标签:rop 实现 spark sql class ast one sch 构建 code
1、介绍
spark SQL是构建在spark core模块上的四大模块之一,提供DataFrame等丰富的API,运行期间通过spark查询优化器翻译成物理执行计划,并行计算输出结果,底层计算原理用RDD计算实现。
2、standalone模式下的spark和hive集成
1、在 /soft/spark/conf 下创建 /soft/hive/conf/hive-site.xml 的软链接
ln -s /soft/hive/conf/hive-site.xml /soft/spark/conf/hive-site.xml
2、复制 /soft/hive/lib 下的mysql连接jar包到,spark的jars下
cp mysql-connector-java-5.1.44.jar /soft/spark/jars/
3、关闭 hive 的hive-site.xml 中的版本检查,否则会报版本不一致异常
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
4、启动spark shell
//s101上开启
spark-shell --master spark://s101:7077
3、在 idea 中配置 spark sql 环境
1、新建scala模块,添加maven支持
2、添加依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
</dependencies>
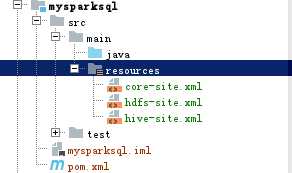
3、复制core-site.xml、hdfs-site.xml、hive-site.xml文件到模块的resources目录下
标签:rop 实现 spark sql class ast one sch 构建 code
原文地址:https://www.cnblogs.com/lybpy/p/9800503.html