标签:hellip seq bar dash 执行 excel格式 先后 数据导入 双引号
这里介绍2种把excel数据导入oracle数据库的方法。
1. 在excel中生成sql语句。
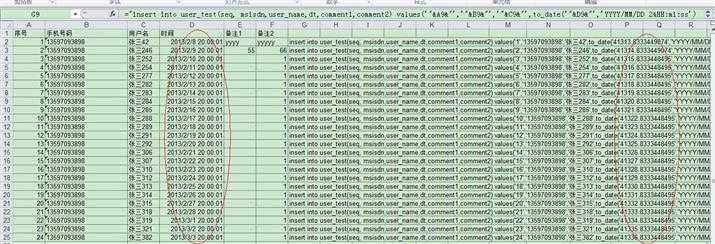
1)在数据列的右侧,第一行的任何位置输入="insert into table(xx,yyy..) values(‘"&A2&"‘, ‘"&B2&"‘….);"
注意:
2)写完一行后往下拖,自动生成其他行的sql。
3)把这些sql copy到pl/sql dev工具中执行。
这种方法适合数据量不太大,且只含有varchar(或者说转入数据库中都为varchar类型字段)这种简单的数据类型的数据。对于含有日期类型的要注意,如果excel格式中有日期类型的,使用这种方法引用出来的值是个浮点数。需要首先把日期格式转换成文本格式。再写sql语句,它才能引用正确的日期格式的值。insert into user_test(seq, msisdn,user_name,dt,comment1,comment2) values(‘1‘,‘13597093898‘,‘张三42‘,to_date(‘2013/2/8 20:00:01‘,‘yyyy/mm/dd HH24:mi:ss‘),‘yyyy‘,‘yyyyy‘);
但存在以下情况不建议用这种方法了。
1. 对于数据量很大,几十万,上百万的数据。
2. 如果数据库表存在由序列生成的列。
3. 存在日期格式列的excel。——我没有找到很方便的直接把日期格式转为文本格式的方法(如直接转换成文本,它会显示成浮点),因此存在日期格式的excel列不建议采用这种方法。
当然第二点,还是可以通过其他方法解决的,就是写触发器。
在写insert语句插入的列不包含序列的列,写触发器,当表进行insert之前生成序列号插入。
假设数据库表如下

create table user_test ( seq number(10) primary key, msisdn varchar2(11) not null, user_name varchar2(50) not null, dt date, comment1 varchar2(50), comment2 varchar2(50) ); create sequence user_test_seq INCREMENT BY 1 -- 每次加几个 START WITH 1 -- 从1开始计数 insert变成这样写: insert into user_test(msisdn,user_name,dt,comment1,comment2) values(‘13597093898‘,‘张三42‘,to_date(‘2013/2/8 20:00:01‘,‘yyyy/mm/dd HH24:mi:ss‘),‘yyyy‘,‘yyyyy‘);
触发器:
CREATE OR REPLACE TRIGGER my_trigger BEFORE INSERT ON user_test FOR EACH ROW WHEN (new.seq is null) BEGIN SELECT user_test_seq.nextval INTO :new.seq FROM DUAL; END my_trigger;
其中:new.seq是指新列中的seq字段。
为更好的解决这些问题, 下面介绍第二种方法。
2. 写loader
1) 把excel中的数据另存为.csv文件,字段逗号分隔。假设保存为gov.csv
2 )写ctl文件:
gov.ctl
LOAD DATA INFILE ‘gov.csv‘ APPEND INTO TABLE user_test FIELDS TERMINATED BY ‘,‘ trailing nullcols //下面列先后顺序同文件中数据字段的顺序。 ( seq "user_test_seq.nextval", MSISDN, user_name, DT date "yyyy/mm/dd HH24:mi", comment1 , comment2 )
3) 写par文件, 假设名为test.par,其内容为:
userid=用户/密码 control=./gov.ctl log=./t.log bad=./t.bad skip=1 //跳过第一行标题 rows=10000 //每n行commit一次
4)sqlldr parfile=test.par
在我的服务器上,导入百多万的数据应该是一分钟之内的事。
标签:hellip seq bar dash 执行 excel格式 先后 数据导入 双引号
原文地址:https://www.cnblogs.com/ExMan/p/9842655.html