变迁过程相关操作。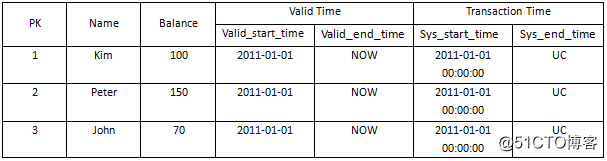
图2 初始的双时态数据模型图(用户表)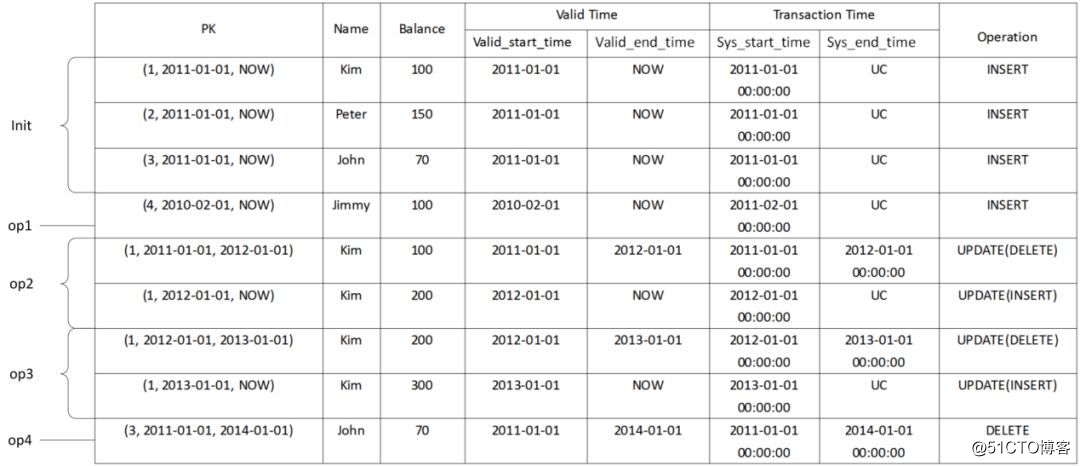
图3变迁的双时态关系模型图(历史表)
历史态数据存储
MySQL/InnoDB,PostgreSQL等采用MVCC技术的关系型数据库,对于多版本的管理方案也不尽相同。MySQL/InnoDB将历史态版本的数据通过Undo Log在内存中保存。PostgreSQL将历史态版本元组直接链接在最新版本元组后,因此元组的多个版本在同一个数据页面上(跨页情况存在)。MySQL/InnoDB通过Purge操作来对历史态版本进行清理, PostgreSQL通过Vacuum来对历史态数据进行清理。
主流数据库(关系型和非关系型)不会保存历史态数据,丢弃了有价值的历史态数据。而历史态数据的价值,可以分为五个方面,第五章针对全时态类应用价值进行了讨论。
本节将基于MVCC技术,讨论对历史态数据进行存储的方案。
数据转储时机
相对于只支持当前态数据获取的数据库系统而言(如Oracle、MySQL/InnoDB、PostgreSQL),对于历史态数据的转储,需要考虑两个问题:
何时数据会被丢失而需要进行转储?
在历史态数据被定期清理时,是将历史状态的数据进行转储的最佳时机,此时数据库系统已经不再需要对历史态数据进行DML操作。
由于系统清理是一种批量操作,所以历史态数据也是采用类似的批量转储策略。当数据清理线程/进程工作时,转储线程/进程收集历史态数据,插入到已经定义好的历史表结构中。如图4所示,给出了在MySQL/InnoDB系统中,一种可行且有效的数据转储方式。原表中被删除或修改的历史态版本会转储到历史表中,并在历史表中对数据进行重新组织,从而保证高的读取效率。
在图4中,我们延用了3.1.2节中定义的例子,并多做一步操作op5.调整Kim的余额为400。从而展示了完成五步操作后全态数据的分布情况。元组“1,Kim,300”元组,假设还有并发事务在使用,因此为过渡态。图中历史态数据的转储,将会在历史态数据在UndoLog中被清除时发生。Undo Log中的一条元组(Undo Rec)元组了对应一条元组的历史版本,Purge操作会将需要清理的Undo Log读入内存中,我们通过对Undo Rec的解析,将元组历史版本重新以物理元组的形式组织起来,存入到历史表中,从而做到历史态数据的持久化存储。
转储操作是一个原子操作,同时作为一个内部事务执行,确保转储操作语义正确。未被转储的历史态数据受系统旧有的故障恢复机制保护,确保不丢失。被转储后的历史态数据被持久化存储。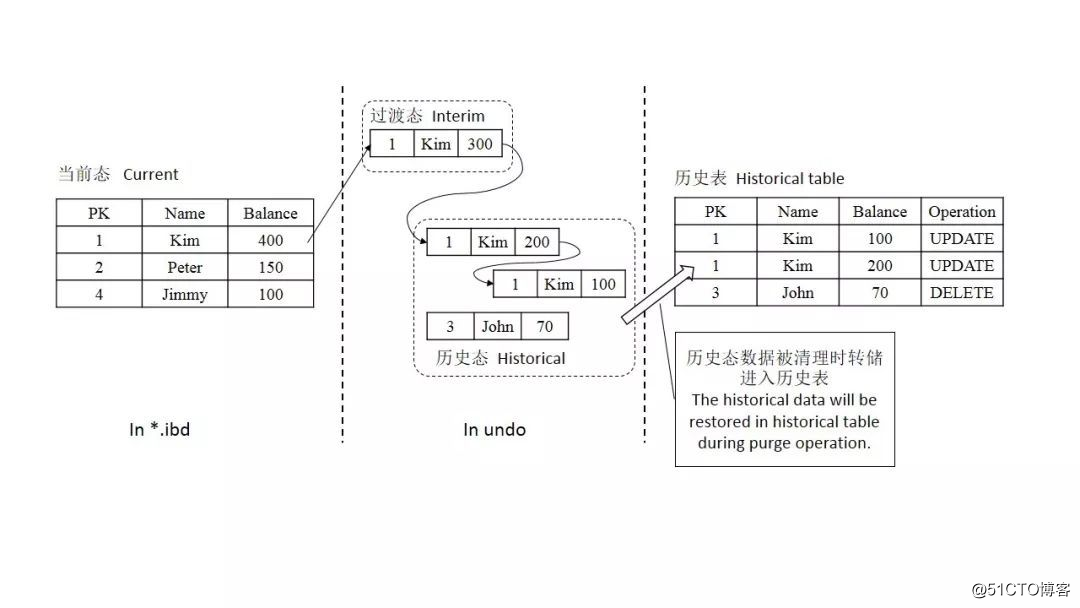
图4 基于MySQL/InnoDB实现的历史态数据转储原理图
存储格式
全时态数据模型,提供了全态语义和时态语义。
全态语义和时态语义对应的列信息,由用户在CREATE TABLE语句中指定。而元组的结构,如图5所示,包括两部分,一是系统列,二是用户定义列。系统列中的事务标识(Trx_id)表示本条版本是哪个事务操作后产生的版本。全态语义和Trx_id客观上表示了事务时态的语义,与表示有效时间的时态语义结合,使得全时态数据模型支持了双时态时态数据库的语义。
在用户表上执行DML操作,需要为历史态版本的全态和时态对应列信息赋值。
历史态的数据,存储到历史表。历史表的结构和用户原表的结构相近,只多一个列用于表示版本生成时对应的DML操作类型,值为enum(Operation) = {更新,删除,插入}={U,D,I }={3,2,1 }。
历史表禁止DML 操作,保证历史态数据的安全性。
从系统的角度看,历史表中的数据,只允许进行脱机和联机操作。
图5 历史表元组结构图
存储模式
根据用户对历史态数据的计算需求,在历史表的定义中可以指定的历史态数据的存储模式,当历史态数据转储到历史表中时,按照存储模式,把历史态数据转储为行存格式或者列存格式。
行存格式与传统的关系型数据库没有本质区别。
列存格式的数据,支持MySQL体系中Column Store数据格式。另外将支持Parquet、RCFile、ORCFile等列存格式。
转储效率
对于列存格式的存储模式,提供内存式转储过渡区,用以缓冲行格式的待转储的历史态数据。等到转储过渡区满,利用压缩技术重新组织行存格式为列存。如图6所示。
转储过渡区由若干个连续的内存BLOCK/PAGE组成,每个BLOCK/PAGE大小等同于数据库系统初始化阶段指定的BLOCK/PAGE大小。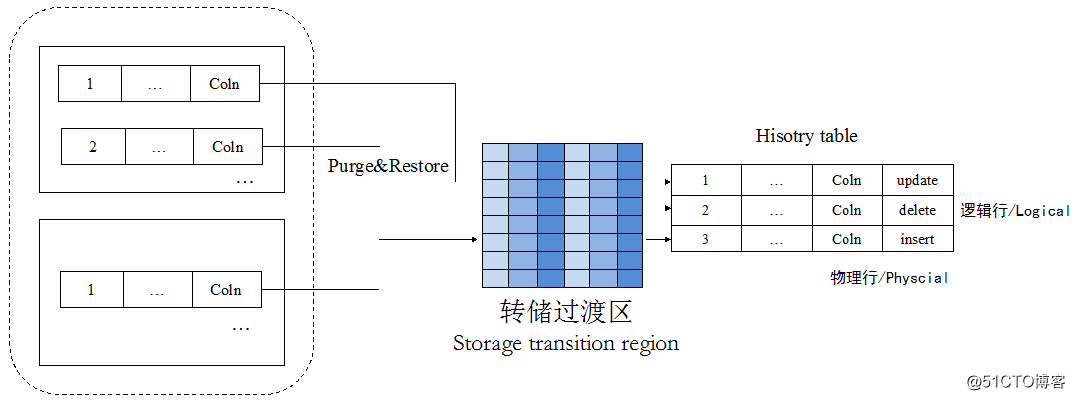
图6 转储过渡区原理图
同一个数据项可存在多个历史态的版本。
哪个历史态的版本可以被某个快照差读取,是由历史态数据可见性判断算法决定的。此算法是一种新算法,有别于诸如PostgreSQL、MySQL/InnoDB中的版本可见性判断算法。之前的算法可以称之为当前态数据可见性判断算法,能读出全态数据中的当前态和过渡态数据。
历史态数据可见性判断算法与当前态数据可见性判断算法这两个算法合称为全态数据可见性判断算法。
历史态数据的可见性判断,不再能够依赖活跃事务链表,这是因为对于历史上任何时刻,其对应的“当前活跃事务列表”因时间流逝而不能够被获取。所以历史态数据的可见性判断算法有别与当前态数据的可见性判断算法。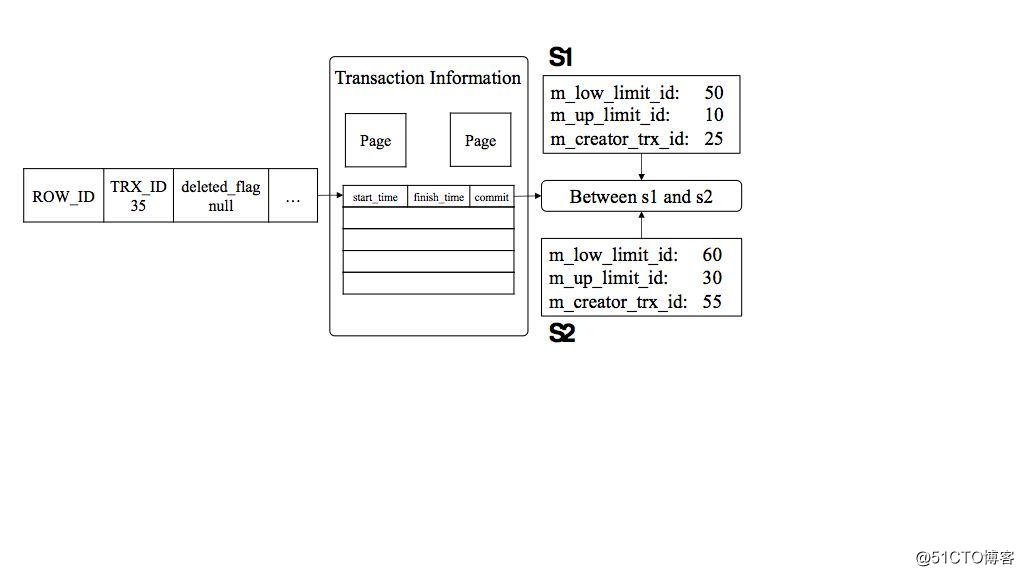
图7 历史态版本可见性判断示例图
图7给出了一个使用历史态数据可见性判断算法、利用历史快照差读,获取历史态数据的实例。S1和S2是两个历史快照,存储了快照的创建时间和其他相关信息。基于算法1 [1],即可判断一条元组版本在给出快照差中的可见性,并给出产生本条历史态元组的操作。算法1输入为两个事务快照s_start和s_stop,以及一条历史态的元组版本r_i,输出为当前元组版本的可见性opT,0代表不可见,1代表该版本是插入操作产生的, 2代表该版本是更新操作产生的,3代表该版本是删除操作产生的。
算法1 历史态数据可见性判断算法
1 function HISTORY_VISIBILITY_JUDGEMENT (r_i, s_start, s_stop) 2 opT = 0 3 if s.start.createTime<r_i.commitTime<s_stop.createTime then 4 if r_i.isDelete then 5 opT = 3 6 else 7 if r_i.prev() then 8 opT = 1 9 else 10 opT = 2 11 else 12 opT = 0 13 end if 14 end function
标签:else rev 技术 员工 结构图 table 获取 关键字 元组
原文地址:http://blog.51cto.com/13961945/2299250