标签:宝贝 程序员 代码 width dia 接口索引 添加 对象 对象类型
Java运行详解
计算机只认识0、1,对应于电路中低电平和高电平。因此,早期程序员使用特定的0、1串操控计算机,从而达到想要的目标效果。这些0、1串就称作指令,也叫机器码(比如0000代加载,000代表寄存器A,000000000000 代表地址为0的存储器,所以0000,0000, 000000000000 代表 LOAD A, 0-把存储器0中的值加载到寄存器A),指令集合即为机器语言。机器语言对计算机友好,但对人类来说直观性就很差了。此外,因为构成不同的计算机处理器的电子元件不同,因此想要达到相同的指令效果,不同品牌的计算机需要的0、1串指令也不同,也就是说一个指令集是和具体的计算机处理器绑定的。
针对0、1串构成的机器语言的复杂性,人们使用助记符和地址符号来减轻困难(比如说用ADD表示加,EAX表示寄存器A),在程序运行的时候,先要由汇编器将符号翻译为机器语言。这样稍微加强了编程语言的可读性。这些符号语言就叫汇编语言,汇编语言虽然相较机器语言可读性稍强,但仍然不够直观,同时它和机器语言一对一翻译过来,也是和特定的计算机绑定的。
机器语言和汇编语言都称为低级语言,与之相对的是高级语言,现在我们常用的java,c,c++,js等都属于高级语言。高级语言的语法和结构更类似人类使用的自然语言,更容易学习、使用,降低开发门槛,提高了开发效率。但计算机并不能理解高级语言,所以在运行时,高级语言需要先翻译为机器码,然后才能被计算机认可。高级语言翻译过程有两种形式,一是逐句翻译为机器码,称为解释;二是先将整个程序翻译为机器码,然后再在机器上执行整份机器码,这种称为编译。高级语言运行过程需要先翻译为机器语言,带来额外的负担,在某些追求性能的场景,这些负担是致命的,所以高级语言并不能完全取代低级语言。使用高级语言还是低级语言就要看具体场景需求了
高级语言虽然更易理解,但有些语言并没有完全和计算机平台解耦。比如c语言,在windows和linux两种操作系统上语法库并不是完全一样的,在编写程序时就需要考虑适用的平台。java是一种高级语言,它具有平台无关性-“一次编写,到处运行”。同一份java代码,可以在不同的计算机系统上运行。这是怎么实现的呢?
Java定义了一种中间文件格式,class类文件。运行时,java代码先编译为class类文件,然后载入特定的虚拟机,由虚拟机再翻译为平台相关的机器语言并执行。这个过程的关键在于不同的虚拟机认识统一格式的class文件,能够将class文件解释为对应平台的机器语言。比如针对一份java代码编译出来的class文件,window版的虚拟机,将class文件解释为window版的机器语言,linux版的虚拟机解释为linux版的机器语言。这样就让程序员编写代码不用考虑平台的因素了。接下来就看看中间文件格式class文件的具体结构。
Class文件内容可以分为两种数据类型:无符号数和表。其中无符号数包括u1,u2,u3,u4,分别代表1个字节,2个字节,3个字节和4个字节。无符号数可以表示数字、UTF8编码的字符串。表是由多个无符号数或者其他表构成的数据结构,以_info结尾。可以看出Class文件的基础单位是8位的字节,而当遇到多个字节构成数据项时,是按照高位在前的顺序排列(Big-Endian)。
Class文件的组成数据项按先后顺序如下表所示:
|
类型 |
名称 |
数量 |
|
u4 |
magic魔数 |
1 |
|
u2 |
minor_version次版本号 |
1 |
|
u2 |
major_version主版本号 |
1 |
|
u2 |
Constant_pool_count常量池计数 |
1 |
|
cp_info |
constant常量池 |
Constant_pool_count |
|
u2 |
Access_flag访问标志 |
1 |
|
u2 |
This_class类索引 |
1 |
|
u2 |
Super_class父类索引 |
1 |
|
u2 |
Interfaces_count接口索引计数 |
1 |
|
u2 |
interfaces接口池 |
Interfaces_count |
|
u2 |
Fields_count 字段表计数 |
1 |
|
field_info |
Fields |
Fields_count |
|
u2 |
Methods_count方法表计数 |
1 |
|
method_info |
methods方法池 |
Methods_count |
|
u2 |
Attributes_count 属性表计数 |
1 |
|
attribute_info |
Attributes |
Attributes_count |
Class文件按照上表的数据项顺序紧凑地排序,无分隔符。
可以使用jdk自带的分析class文件字节码工具javap将class文件转化为字符形式,如javap –verbose Test.class。
2.1 magic魔数
魔数的作用是标识文件格式,之所以不用文件后缀名是因为文件后缀名容易被更改。Class文件的前四个字节即魔数,十六进制固定为:0xCAFEBABE(咖啡宝贝)。
2.2 version版本号
class文件中紧接魔数的是2字节的次版本号和 2字节的主版本号。java主版本号从45开始,jdk1.1之后的每个大版本依此加1(如jdk2为46,jdk7为51),次版本号为0~65535。Java虚拟机严格要求只能执行不能超过其版本的class文件,比如jdk1.1只能执行45.0~45.65535的class文件,jdk7只能支持45.0~51.65535的class文件。
2.3 constants_pool常量
Class文件中,相同数据项的集合都是以一个容量计数值,加上该计数值个数据项组成。比如常量池,首先是一个constants_pool_count,之后是constants_pool_count个constants。
常量池容量计数值count是一个u2无符号数,代表接下来真正的常量有count-1个,之这是因为规定常量池索引从1开始,不分配索引0则是为了满足某些指向常量池的数据在特定情况下不需要引用任何一个常量的情况。
常量池是class文件的资源库,存放了字面量、类和接口全限定名、字段名称和描述符、方法名称和描述符。总共有14种类型,每种类型都有不同的表结构。但统一的时每种表结构都是以一个u1类型的tag标志位开始,代表该常量的类型。具体每种常量结构如下表所示:
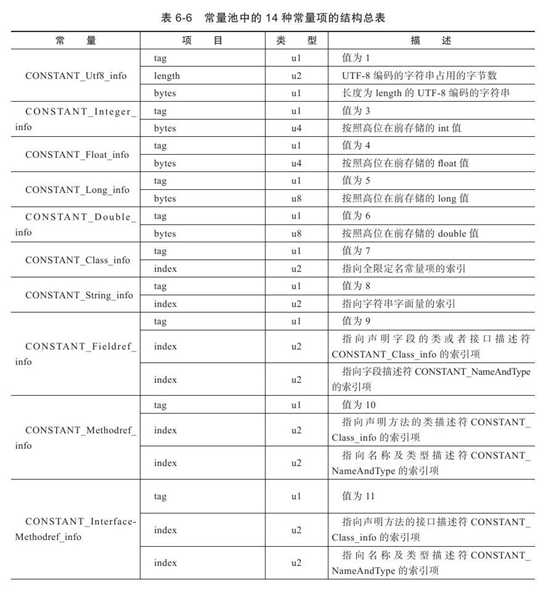
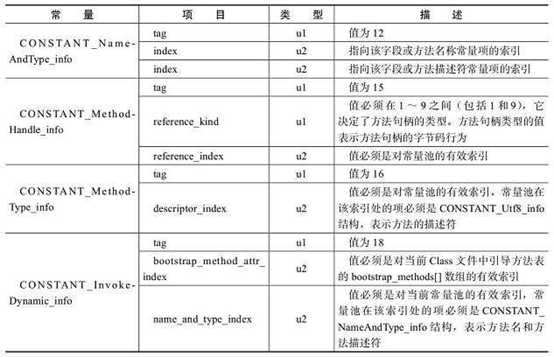
2.4 access_flag访问标志
接下来是一个u2类型的访问标志位,该位有16位,目前只使用了8位,每一位根据0、1值代表当前类的不同访问信息,剩余8位一律为0。具体标志位及其含义如下图所示:
|
标志名称 |
标志值 |
含义 |
|
ACC_PUBLIC |
0x0001 |
是否位public类型 |
|
ACC_FINAL |
0x0010 |
是否被申明为final,只有类可设置 |
|
ACC_SUPER |
0x0020 |
是否允许使用invokespecial字节码指令的新语义(该指令语义在jkd1.0.2发生过改变) |
|
ACC_INTERFACE |
0x0200 |
是否是接口 |
|
ACC_ABSTRACT |
0x0400 |
是否为abstract,对于接口和抽象类为真 |
|
ACC_SYNTHETIC |
0x1000 |
是否并非由用户代码产生 |
|
ACC_ANNOTATION |
0x2000 |
是否是注解 |
|
ACC_ENUM |
0x400 |
是否是枚举 |
2.5 this_class类索引
接下来是一个u2类型的索引,指向常量池中代表这个类全限定名的CONSTANT_Class_info数据项。(全限定名就是把类全名中的.换为/)
2.6 super_class父类索引
父类索引类型同类索引,也是CONSTANT_Class_info。Java中除Object类以外,所有类都有父类,即super_class索引项不为0,而Object类的super_class索引项是0代表为空。
2.7 interfaces 接口索引集合
接口索引集合先有一个u2类型的计数值,代表后续有多少个接口索引,接口索引也是u2类型的常量池。接口顺序是完全按照类implements(接口extends)语句之后的顺序。
2.8 fields字段表集合
字段表集合同样由一个fields_count字段表计数值加fields_count个字段表组成。Fields_count还是u2类型。字段表结构如下:
|
类型 |
名称 |
数量 |
|
u2 |
Access_flags访问标志 |
1 |
|
u2 |
Name_index字段名索引 |
1 |
|
u2 |
Descriptor_index 描述符索引 |
1 |
|
u2 |
Attributes_count 属性表计数值 |
1 |
|
Attribute_info |
Attributes属性表 |
Attributes_count |
l 首先是类似于类访问标志的一个u2类型的字段访问标志,目前有9位在用标志位,具体含义如下图所示:
|
标志名称 |
标志值 |
含义 |
|
ACC_PUBLIC |
0x0001 |
是否public |
|
ACC_PRIVATE |
0x0002 |
是否private |
|
ACC_PROTECTED |
0x0004 |
是否protected |
|
ACC_STATIC |
0x0008 |
是否static |
|
ACC_FINAL |
0x0010 |
是否final |
|
ACC_VOLATILE |
0x0040 |
是否volatile |
|
ACC_SYNTHETIC |
0x1000 |
是否由编译器产生 |
|
ACC_ENUM |
0x4000 |
是否enum |
l 之后是字段简单名称,即没有类型的字段名。
l 描述符是指字段的类型、方法的参数和返回值。规定对于基础类型以及代表返回值的void使用一个大写字符标识(boolean类型用Z),对象类型用L加对象的全限定名,对于数字则使用[加数组元素类型标识。所以字段int m 的描述符为I。对于方法的描述符
则规定按参数在前,返回类型在后的顺序,参数使用()包含起来。所以方法int indexOf(char[] source,String str)描述符为([CS])I。
l 属性表集合,由属性表计数值和属性表计数值个属性表组成,属性表记录内容为字段其他属性,比如final static int m=123,就会有一个ConstantValue的属性记录常量值。属性表内容见之后的属性表集合。
此外,需要注意字段表不会包含父类的字段,但有可能列车原本java代码中不存在的字段,比如内部类会添加访问外部类的实例字段。
2.9 methods方法表集合
方法表集合记录了类的方法集合,结构同字段表集合类似:Methods_count+methods。其中方法表的结构表示也相同,只是方法的access_flag访问标识如下表所示:
|
标志名称 |
标志值 |
含义 |
|
ACC_PUBLIC |
0x0001 |
是否public |
|
ACC_PRIVATE |
0x0002 |
是否private |
|
ACC_PROTECTED |
0x0004 |
是否protected |
|
ACC_STATIC |
0x0008 |
是否static |
|
ACC_FINAL |
0x0010 |
是否final |
|
ACC_SYNCHRONIZED |
0x0020 |
是否为synchronized |
|
ACC_BRIDGE |
0x0040 |
是否为编译器产生的桥接方法 |
|
ACC_VARARGS |
0x0080 |
是否接受不定参数 |
|
ACC_NATIVE |
0x0100 |
是否为native |
|
ACC_ABSTRACT |
0x0400 |
是否为abstract |
|
ACC_STRICTFP |
0x0800 |
是否为strictfp |
|
ACC_SYNTHETIC |
0x1000 |
是否由编译器产生 |
注意当子类没有重写父类方法时,不会出现父类的方法表。同时也有可能产生原java代码中没有的方法,如类初始化方法<clinit>,实例构造器<init>。
l Attributes属性表集合
class文件、字段表、方法表都可以携带自己的属性表集合,用于描述特定的场景。目前(jdk7)有21类属性表,每一类的属性值都完全自定义。具体属性表介绍见下一篇吧~~~
标签:宝贝 程序员 代码 width dia 接口索引 添加 对象 对象类型
原文地址:https://www.cnblogs.com/wssswjq/p/9788860.html