标签:for 不容易 loss 关系 embedding 三元 semi 基于 abs
Triplet Loss
在人脸识别中,Triplet loss被用来进行人脸嵌入的训练。如果你对triplet loss很陌生,可以看一下吴恩达关于这一块的课程。Triplet loss实现起来并不容易,特别是想要将它加到tensorflow的计算图中。
通过本文,你讲学到如何定义triplet loss,和进行triplets采样的几种策略。然后我将解释如何在TensorFlow中使用在线triplets挖掘来实现Triplet loss。
谷歌的论文FaceNet: A Unified Embedding for Face Recognition and Clustering最早将triplet loss应用到人脸识别中。他们提出了一种实现人脸嵌入和在线triplet挖掘的方法,这部分内容我们将在后面章节介绍。
在监督学习中,我们通常都有一个有限大小的样本类别集合,因此可以使用softmax和交叉熵来训练网络。但是,有些情况下,我们的样本类别集合很大,比如在人脸识别中,标签集很大,而我们的任务仅仅是判断两个未见过的人脸是否来自同一个人。
Triplet loss就是专为上述任务设计的。它可以帮我们学习一种人脸嵌入,使得同一个人的人脸在嵌入空间中尽量接近,不同人的人脸在嵌入空间中尽量远离。
Triplet loss的目标:
值得注意的一点是,如果只遵循以上两点,最后嵌入空间中相同类别的样本可能collapse到一个很小的圈子里,即同一类别的样本簇中样本间的距离很小,不同类别的样本簇之间也会偏小。因此,我们加入间隔(margin)的概念——跟SVM中的间隔意思差不多。只要不同类别样本簇简单距离大于这个间隔就阔以了。
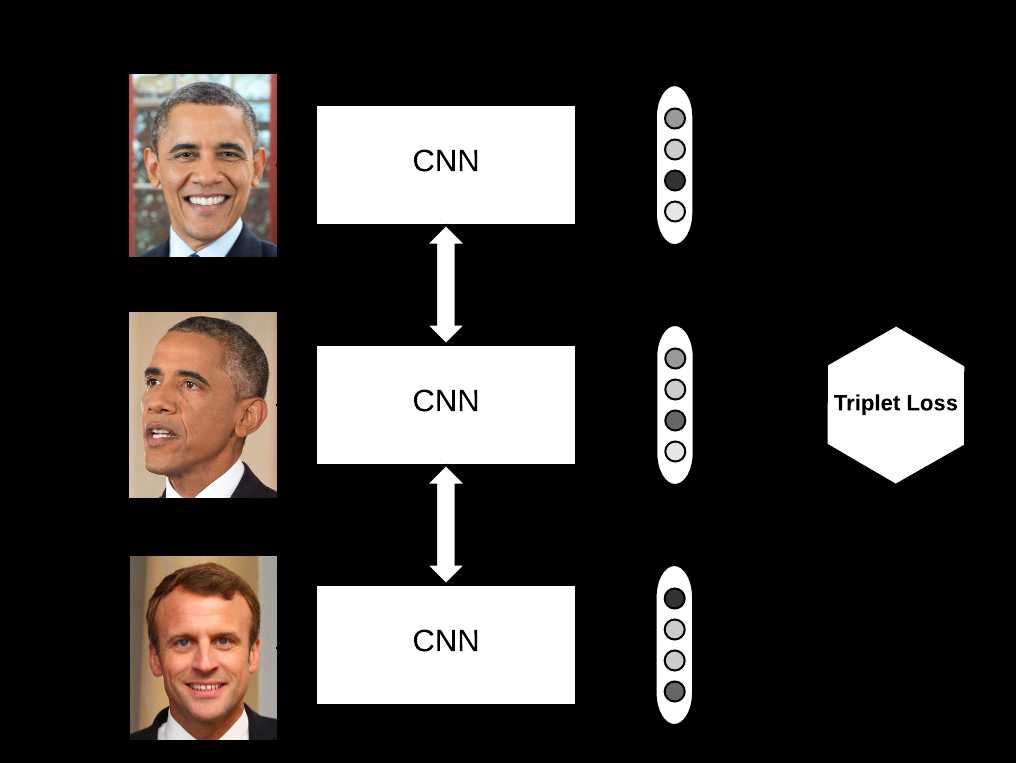
Triplet可以理解为一个三元组,它由三部分组成:
我们要求,在嵌入空间dd中,三元组(a,p,n)(a,p,n)满足一下关系:
L=max(d(a,p)?d(a,n)+margin,0)L=max(d(a,p)?d(a,n)+margin,0)
最小化该LL,则d(a,p)→0, d(a,n)>margind(a,p)→0, d(a,n)>margin。
基于前文定义的Triplet loss,可以将三元组分为一下三个类别:
图中,a为原点位置,p为同类样本例子,不同颜色表示的区域表示异类样本分布于三元组类别的关系
显然,中间的Semi-hard negatives样本对我们网络模型的训练至关重要。
在网络训练中,应尽可能使用Semi-hard negatives样本,这一节将介绍如何选择这些样本。
可以在每轮迭代之前离线的生成Triplet。也就是先对所有的训练集计算嵌入表达,然后只选择semi-hard triplets并以此为输入训练一次网络。具体而言:
离线挖掘方式几乎与传统的深度学习一样,操作简单,但是效率较低(毕竟每次迭代之前都遍历了整个训练集来找到semi-hard样本)。
标签:for 不容易 loss 关系 embedding 三元 semi 基于 abs
原文地址:https://www.cnblogs.com/luofeel/p/9842361.html