标签:img 文件 返回 inf each trim 需要 运行 random
1.理解
问题定义可以简化如下:在不知道文件总行数的情况下,如何从文件中随机的抽取一行?
首先想到的是我们做过类似的题目吗?当然,在知道文件行数的情况下,我们可以很容易的用C运行库的rand函数随机的获得一个行数,从而随机的取出一行,但是,当前的情况是不知道行数,这样如何求呢?我们需要一个概念来帮助我们做出猜想,来使得对每一行取出的概率相等,也即随机。这个概念即蓄水池抽样(Reservoir Sampling)。
水塘抽样算法(Reservoir Sampling)思想:
在序列流中取一个数,如何确保随机性,即取出某个数据的概率为:1/(已读取数据个数)
假设已经读取n个数,现在保留的数是Ax,取到Ax的概率为(1/n)。
对于第n+1个数An+1,以1/(n+1)的概率取An+1,否则仍然取Ax。依次类推,可以保证取到数据的随机性。
数学归纳法证明如下:
当n=1时,显然,取A1。取A1的概率为1/1。
假设当n=k时,取到的数据Ax。取Ax的概率为1/k。
当n=k+1时,以1/(k+1)的概率取An+1,否则仍然取Ax。
(1)如果取Ak+1,则概率为1/(k+1);
(2)如果仍然取Ax,则概率为(1/k)*(k/(k+1))=1/(k+1)
所以,对于之后的第n+1个数An+1,以1/(n+1)的概率取An+1,否则仍然取Ax。依次类推,可以保证取到数据的随机性。
在序列流中取k个数,如何确保随机性,即取出某个数据的概率为:k/(已读取数据个数)
建立一个数组,将序列流里的前k个数,保存在数组中。(也就是所谓的”蓄水池”)
对于第n个数An,以k/n的概率取An并以1/k的概率随机替换“蓄水池”中的某个元素;否则“蓄水池”数组不变。依次类推,可以保证取到数据的随机性。
数学归纳法证明如下:
当n=k是,显然“蓄水池”中任何一个数都满足,保留这个数的概率为k/k。
假设当n=m(m>k)时,“蓄水池”中任何一个数都满足,保留这个数的概率为k/m。
当n=m+1时,以k/(m+1)的概率取An,并以1/k的概率,随机替换“蓄水池”中的某个元素,否则“蓄水池”数组不变。则数组中保留下来的数的概率为:
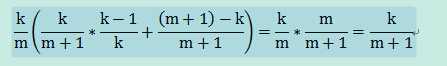
所以,对于第n个数An,以k/n的概率取An并以1/k的概率随机替换“蓄水池”中的某个元素;否则“蓄水池”数组不变。依次类推,可以保证取到数据的随机性。
Spark中的水塘抽样算法(Reservoir Sampling)
spark的Partitioner子类RangePartitioner中有用到Reservoir Sampling抽样算法(org.apache.spark.RangePartitioner#sketch).
spark的util中有reservoirSampleAndCount方法(org.apache.spark.util.random.SamplingUtils#reservoirSampleAndCount)
源码为:
/**
* Reservoir sampling implementation that also returns the input size.
*
* @param input input size
* @param k reservoir size
* @param seed random seed
* @return (samples, input size)
*/
def reservoirSampleAndCount[T: ClassTag](
input: Iterator[T],
k: Int,
seed: Long = Random.nextLong())
: (Array[T], Int) = {
val reservoir = new Array[T](k)
// Put the first k elements in the reservoir.
var i = 0
while (i < k && input.hasNext) {
val item = input.next()
reservoir(i) = item
i += 1
}
// If we have consumed all the elements, return them. Otherwise do the replacement.
if (i < k) {
// If input size < k, trim the array to return only an array of input size.
val trimReservoir = new Array[T](i)
System.arraycopy(reservoir, 0, trimReservoir, 0, i)
(trimReservoir, i)
} else {
// If input size > k, continue the sampling process.
val rand = new XORShiftRandom(seed)
while (input.hasNext) {
val item = input.next()
val replacementIndex = rand.nextInt(i)
if (replacementIndex < k) {
reservoir(replacementIndex) = item
}
i += 1
}
(reservoir, i)
}
}
代码实现思路比较简单,新建一个k大小的数组reservoir,如果元数据中数据少于k,直接返回原数据数组和原数据个数。如果大于,则对接下来的元素进行比较,随机生成一个数i,如果这个数小于k,则替换数组reservoir中第i个数,直至没有元素,则返回reservoir的copy数组。
2.代码:
测试org.apache.spark.util.random.SamplingUtils$#reservoirSampleAndCount方法:
package org.apache.spark.sourceCode.partitionerLearning
import org.apache.spark.util.SparkLearningFunSuite
import org.apache.spark.util.random.SamplingUtils
import scala.util.Random
class reservoirSampleAndCountSuite extends SparkLearningFunSuite {
test("reservoirSampleAndCount") {
val input = Seq.fill(100)(Random.nextInt())
val (sample1, count1) = SamplingUtils.reservoirSampleAndCount(input.iterator, 150)
assert(count1 === 100)
assert(input === sample1.toSeq)
// input size == k
val (sample2, count2) = SamplingUtils.reservoirSampleAndCount(input.iterator, 100)
assert(count2 === 100)
assert(input === sample2.toSeq)
// input size > k
val (sample3, count3) = SamplingUtils.reservoirSampleAndCount(input.iterator, 10)
assert(count3 === 100)
assert(sample3.length === 10)
println(input)
sample3.foreach{each=>print(each+" ")}
}
}
List(1287104639, 547232730, -595310393, -1264894486, 427750044, -776002403, 32230947, -1390386390, 484259687, 774711013, -1989325813, -957970416, 945685455, -1322730587, -1919655222, 1642426087, -489524599, -1070401860, -1454008456, -1882431453, -1843815884, -1987533758, -854529853, 879991257, -864077378, 478381860, 111307761, 1504756336, -1892792571, -1413976846, -848218587, -101494119, 1592476609, 247606007, 1269634528, 568928892, 488930464, -2145986422, 1643110602, 280675891, -878405966, 1799740067, 981424562, -1552824965, -1760162041, -288189264, -373755181, -2112636248, -2108911467, -1815555415, 302051417, 254178521, -1137490849, 426066017, -819810525, 1408383341, 1183678420, 234717727, 1470632905, 271163573, -22448780, 486064749, 378168799, -1444541974, 419089337, 1700972847, 1291787131, 644012641, -1618133452, 313585654, 658987252, 869334013, -811750155, -1561229418, 814819564, -197177628, 1051344432, 1746109173, 358985873, -265551244, 1362130460, -1635943643, 168813599, -669120136, -1084593890, -150445899, 387678120, 1994726806, 71986215, 1323527748, 700729367, 219285004, -1513691303, -97767338, 2099894386, -652208741, 704524016, 123647594, -1281589410, -1713105982)
-197177628 -22448780 478381860 -1137490849 219285004 168813599 1269634528 -1454008456 658987252 378168799
Spark MLlib之水塘抽样算法(Reservoir Sampling)
标签:img 文件 返回 inf each trim 需要 运行 random
原文地址:https://www.cnblogs.com/itboys/p/9825169.html