标签:组织结构 分离 信息 通用 抽象 lun 继承方式 程序设计 .com
在面向对象的程序设计语言中,多态是继数据抽象和继承之后的第三种基本特征。
多态分离了“做什么”和“怎么做”,让接口和实现分离开,改善了代码的可读性和组织结构,创建了可拓展的程序。
像第七章所说的那样,对象既可以作为他自己本身的类型使用,也可以作为他的基本类型使用,把这种对某个对象的引用视为对其基类类型的引用的做法称之为向上转型(因为在 UML 继承树的画法中,基类是在上方的)。
在发生向上转型的时候,我们可以很清楚的感受到,系统和编写者都在刻意的去忽视传递对象的类型-->导出类的接口向上转型到基类,可能会“缩小”接口,但是一定不会比基类的全部接口更窄。
这意味着在我们编写方法时,只接收基类作为参数,那么这样就可以不必为每一种导出类编写对应的接受参数方法。这就是多态的一种方式。
下面我们开始更进一步的讨论。
在向上转型的时候,方法接收基类的引用参数。那么编译器是如何得知引用是指向某一个特定导出类的呢。实际上编译器也无法得知,我们需要进一步了解绑定。
回到上面的问题,编译器是如何得知引用是指向某一个特定导出类的呢。我们之所以有疑问,就在于如果使用前期绑定,那么当编译器只有一个基类引用的时候,他是不应该知道应该调用哪个方法才对。但是在后期绑定中,编译器其实不知道,也不需要知道导出类对象的类型,方法调用机制能够找到正确的方法体并加以调用。
Java 中,除了 static 方法和 final 方法(private 方法属于 final 方法),其他所有方法,都是后期绑定-->就是说,通常情况下不需要去判定是否应该进行后期绑定(他会自动发生)。
final 方法其实是有效地关闭了动态绑定(后期绑定),或者是告诉了编译器不需要对一个方法做动态绑定。
建立在上面的基础,我们可以很容易的理解:
List<Integer> intList = new ArrayList();
intList.get(0);看起来 get() 方法调用的是 List 的引用,其实由于后期绑定(多态),调用的是 ArrayList.get() 方法。
编译器不需要获取任何特殊信息就能进行正确的调用,对方法的所有调用都是通过动态绑定进行的
在一个设计良好的 OOP 程序中,大多数或者所有方法,都会遵循特定方法的模型,而且只与基类接口通信,这样的程序就是可拓展的。-->可以从通用的基类继承出新的数据类型,操纵基类接口的方法也不需要任何改动就可以应用于新类。
多态最后的目的,就是希望能修改代码后,不会对程序中其他不受影响的部分受到破坏。
关于多态的缺陷:
基类的构造器总是在导出类的构造过程中被调用,而且按照继承层次逐渐向上链接-->每个基类的构造器都能得到调用。
这样做的意义在于:构造器能检查对象是否被正确构造,导出类只能访问自己的成员,基类的成员需要基类自己才能访问。只有在每个构造器都得到调用的情况下,才能保证无论在任何情况都能正确创造出完成的对象。
复杂对象调用构造器的顺序(不严谨的):
如果不清楚可以按照下面的例子查看。
class Meal {
Meal() { print("Meal()"); // 1}
}
class Bread {
Bread() { print("Bread()"); }
}
class Cheese {
Cheese() { print("Cheese()"); }
}
class Lettuce {
Lettuce() { print("Lettuce()"); }
}
class Lunch extends Meal {
Lunch() { print("Lunch()"); // 2}
}
class PortableLunch extends Lunch {
PortableLunch() { print("PortableLunch()"); // 3}
}
public class Sandwich extends PortableLunch {
private Bread b = new Bread(); // 4
private Cheese c = new Cheese(); // 5
private Lettuce l = new Lettuce(); // 6
public Sandwich() { print("Sandwich()"); }
public static void main(String[] args) {
new Sandwich(); // 7
}输出如下:
1 Meal()
2 Lunch()
3 PortableLunch()
4 Bread()
5 Cheese()
6 Lettuce()
7 Sandwich()通过组合和继承来创建新类,不用担心对象的清理问题。
不过加入面临这方面问题时(自定义对象清理)一定要注意,
当成员对象中存在于其他一个或者多个对象共享的情况,或许需要额外的引用计数来跟踪仍旧访问着的共享对象的对象数量。
可以使用由 tatic long 修饰一个静态成员,帮助跟踪所创建的类的实例的数量,还可以为 id 提供数值。
问题:如果在一个构造器内部调用正在构造的对象的某个动态绑定方法,那么对象无法知道自己是属于方法所在的那个类,还是属于那个类的导出类。
举例:
class Glyph {
void draw() { print("Glyph.draw()"); }
Glyph() {
print("Glyph() before draw()");
draw();
print("Glyph() after draw()");
}
}
class RoundGlyph extends Glyph {
private int radius = 1;
RoundGlyph(int r) {
radius = r;
print("RoundGlyph.RoundGlyph(), radius = " + radius);
}
void draw() {
print("RoundGlyph.draw(), radius = " + radius);
}
}
public class PolyConstructors {
public static void main(String[] args) {
new RoundGlyph(5);
}
}输出:
Glyph() before draw()
RoundGlyph.draw(), radius = 0
Glyph() after draw()
RoundGlyph.RoundGlyph(), radius = 5分析:
Glyph.draw() 方法被设计为将要被覆盖,这种覆盖在 RoundGlyph 中发生。但是 Glyph 中调用了这个方法,导致了对 RoundGlyph.draw() 的调用。但是这个调用是有问题的,RoundGlyph 根本没有开始初始化,所以 radius 的值是默认初始值0.
结论:
构造器初始化的实际过程是:
为了避免发生上述这类不可控的风险,在编写构造器时,要用尽可能简单的方法使对象进入正常状态;如果可以的话尽量避免其他方法。在构造器中唯一能够安全调用的方法,是基类的 final 方法(也适用于 private 方法),这些方法不能被覆盖,也就不会出现上面的蛋疼问题。
Java SE5中添加了协变返回类型,他表示在导出类中的被覆盖方法,可以返回基类方法的返回类型的某种导出类型。
就是说协变返回类型允许重写方法返回更具体的导出类型(如果基类方法返回的是基类的话)。
与继承相比,组合其实要更灵活,因为他可以动态选择类型(也就是选择了行为)。
而继承在编译时就要明确类型,不能再运行期间决定继承不同的对象。
一条通用的准则就是:用继承表达行为间的差异,并用字段表达状态上的变化。
如下图的继承方式,可以说是纯粹的继承层次关系-->只有在基类中已经建立的方法,才可以在导出类被覆盖。
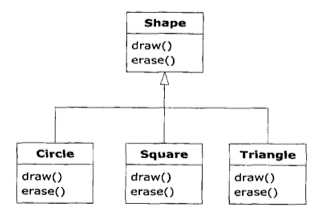
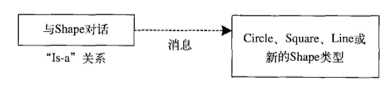
像这种纯继承模式,也被称作纯粹的“is-a”关系(是一个)-->这个类的接口已经确定了他应该是什么,导出类的接口绝对不会少于基类。
这种设计,保证基类可以介绍发送给导出类的任何消息(因为二者有着完全相同的接口)。只需要进行向上转型,就不需要知道正在处理的对象的确切类型。
但是实际使用中,我们更倾向于使用“is-like-a”关系(像一个),因为导出类就像一个基类-->有着相同的基本接口,还具有额外的其他方法。但是这么做的话,当使用向上转型时,拓展接口就不能被调用了。
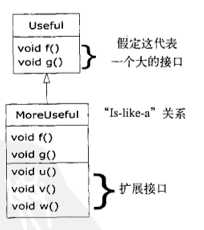
使用向上转型的时候会丢失具体的类型信息。
使用向下转型可以获取到具体的类型信息。不过,向下转型是不安全的,因为基类接口会小于等于导出类的接口。
为了确保安全,Java 中所有的转型都会得到检查。如果检查未通过,会返回 ClassCastException(类型转换异常)
这种在运行期间对类型进行检查的行为被称为“运行时类型识别”,简称 RTTI(Run-time type information)。
标签:组织结构 分离 信息 通用 抽象 lun 继承方式 程序设计 .com
原文地址:https://www.cnblogs.com/chentnt/p/9791888.html