标签:函数 min 均值 ati arc 表示 缺点 目标 传递
聚类是机器学习中一种方法,常用用于处理数据分组的问题。给定一组数据,利用聚类算法将每一个数据点分批到一个特定的组。这就要求对于同一组的数据点,应该具有相同的性质(特征);对于不同组的数据点,在性质(特征)上应该有显著的区别。聚类算法数据无监督学习(unsupervised learning),常用于处理静态数据的分类问题。
K-Means算法是一种简单的迭代性聚类算法,采用距离作为相似性度量指标。从而将给定的数据集分为K个类,每个类的中心是由该类中所有点的均值得到,每个类均由聚类中心进行表示。
对给定的一个包含n个点的d维数据集X以及分类的个数K,选取欧式距离作为相似度指标。距离的目标是使各类的聚类平方和最小,即最小化度量函数即损失函数为:
\[J=\sum_{k=1}^{K}{\sum_{j=1}^{n}{(||x_i-u_k||^2)}}\]
K-Medians是一种和K-Means相似的迭代性聚类算法,只不过其在重新计算聚类中心时进行了改变,将均值计算改为中值计算。因此该方法相对于K-Means对异常值更鲁棒,但是其代价却是计算复杂度的增加,因为每个迭代过程中都需要对每类中的数据点进行排队找中值。
MeanShift是一个基于滑动窗口和质心的聚类算法,其目的是找出数据集中密度最大的区域。基于质心的意思是定位每一个组/类的质心,通过滑动窗口的方式不断更新质心的候选点。
对给定的d维空间\(R^d\)上的n个样本点,在空间中任选一点x,则MeanShift向量的表达形式为:\[M_h=\frac{1}{K}\sum_{{x_i}\in{S_h}}{(x_i-x)}\] \(S_k\)是满足以h为半径的高维球区域,满足一下关系的y的集合:\[S_k(x)=\{y:(y-x_i)^T(y-x_i)<h^2\}\]k表示在n个\(x_i\)点中,落在高维球区域\(S_k\)的内的点的个数。
直白来说,是以x为中心,画一个半径为h的高维球(当是二维空间时就是圆,当时三维空间时就是球,当是多维空间时就是多维球),假设落在高维球内的点有k个,则分别将圆心(x)和其他点进行连接,构成k个向量,然后再将k个向量进行相加,最后得到的向量和就是MeanShift。
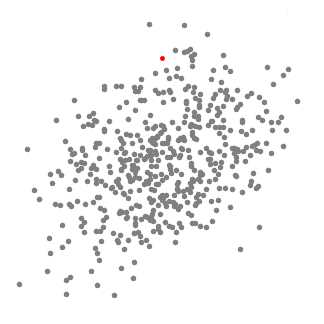

DBSCAN(具有噪声的密度聚类算法)是一种特别的聚类算法,相比于只用于凸优化样本集中的K-Means算法,DBSCAN既可以用于凸优化样本集也可以用于非凸优化样本集。DBCAN是一种基于密度的聚类算法,该算法假设样本的类别可以通过样本分布的紧密程度进行区分。同一类别的样本,他们之间是紧密相连的;不同类别的样本则分布的相对较远。通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。
DBSCAN是基于一组邻域来描述样本集的紧密程度,参数\((\varepsilon, minPts)\)来描述邻域的样本分布密度,其中\(\varepsilon\)表示某一样本的邻域距离的阈值,minPts表示某一样本的距离为\(\varepsilon\)的邻域中样本个数的阈值。
假设样本集是\(D=(x_1,x_2,,,x_m)\),则DBSCAN具体的密度描述定义如下:
密度相连:对于\(x_i\)和\(x_j\),存在一个核心对象\(x_k\),如果\(x_i\)由\(x_k\)密度可达且\(x_j\)由\(x_k\)密度可达,则称\(x_i\)和\(x_j\)密度相连;
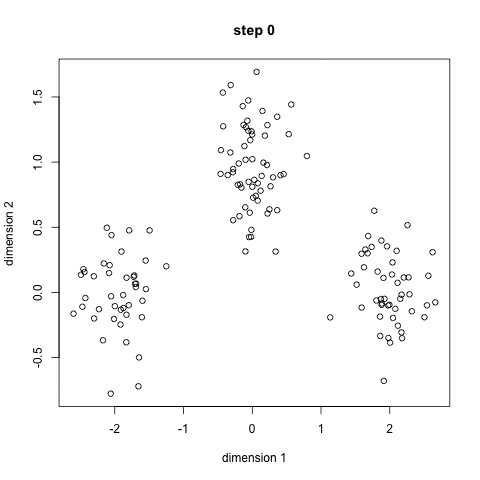
K-Means主要的缺点是其使用均值作为聚类中心,在某些聚类情况下无法有效区分聚类中心。例如下图的左侧图像,我们肉眼可以很容易的看出整个图像分为两类:左侧绿色点,右侧蓝色点。然而在使用K-Means算法时,却无法有效区分分聚类中心,因为采用均值计算聚类中心,则聚类中心大约都处在圆心部位。

Gaussian Mixture Models(GMMs)相比于K-Means具有更高的灵活性,使用GMMS的前提是假设数据点是服从高斯分布的。因此我们使用两个参数来对聚类进行描述:均值和标准偏差。例如在二位空间中我们可以表示任何形式的椭圆,因为我们具有中心点和x,y轴的标准差。
为找到每个类的高斯参数,我们采用期望最大策略(Expectation-Maximization,EM)。GMMs聚类的步骤如下:
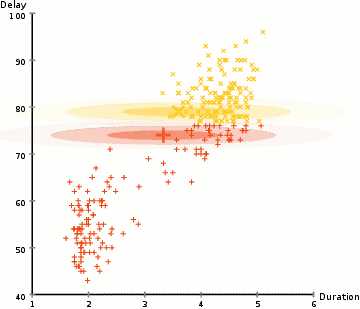
GMMs具有两个关键的优势:1、对于cluster covariance(聚类协方差)情况下,相比于K-Means更为灵活。因为通过使用标准偏差参数可以表示任何形式的椭圆,而K-Means只能表示圆,当然K-Means可以看做是GMMs的一种特例,每个群在各个维度上的协方差均为0。2、因为GMMs采用概率的方式,因此可解决一个点属于多簇的情况。例如一个点在两个簇的交叉点上,可以描述为属于簇1的概率是X,属于簇2的概率是Y。
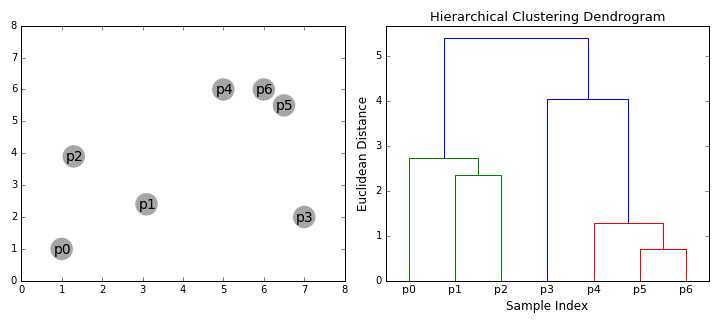
层次聚类根据聚类的方式分为两类:自上而下和自下而上。自下而上的聚类算法,起初假设每个样本都是一个单独的类别,然后相继的合并类别,直到最后只有一个类别。最终将得到一个类似于树的结构,树的根是一个类别,其包含所有的样本点,而叶子则是只有一个样本的集群。
聚类过程如下:
标签:函数 min 均值 ati arc 表示 缺点 目标 传递
原文地址:https://www.cnblogs.com/WingPig/p/9767527.html