标签:获取 ret roman 转换 tin position put 注释 跳过
解析过程分为词法解析和语法解析。 解析引擎在 parsing 包下,包含两大组件:
词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树。例如:
SELECT id, name FROM t_user WHERE status = ‘ACTIVE‘ AND age > 18
解析成的抽象语法树如:
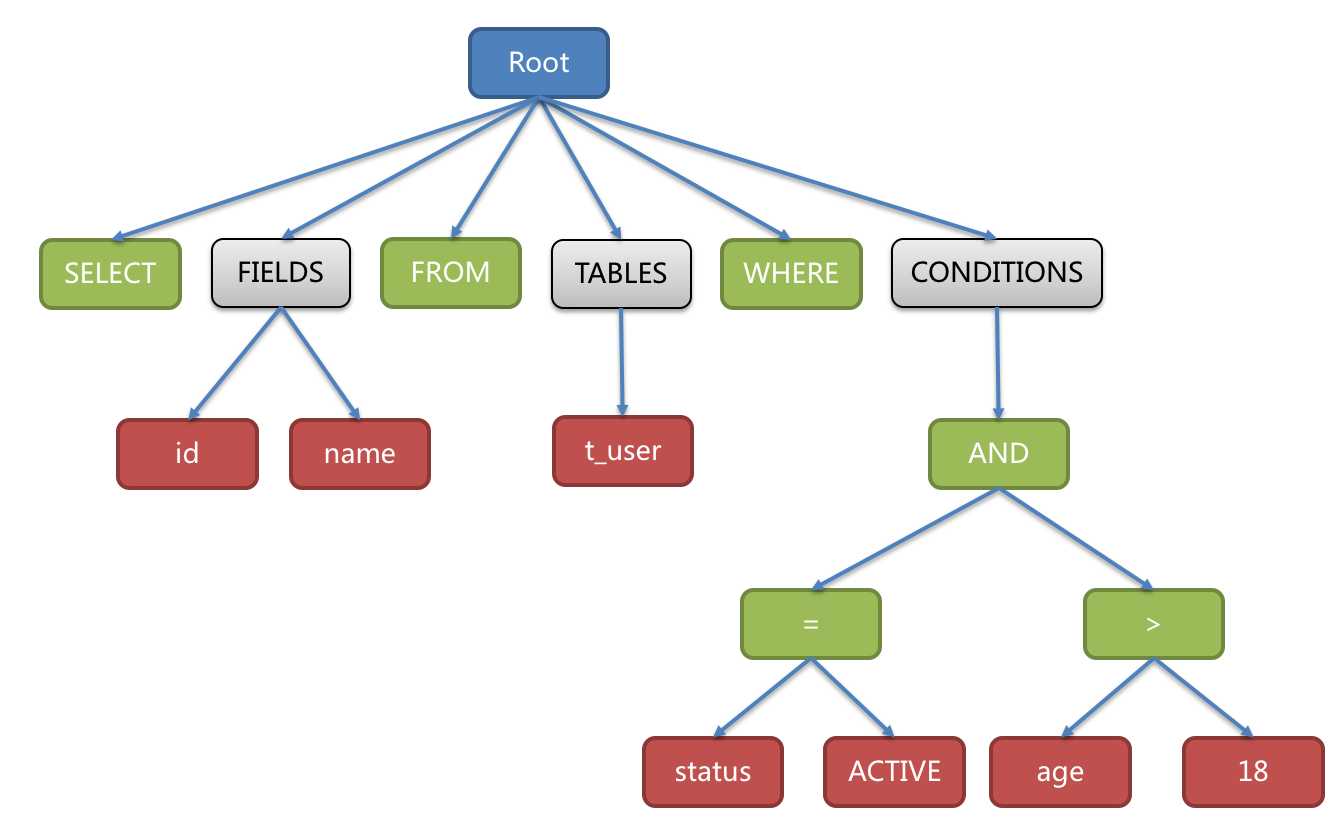
两者都是解析器,区别在于 Lexer 只做词法的解析,不关注上下文,将字符串拆解成 N 个分词。而 Parser 在 Lexer 的基础上,进一步理解 SQL表示的行为 。
作用:顺序解析 SQL,将sql字符串分解成 N 个分词(token)。那么每个分词该如何表示呢?
token用于描述当前分解出的词法,包含3个属性:
TokenType 用于描述当前token的类型,分成 4 大类:
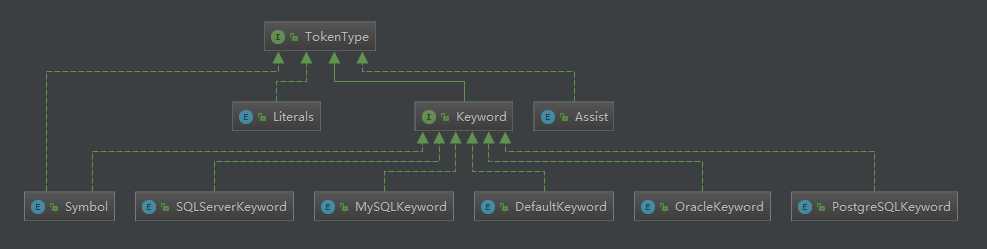
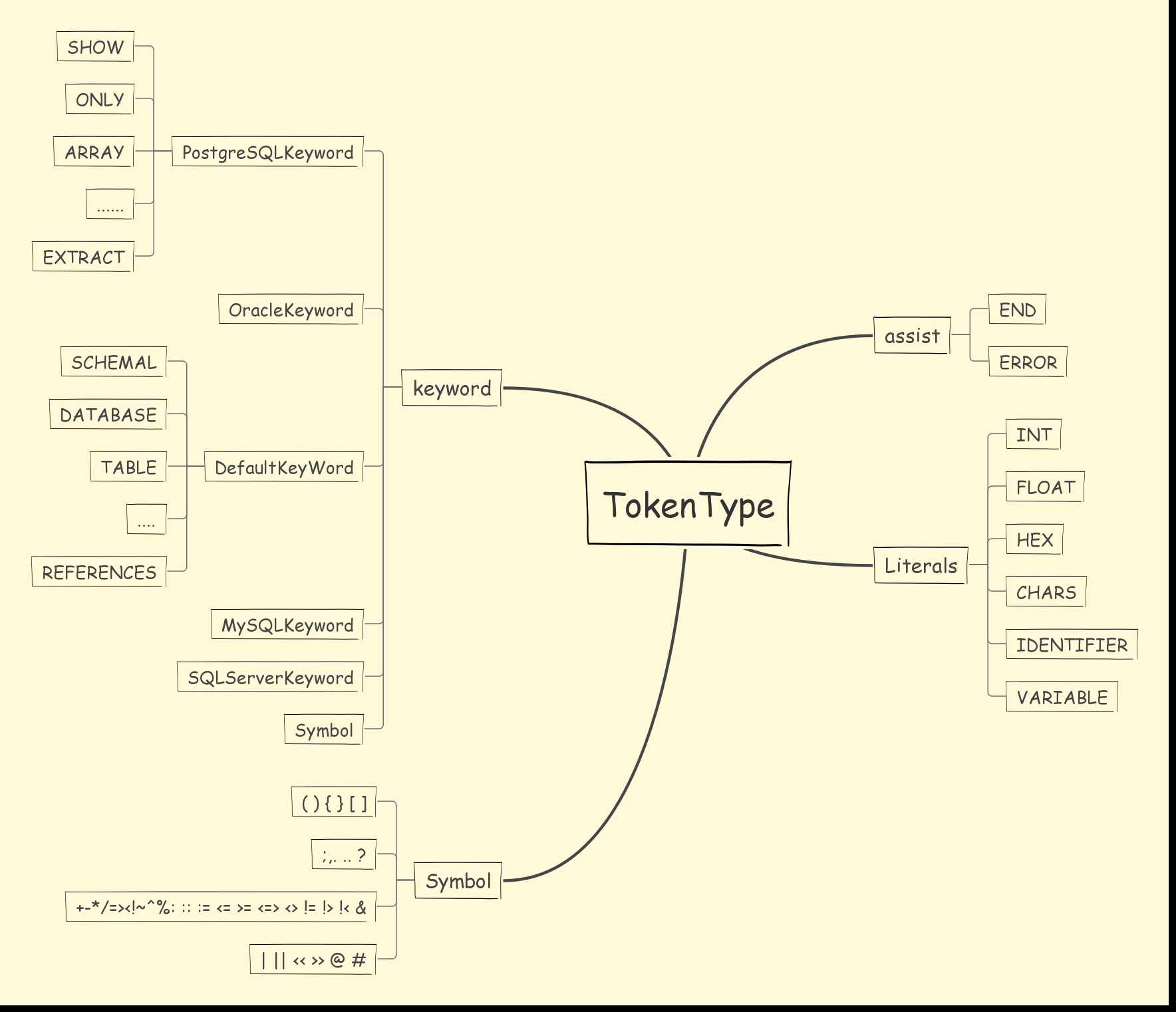
由于不同数据库遵守的 SQL 规范有所不同,所以不同的数据库对应存在不同的 Lexer,维护了对应的dictionary。Lexer内部根据相应数据库的dictionary与sql语句生成一个Tokenizer分词器进行分词。
public final class Tokenizer { //输入 private final String input; //字典 private final Dictionary dictionary; //偏移量 private final int offset; }
分词器具体的api如下:
| 方法名 | 说明 |
|---|---|
| int skipWhitespace() | 跳过所有的空格 返回最后的偏移量 |
| int skipComment() | 跳过注释,并返回最终的偏移量 |
| Token scanVariable() | 获取变量,返回分词Token |
| Token scanIdentifier() | 返回关键词分词 |
| Token scanHexDecimal() | 扫描16进制返回分词 |
| Token scanNumber() | 返回数字分词 |
| Token scanChars() | 返回字符串分词 |
| Token scanSymbol() | 返回词法符号标记分词 |
核心代码如下:
// Lexer.java public final void nextToken() { skipIgnoredToken(); if (isVariableBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanVariable(); } else if (isNCharBegin()) { currentToken = new Tokenizer(input, dictionary, ++offset).scanChars(); } else if (isIdentifierBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanIdentifier(); } else if (isHexDecimalBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanHexDecimal(); } else if (isNumberBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanNumber(); } else if (isSymbolBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanSymbol(); } else if (isCharsBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanChars(); } else if (isEnd()) { currentToken = new Token(Assist.END, "", offset); } else { throw new SQLParsingException(this, Assist.ERROR); } offset = currentToken.getEndPosition(); System.out.println(currentToken.getLiterals() + " | " + currentToken.getType() + " | " + currentToken.getEndPosition() + " |"); }
类继承图:
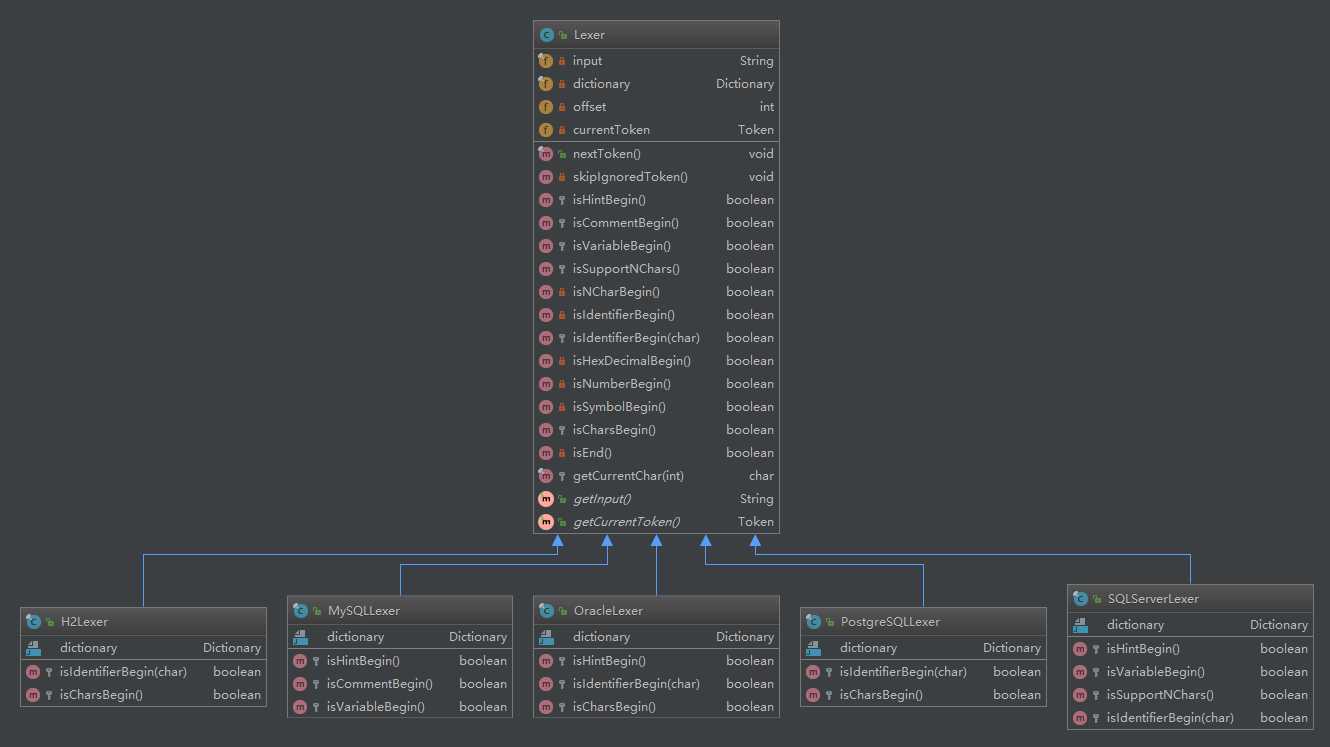
总结:Lexer通过 nextToken() 方法,不断解析出当前 Token。Lexer的nextToken()方法里,使用 skipIgnoredToken() 方法跳过忽略的 Token,通过 isXxx() 方法判断好下一个 Token 的类型后,交给 Tokenizer 进行分词并返回 Token。
语法解析器的作用是根据不同类型的sql语句在词法解析器的基础上,由不同类型的语法解析器解析成SQLStatement,具体语法解析类结构如图:
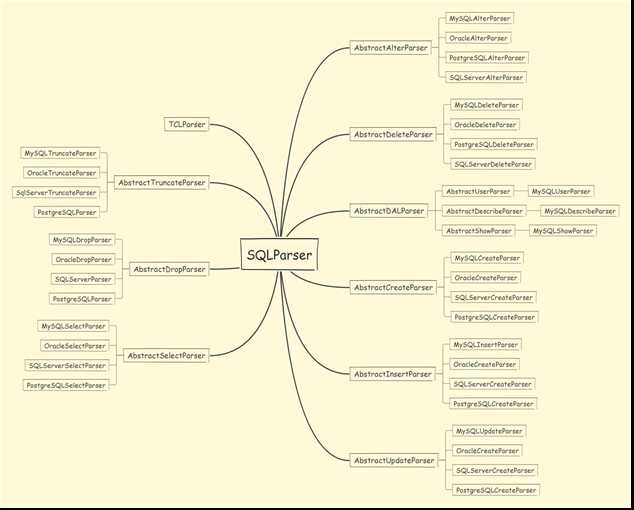
可以看到,不同类型的sql,不同厂商的数据库,存在不同的处理解析器去解析,解析完成之后,会将SQL解析成SQLStatement。
SQLParsingEngine,SQL 解析引擎。其 parse() 方法作为 SQL 解析入口,本身不带复杂逻辑,通过调用对应的 SQLParser 进行 SQL 解析,返回SQLStatement。
@RequiredArgsConstructor public final class SQLParsingEngine { private final DatabaseType dbType; private final String sql; private final ShardingRule shardingRule; private final ShardingTableMetaData shardingTableMetaData; /** * Parse SQL. * * @param useCache use cache or not * @return parsed SQL statement */ public SQLStatement parse(final boolean useCache) { Optional<SQLStatement> cachedSQLStatement = getSQLStatementFromCache(useCache); if (cachedSQLStatement.isPresent()) { return cachedSQLStatement.get(); } LexerEngine lexerEngine = LexerEngineFactory.newInstance(dbType, sql); lexerEngine.nextToken(); SQLStatement result = SQLParserFactory.newInstance(dbType, lexerEngine.getCurrentToken().getType(), shardingRule, lexerEngine, shardingTableMetaData).parse(); if (useCache) { ParsingResultCache.getInstance().put(sql, result); } return result; } }
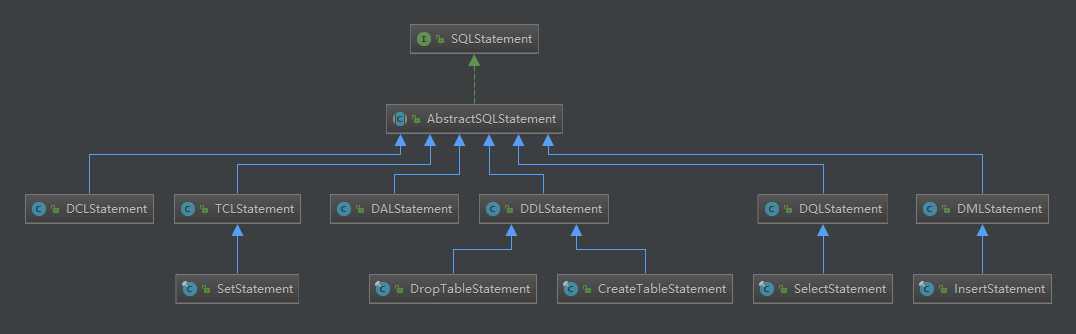
SQLStatement对象是个超类,具体实现类有很多。按照不同的语句,解析成不同的SQLStatement。
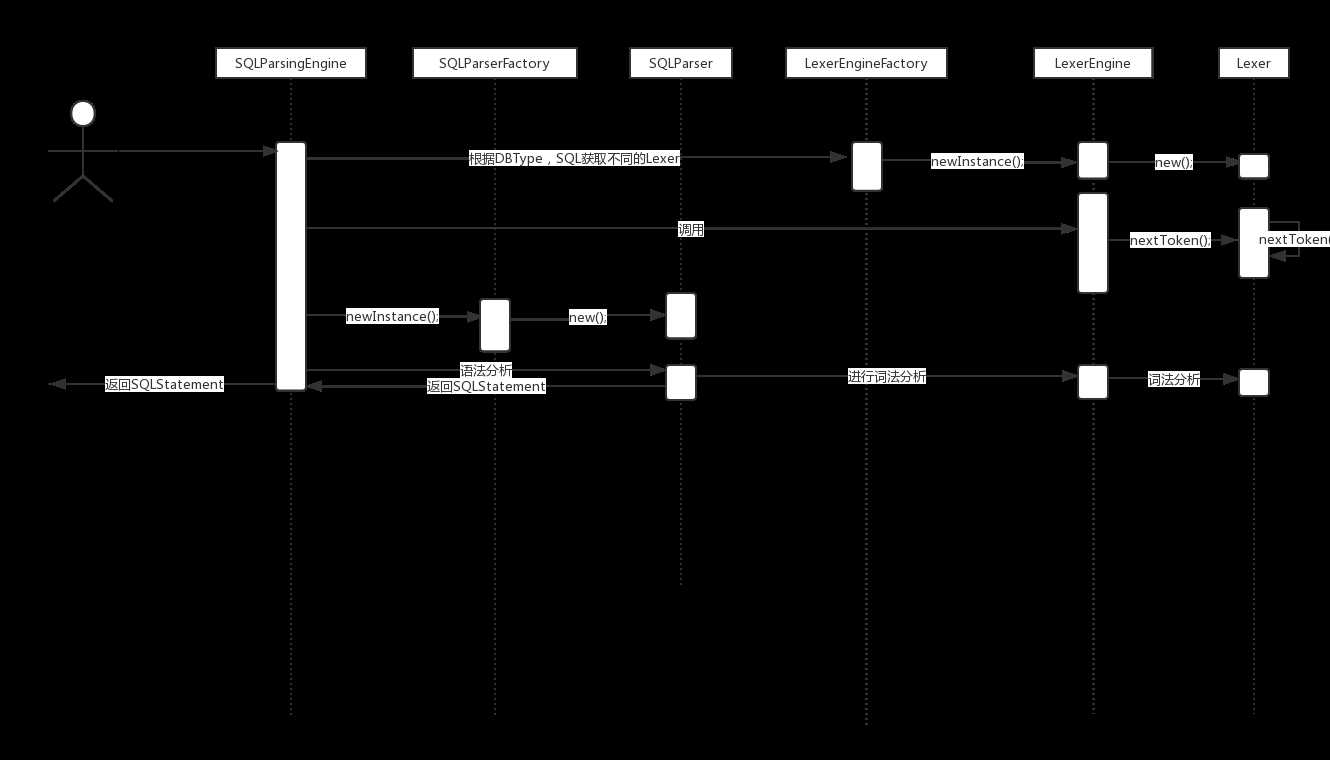
sql语句解析的过程如下图:
参考:
http://www.iocoder.cn/categories/Sharding-JDBC/
https://www.jianshu.com/u/c6408f5e4b0e
标签:获取 ret roman 转换 tin position put 注释 跳过
原文地址:https://www.cnblogs.com/tzc1024/p/9825223.html