标签:判断 main 平均数 限制 失效 元组 station poj 优化
前言:上次算法课主要对分治思想进行了介绍,在这里进行以下总结和几个例子的应用。
一、分治算法
设计过程:(1)分解:将问题分解为子问题,子问题的形式与原问题是一样的,只是规模减小了。
(2)求解:递归地求解出子问题。
(3)合并:将子问题的解组合成原问题的解。
分治算法中最重要的就是递归求解子问题,求解递归式估计出算法的复杂度一般可以有三种方式:
(1)代入法:猜测一个界,然后用数学归纳法证明这个界是正确的。
(2)递归树法:将递归式转为一棵树,其结点表示不同层次的递归调用产生的代价。
(3)主方法:即Master定理,主要求解以下形式的递归式:T(n)=aT(n/b)+f(n);该方法有三种情形,只要记住这三种情形,可以很快速的求解出递归式:
【1】若对某个常数€>0有f(n)=O(nlogba-€)则T(n)=Θ(nlogba);
【2】若f(n)=Θ(nlogba),则T(n)=Θ(nlogbalgn);
【3】若f(n)=Θ(nlogba+€),则T(n)=Θ(f(n));
二、应用例子:
(1)设X[0:n-1]和Y[0:n-1]为两个数组,每个数组中含有n个已排好序的数,设计一个算法复杂度为O(logn)的分治算法,找出X和Y中2n个数中的中位数。(中位数:个数为奇数:中间位置上的数;个数为偶数,中间两个数的平均数)
思路:对于两个已排好序的数组,可以寻找两个数组中的中位数,只需要进行n次的比较,时间复杂度可以为O(n),代码如下
int main(void)
{
int x[] = { 2, 4, 5, 11, 12, 13, 14 };
int y[] = { 1, 3, 6, 7, 8, 9, 10 };
int a1, a2, n1, n2, n;
n = n1 = n2 = 0;
while (n < 7)
{
a1 = x[n1] <= y[n2] ? x[n1++] : y[n2++];
n++;
}
a2 = x[n1] <= y[n2] ? x[n1++] : y[n2++];
printf("%lg\n", (double)(a1 + a2) / 2);
return 0;
}
使用分治法设计算法的思路如下:
1.分别取两个数组的中位数:若n为奇数,则x=X[n/2],y=Y[n/2];若n为偶数,则x,y分别为两个数组中间两个数的平均数。并设两个数组的左右边界分别为:XLeft,XRight;YLeft,YRight.
2.比较两个中位数的大小:
(1)若x<y:则舍去x之前的数和y之后的数,形成新的子数组:X[n/2:XRight],Y[YLeft:n/2]
(2)若x>y:则舍去x之后的数和y之前的数,形成新的子数组:X[XLeft:n/2],Y[n/2:YRight]
(3)若x=y:则该数即是中位数,直接输出即可。
3.若是步骤2中的前两种情形,则进行递归,每次都筛去一半的数,直至两个子数组的长度为1,递归结束,输出数组中两个数的平均数。
复杂度分析:
T(n)=O(1) n=1;T(n)=T(n/2)+1 n>1;
使用Master定理,f(n)=nlog21 =1,所以T(n)=O(logn)。
(2)有一实数序列a1,a2,....an,若i<j且ai>aj,则(ai,aj)形成了一个逆序对,请使用分治算法求整个序列中逆序对个数,并分析算法时间复杂度。
思路:看到这个问题的第一个想法是建立两层循环:
int i,j;
int count=0;
for(i=1;i<=n;i++)
{
for(j=i+1;j<=n;j++)
{
if (ai>aj)
count++;
}
}
这种算法的时间复杂度应该为O(n2)
分治算法设计思路:将该实数序列分解为两个等大的子序列,则逆序对存在于左序列、右序列及左右序列之间,递归求解左序列、右序列中的逆序对,而左右序列之间的逆序对需要合并,若直接进行合并,则遍历需要的时间复杂度为(n/2)*(n/2),复杂度并未得到改善,所以需要对合并进行优化,若对两个排好序的左右序列进行合并,则不影响逆序对的结果,并且只需要遍历n次,即合并的时间复杂度为O(n).
过程:
[1].分解:将原序列分为两个等大的实数序列,即左序列,右序列
[2].求解:递归求解左序列、右序列中的逆序对
[3].合并:在合并的过程中排序并计算逆序对的个数。比如两个排好序的数组{1,3,4,6}和{2,7,8,9}:1<2,左序列中往后移;3>2,则说明左序列中后面的数都大于2,所以有3个逆序对(3,2)(4,2)(6,2),右序列中指针向后移;3<7,左序列中往后移,4<7,往后移,6<7,往后移,至此已经没有逆序对了。
仔细想这个过程和归并排序非常像,只是在合并时计算逆序对的个数。
时间复杂度分析:
T(n)=2T(n/2)+O(1)+O(n);依次为求解子问题的代价,分解时的代价,及合并时的代价。利用Master定理:a=2,b=2,nlog22 =n,f(n)=n,所以T(n)=O(nlogn)
(3)求解天际线问题
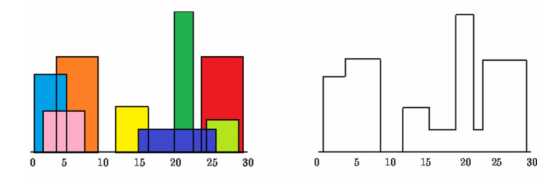
给定n座建筑物B[1,2,...,n],每个建筑物B[i]表示为一个矩形,用三元组B[i]=(ai,bi,hi)表示,其中ai表示建筑左下顶点,bi表示建筑的右下顶点,hi表示建筑的高,请设计一个O(nlogn)的算法求出这n座建筑物的天际轮廓。例如,左下图所示中8座建筑的表示分别为(1,5,11),(2,7,6),(3,9,13),(12,16,7),(14,25,3),(19,22,18),(23,29,13)和(24,28,4),其中天际轮廓如右下图所示可用9个高度的变化(1,11),(3,13),(9,0),(12,7),(16,3),(19,18),(22,3),(23,13)和(29,0)表示。另举一个例子,假定只有一个建筑物(1,5,11),其天际轮廓输出为2个高度的变化(1,11),(5,0)。
【思路】:若只有一个建筑,那么输出的点一定是建筑的左上和右下顶点,根据这个思路,使用分治法解决。
算法描述:
(1)定义三个变量hl,hr,h,全部初始化为0,分别记录左集合、右集合及总体高度的变化值;
(2)遍历左建筑点L和右建筑点R:选取横坐标较小的点,若该点在左集合中,则hl为该点的纵坐标,比较hl与hr,选取二者的较大值替换该点的纵坐标,再与h进行比较,若纵坐标与h相等,则舍弃该点;若纵坐标与h不等,则保留该点,且当纵坐标大于h时,将h替换为纵坐标的值,h始终为高度的较大值。
(3)当左集合或右集合遍历完毕时,另一方剩余的点直接取到。
可以用一个例子模拟该过程进栈出栈的过程:
建筑群集合为(1,5,11)(2,7,6):
hl=0,hr=0,h=0;
①left[0].x=1<right[0].x=2;(1,11)进栈。此时hl=11,hr=0,h=max(hl,hr)=11;保留该点;左集合中右移left[1]。
②left[1].x=5>right[0].x=2;(2,6)暂时进栈;此时hr=6,hl=11,h=11;则将right[1].y=max(hl,hr)=11;此时right[1].y=h:舍弃该点,(2,11)出栈;右集合右移,right[1]
③left[1].x=5<right[1].x=7;(5,0)暂时进栈;此时hr=0,hl=11,h=11;则left[1].y=max(hl,hr)=11;此时left[1].y=h:舍弃该点,(5,11)出栈。左集合右移
④左集合遍历完毕,直接将右集合中剩余的点入栈
(4)POJ3714:在与联邦的战斗接连失败后,帝国撤退到最后的据点。帝国依靠其强大的防御系统,击退了六次联合进攻。在经历了几个不眠之夜后,阿瑟将军注意到防御系统的唯一弱点是它的能源供应。该系统由N个核电站负责,并拆除其中任何一个将使该系统失效。这位将军很快就开始了对这些电台的突袭,这些特工被带进了要塞。不幸的是,由于帝国空军的袭击,他们未能到达预期的位置。作为一名经验丰富的将军,亚瑟很快意识到他需要重新安排这个计划。他现在想知道的第一件事是,哪个代理是离任何发电站最近的。你能不能帮助将军计算一个代理和一个站之间的最小距离?
【思路】:此题是对最近点对问题的一个应用,最近点对问题中最后的解可能出现在三种情形中:左问题集合;右问题集合;一个点在左集合,一个点在右集合中。而POJ3714的这道题目相当于对最后的解进行了限制:必须是两个集合中的点,所以我们只需在求最近点对的问题上加上一个限制:判断最后求得的两个点是否处于两个集合中,判断时可使用“标志位”。具体的算法可以使用两种方法:
【1】只进行了x轴预排序
f(Q,i,j)//Q已经按x轴进行了排序
{
if(j-i<=c)
{
直接计算距离,比较得到最小距离;
return;
}
di=f(Q,i,(i+j)/2-1);
dj=f(Q,(i+j)/2,j);
d=min{di,dj};
A:临界区,存入中位线范围d的所有点;
对A中的所有点按y轴排序;//该过程每次调用都对y进行排序,时间复杂度较大
计算A中点间的距离;
}
【2】空间换时间,对集合中的点进行X,Y预排序
算法描述如下:
(1)输入点集合sa[2n]:为station[n]集合中的点加上标志flag=ture,为agent[n]中的点加上标志flag=false。
(2)预排序:对sa集合中的点按X轴从小到大排序;按y轴从小到大排序并记录下标值。(通过预排序用空间换时间,降低算法的时间复杂度)
(3)递归调用求解最近点对的方法
对于临界区中的点,因为已经进行了y轴预排序,所以直接进行扫描,对每一个点计算按y轴排序后面的6个点(鸽巢原理)与它的距离,并与两个子集合中的最小距离进行比较。
标签:判断 main 平均数 限制 失效 元组 station poj 优化
原文地址:https://www.cnblogs.com/wangjm63/p/9748749.html