标签:www digest requests 检查 fail sea 今日头条 美图 page
1.打开今日头条:https://www.toutiao.com
2.搜索街拍
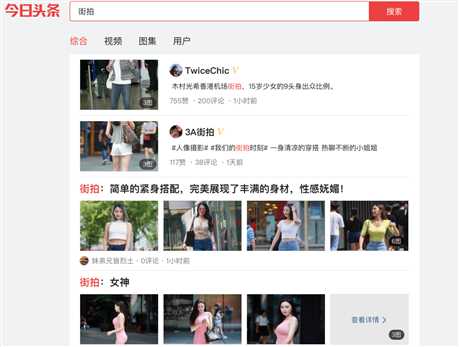
3.检查元素,查看请求发现在URL中每次只有offset发生改变,是一个get请求
1 import requests 2 from urllib.parse import urlencode 3 import os 4 from hashlib import md5 5 from multiprocessing.pool import Pool 6 7 def get_page(offset): 8 params = { 9 ‘offset‘: offset, 10 ‘format‘: ‘json‘, 11 ‘keyword‘: ‘街拍‘, 12 ‘autoload‘: ‘true‘, 13 ‘count‘: ‘20‘, 14 ‘cur_tab‘: ‘1‘, 15 ‘from‘: ‘search_tab‘ 16 } 17 url = ‘http://www.toutiao.com/search_content/?‘ + urlencode(params) 18 try: 19 response = requests.get(url) 20 if response.status_code == 200: 21 return response.json() 22 except requests.ConnectionError: 23 return None 24 25 def get_images(json): 26 if json.get(‘data‘): 27 data = json.get(‘data‘) 28 for item in data: 29 if item.get(‘cell_type‘) is not None: 30 continue 31 title = item.get(‘title‘) 32 images = item.get(‘image_list‘) 33 for image in images: 34 yield{ 35 ‘image‘: ‘http:‘ + image.get(‘url‘), 36 ‘title‘: title 37 } 38 39 def save_image(item): 40 image_path = ‘img‘ + os.path.sep + item.get(‘title‘) 41 if not os.path.exists(image_path): 42 os.mkdir(image_path) 43 try: 44 response = requests.get(item.get(‘image‘)) 45 if response.status_code == 200: 46 file_path = image_path + os.path.sep + ‘{file_name}.{file_suffix}‘.format( 47 file_name=md5(response.content).hexdigest(), 48 file_suffix=‘jpg‘ 49 ) 50 if not os.path.exists(file_path): 51 with open(file_path, ‘wb‘) as f: 52 f.write(response.content) 53 print(‘Downloaded image path is {0}‘.format(file_path)) 54 else: 55 print(‘Already Downloads‘, file_path) 56 except requests.ConnectionError: 57 print(‘Failed to save image !!!‘) 58 59 def main(offset): 60 json = get_page(offset) 61 for item in get_images(json): 62 print(item) 63 save_image(item) 64 65 GROUP_START = 0 66 GROUP_END = 9 67 68 if __name__ == ‘__main__‘: 69 pool = Pool() 70 groups = ([x * 20 for x in range(GROUP_START, GROUP_END+1)]) 71 pool.map(main, groups) 72 pool.close() 73 pool.join()
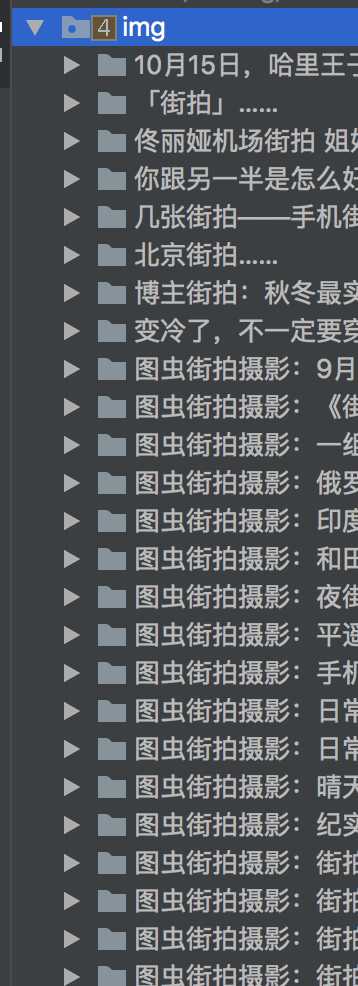
标签:www digest requests 检查 fail sea 今日头条 美图 page
原文地址:https://www.cnblogs.com/chengchengaqin/p/9792420.html