标签:partition 结果 统一 适用于 weight 计数 pytho 双引号 返回
" 或者 一对单引号‘ 定义一个字符串
\" 或者 \‘ 做字符串的转义,但是在实际开发中:
",可以使用 ‘ 定义字符串‘,可以使用 " 定义字符串for循环遍历 字符串中每一个字符string = "Hello Python"
for c in string:
print(c)
| 方法 | 说明 |
|---|---|
| string.isspace() | 如果 string 中只包含空格,则返回 True |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True |
| string.isdecimal() | 如果 string 只包含数字则返回 True,全角数字 |
| string.isdigit() | 如果 string 只包含数字则返回 True,全角数字、⑴、\u00b2 |
| string.isnumeric() | 如果 string 只包含数字则返回 True,全角数字,汉字数字 |
| string.istitle() | 如果 string 是标题化的(每个单词的首字母大写)则返回 True |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True |
| 方法 | 说明 |
|---|---|
| string.startswith(str) | 检查字符串是否是以 str 开头,是则返回 True |
| string.endswith(str) | 检查字符串是否是以 str 结束,是则返回 True |
| string.find(str, start=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 -1 |
| string.rfind(str, start=0, end=len(string)) | 类似于 find(),不过是从右边开始查找 |
| string.index(str, start=0, end=len(string)) | 跟 find() 方法类似,不过如果 str 不在 string 会报错 |
| string.rindex(str, start=0, end=len(string)) | 类似于 index(),不过是从右边开始 |
| string.replace(old_str, new_str, num=string.count(old)) | 把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次 |
| 方法 | 说明 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.title() | 把字符串的每个单词首字母大写 |
| string.lower() | 转换 string 中所有大写字符为小写 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.swapcase() | 翻转 string 中的大小写 |
| 方法 | 说明 |
|---|---|
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| 方法 | 说明 |
|---|---|
| string.lstrip() | 截掉 string 左边(开始)的空白字符 |
| string.rstrip() | 截掉 string 右边(末尾)的空白字符 |
| string.strip() | 截掉 string 左右两边的空白字符 |
| 方法 | 说明 |
|---|---|
| string.partition(str) | 把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面) |
| string.rpartition(str) | 类似于 partition() 方法,不过是从右边开始查找 |
| string.split(str="", num) | 以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 ‘\r‘, ‘\t‘, ‘\n‘ 和空格 |
| string.splitlines() | 按照行(‘\r‘, ‘\n‘, ‘\r\n‘)分隔,返回一个包含各行作为元素的列表 |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
切片 方法适用于 字符串、列表、元组(字典是不能够切片的,字典没有索引,字典是无序的)
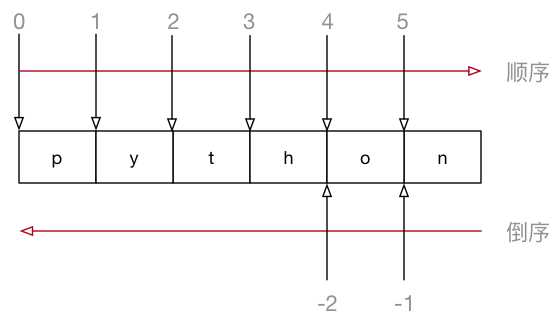
字符串[开始索引:结束索引:步长]
注意:
[开始索引, 结束索引) => 开始索引 >= 范围 < 结束索引
起始 位开始,到 结束位的前一位 结束(不包含结束位本身)1,如果连续切片,数字和冒号都可以省略num_str = "0123456789" # 1. 截取从 2 ~ 5 位置 的字符串 print(num_str[2:6]) # 2. 截取从 2 ~ `末尾` 的字符串 print(num_str[2:]) # 3. 截取从 `开始` ~ 5 位置 的字符串 print(num_str[:6]) # 4. 截取完整的字符串 print(num_str[:]) # 5. 从开始位置,每隔一个字符截取字符串 print(num_str[::2]) # 6. 从索引 1 开始,每隔一个取一个 print(num_str[1::2]) # 倒序切片 # -1 表示倒数第一个字符 print(num_str[-1]) # 7. 截取从 2 ~ `末尾 - 1` 的字符串 print(num_str[2:-1]) # 8. 截取字符串末尾两个字符 print(num_str[-2:]) # 9. 字符串的逆序(面试题) print(num_str[::-1])
| 函数 | 描述 | 备注 |
|---|---|---|
| len(item) | 计算容器中元素个数 | |
| del(item) | 删除变量 | del 有两种方式 |
| max(item) | 返回容器中元素最大值 | 如果是字典,只针对 key 比较 |
| min(item) | 返回容器中元素最小值 | 如果是字典,只针对 key 比较 |
| cmp(item1, item2) | 比较两个值,-1 小于/0 相等/1 大于 | Python 3.x 取消了 cmp 函数 |
注意(字符串 比较符合以下规则: "0" < "A" < "a")
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
| * | ["Hi!"] * 4 | [‘Hi!‘, ‘Hi!‘, ‘Hi!‘, ‘Hi!‘] | 重复 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
| > >= == < <= | (1, 2, 3) < (2, 2, 3) | True | 元素比较 | 字符串、列表、元组 |
注意
in 在对 字典 操作时,判断的是 字典的键in 和 not in 被称为 成员运算符for 变量 in 集合: 循环体代码 else: 没有通过 break 退出循环,循环结束后,会执行的代码
students = [ {"name": "阿土", "age": 20, "gender": True, "height": 1.7, "weight": 75.0}, {"name": "小美", "age": 19, "gender": False, "height": 1.6, "weight": 45.0}, ] find_name = "阿土" for stu_dict in students: print(stu_dict) # 判断当前遍历的字典中姓名是否为find_name if stu_dict["name"] == find_name: print("找到了") # 如果已经找到,直接退出循环,就不需要再对后续的数据进行比较 break else: print("没有找到") print("循环结束")
标签:partition 结果 统一 适用于 weight 计数 pytho 双引号 返回
原文地址:https://www.cnblogs.com/tangxlblog/p/9806893.html