标签:att ecs country attr dal 取值 port 学习 等等
【今日学习】
一、什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
二、为什么要序列化?
1:持久保存状态【硬盘存】
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,‘状态‘会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互【网络传】
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json模块【转化成str类型】(优先掌握)
序列化与反序列化一:
json.dumps json.loads 是一对
序列化:
dic={‘name‘:‘egon‘,‘age‘:18}
with open(‘db.json‘,‘w‘,encoding=‘utf-8‘) as f:
res = json.dumps(dic)
f.write(res)
print(res,type(res))
结果
{"name": "egon", "age": 18} <class ‘str‘>
#json格式全都是双引号,如果不是双引号,反序列化json就识别不了
#一个数据结构dump一次就行了,不要用‘a.txt ’去添加
反序列化:
with open(‘db.json‘,‘r‘,encoding=‘utf-8‘) as f:
data=f.read()
res=json.loads(data)
print(res)
结果
{‘name‘: ‘egon‘, ‘age‘: 18}
序列化与反序列化二:
简化版
json.dump json.load 是一对
序列化
import json
dic = {‘name‘: ‘egon‘, ‘age‘: 18}
with open(‘db1.json‘,‘w‘,encoding=‘utf-8‘) as f:
json.dump(dic,f)
反序列化
import json
dic = {‘name‘: ‘egon‘, ‘age‘: 18}
with open(‘db1.json‘,‘r‘,encoding=‘utf-8‘) as f:
print(json.load(f))
优点:数据跨平台较好
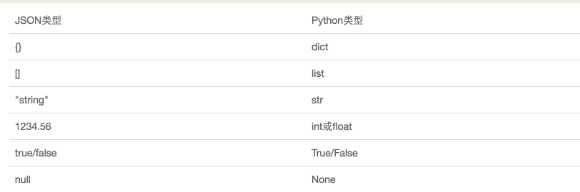
缺点:有些python数据类型不能识别,只能识别以下图片上数据类型
没有元组和集合
pickle模块(了解)【转化成bytes类型】
把所有的数据类型存成bytes类型,读也需要用bytes类型去读
优点:能识别所有python数据类型,能把所有数据类型序列化,用法与json类似
缺点:也是最致命缺点,只能识别python,跨平台较差
# 用户注册后得到的数据
name = "高跟"
password = "123"
height = 1.5
hobby = ["吃","喝","赌","飘",{1,2,3}]
# with open("userdb.txt","wt",encoding="utf-8") as f:
# text = "|".join([name,password,str(height)])
# f.write(text)
# pickle支持python中所有的数据类型
user = {"name":name,"password":password,"height":height,"hobby":hobby,"test":3}
# 序列化的过程
# with open("userdb.pkl","ab") as f:
# userbytes = pickle.dumps(user)
# f.write(userbytes)
# 反序列化过程
# with open("userdb.pkl","rb") as f:
# userbytes = f.read()
# user = pickle.loads(userbytes)
# print(user)
# print(type(user))
#
#dump 直接序列化到文件
# with open("userdb.pkl","ab") as f:
# pickle.dump(user,f)
# #load 从文件反序列化
with open("userdb.pkl","rb") as f:
user = pickle.load(f)
print(user)
shelve模块(了解)
也能像pickle序列化所有python数据类型,比pickle更方便
info1={‘name‘:‘egon‘,‘age‘:18}
info2={‘name‘:‘run‘,‘age‘:19}
import shelve
d=shelve.open(‘db.shv‘)
d[‘egon‘]=info1
d[‘run‘]=info2
d.close()
import shelve
d=shelve.open(‘db.shv‘)
# d[‘egon‘]
# d[‘run‘]
print(d[‘egon‘])
print(d[‘run‘])
import shelve
d=shelve.open(‘db.shv‘,writeback=True)
d[‘egon‘][‘age‘]=20
d[‘run‘][‘age‘]=18
print(d[‘egon‘])
print(d[‘run‘])
xml模块(了解)
古老的用法
也是将内存中数据储存起来或传输出去,将数据组织起来
# 查
# 三种查找节点的方式
# 第一种
# import xml.etree.ElementTree as ET
# tree=ET.parse(‘a.xml‘)
# root=tree.getroot()
# res=root.iter(‘year‘)
# # 会在整个树中查找,而且是查找所有
# print(res)
# for item in res:
# print(‘*********************‘)
# print(item.tag)
# print(item.attrib)
# print(item.text)
# 第二种:
# res=root.find(‘country‘)
# # 只能在当前元素下一级查找,并且找到一个就结束
# print(item.tag)
# print(item.attrib)
# print(item.text)
# 第三种
# cy=root.findall(‘country‘)只能在当前元素下一级查找
# # print(cy)
# for item in cy:
# print(item.tag)
# print(item.attrib)
# print(item.text)
# 改:
# import xml.etree.ElementTree as ET
# tree=ET.parse(‘a.xml‘)
# root=tree.getroot()
# for year in root.iter(‘year‘):
# year.text=str(int(year.text)+10)
# year.attrib={‘update‘:‘year‘}
# tree.write(‘a.xml‘)
# # 增
# import xml.etree.ElementTree as ET
# tree=ET.parse(‘a.xml‘)
# root=tree.getroot()
# for country in root.iter(‘country‘):
# year=country.find(‘year‘)
# if int(year.text)> 2020:
# print(country.attrib)
# ele=ET.Element(‘run‘)
# ele.attrib={‘nb‘:‘shuai‘}
# ele.text=‘ok‘
# country.append(ele)
# tree.write(‘a.xml‘)
# 删
# import xml.etree.ElementTree as ET
# tree=ET.parse(‘a.xml‘)
# root=tree.getroot()
# for country in root.iter(‘country‘):
# year=country.find(‘year‘)
# if int(year.text)> 2020:
# # print(country.attrib)
# country.remove(year)
# tree.write(‘a.xml‘)
configparser模块
import configparser
# 取值
# import configparser
# config=configparser.ConfigParser()
# config.read(‘my.ini‘)
# secs=config.sections()
# print(secs)
# print(config.options(‘run‘))
#
# print(config.get(‘run‘,‘age‘))
# print(config.getboolean(‘run‘,‘is_husband‘))
# print(config.getfloat(‘run‘,‘salary‘))
【今日领悟】
1.json是最常用的序列化与反序列化模块,其它类型的模块常用部分熟悉就行
2.需要在实际按例中去应用才能体会这几个模块的不同
标签:att ecs country attr dal 取值 port 学习 等等
原文地址:https://www.cnblogs.com/runjam/p/9807227.html