标签:私有 方式 只读 png 暴力 商务 容器 war 分享图片
摘要: 云计算带来了业务弹性上的极大优势,阿里云数据库高级产品专家时慢从应用架构的变迁,客户实战案例,业务分析等方面详细介绍POLARDB,及如何利用POLARDB设计互联网创新型应用的数据库架构。云计算带来了业务弹性上的极大优势,阿里云数据库高级产品专家时慢从应用架构的变迁,客户实战案例,业务分析等方面详细介绍POLARDB,及如何利用POLARDB设计互联网创新型应用的数据库架构。

应用架构的变迁——为什么我们需要超级MySQL?
POLARDB跟MySQL是100%兼容的,有超越MySQL很多倍的性能,以及单实例最大100TB的超大存储空间,可以理解为阿里自研的超级MySQL。那么我们为什么要打造这样一款超级MySQL呢?我们理解这是应用架构进行互联网分布式变迁的必然结果。首先我们需要回顾一下应用架构的变迁的历史,从最早的CS架构到BS架构,从J2EE到Spring/Struts/Hibernate,再到现在的微服务架构,经历了很多代的架构转型。从传统应用的业务架构到互联网分布式的应用架构,在方方面面都发生了变化。从资源层,到数据层,中间件,应用的发布封装以及应用的框架,开发运维的角度都在发生了互联网分布式变迁。
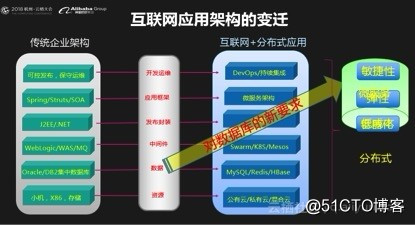
资源层:传统应用会使用X86 ,小机以及存储设备;互联网分布式应用在使用公有云,私有云,混合云等。
数据层:传统应用会使用Oracle,DB2等集中化的商业数据库,互联网应用使用的是MySQL,Redis,HBase这样的分布式数据库,他们不需要集中化的存储设备。
中间件:传统应用会使用WebLogic,WebSphere等,互联网应用在向微服务架构转型中通常会使用Swarm,K8S,Mesos。
应用发布封装:传统应用会使用JAVA开发并发布成war/ear文件封装,再发布到中间件。微服务架构通常会将应用发布成容器的镜像。
应用框架:传统应用通常会使用Spring,Struts,hibernate来开发,而目前互联网分布式应用更多使用的是SpringCloud, Double, EDAS等微服务架构。
开发运维:传统应用会使用可控的发布,保守的运维,新功能上线需要数周,甚至数月时间;互联网分布式架构更多使用的是DevOps持续集成,敏捷快速迭代。
我们理解,互联网分布式应用发生这些架构的改变,目标都是使业务更加敏捷,更加具有弹性,能承载来自互联网的高并发压力。在创新架构下,业务应用可以通过微服务的方式随时进行横向扩展,但压力并不会被处理掉,负载会直接透传到数据层面,解决了应用弹性的问题,反而对数据库产生了更大的挑战。互联网的分布式架构要求数据库更加敏捷,拥有更好的弹性以及更低的成本。(传统应用中,一个应用可能只需要一个数据库作承载,但在互联网分布式应用下,进行了微服务改造之后,一个业务系统可能就需要数十个甚至上百个数据库去承载,因此对成本也提出了要求。)
实战——阿里云数据库为业务架构变迁做好准备
目前,阿里云的数据库形态已经覆盖了互联网中99%的业务场景。关系型数据库包括有MySQL,SQL Server,PG,POLARDB。NoSQL产品家族包括Redis,MongoDB,HBase等。同时具备混合分析型的数据仓库,分布式数据库DRDS,以及数据库服务于工具(DTS,DBS,CloudDBA,DMS等)。
演进路线
阿里云上提供了这么多的数据库产品,在实际应用中该如何进行选择呢?我们已经为业务的快速发展和更新迭代做好了准备。这是我们建议的应用架构的演进路线:在业务的初期,建议选择MySQL来快速构建业务应用。当成长起来之后,独立MySQL无法承载更大业务压力的时候,可以基于MySQL做读写分离,不需要对应用做任何改造。我们进入快速成长期,读写分离也无法承载业务需求时,可以无缝迁移到POLARDB,迁移中不需要对业务系统做任何的更改,而且POLARDB的读写分离通过共享存储消除了复制延迟,更适合对数据一致性有更高要求的场景。当业务进一步发展壮大期间,还可以在POLARDB上做垂直拆分。垂直拆分是指将业务模块垂直拆分到不同数据库实例,分到多个独立数据库中去,比如分成用户库,订单库,仓储库等,从而用更多的独立数据库联合来应对业务负载的压力。当业务发展到象淘宝这么大的规模和体量,就需要采用DRDS进行分布式改造、跨机房多活,以及根据业务拆分做单元化改造,这正是阿里淘系应用已经走过并行之有效的演进道路。
应用链路的优化——自动读写分离,短连接优化
我们使用数据库代理来进行链路访问层的优化。访问数据库的标准模式是直接访问主实例和只读实例。在这种模式下需要在业务层面做读写分离的逻辑拆分。我们提供了代理模式,让业务层和数据库层完全解耦。在访问数据库时,不需要直接连接数据库实例,而是连接对业务完全透明的Proxy,它接收到SQL请求后会自动化做读写分离,把所有写操作路由到主实例,并把读操作负载均衡的路由到只读实例上,从而实现对业务透明的自动化读写分离。代理模式除了实现读写分离外,还可以进行故障数据库的透明切换。不论是标准模式还是代理模式,当主实例发生故障后,都可以自动切换到备份的实例上,保证数据库的可用性。但在标准模式中,切换后业务需要进行数据库重连,但通过Proxy,业务应用不需要重连,感受不到高可用切换。同时,代理模式还提供了短连接优化。举例来说,如果业务是使用PHP开发,它连接数据库就是采用短链接的方式,在访问数据库时每次连接都会产生connection,使得数据库在处理连接池上不堪重负。Proxy可以将短链接转化成长链接,并自主维护连接池。同时,代理模式还提供了防暴力破解的功能。比如Proxy可以检测到某个IP不停的尝试重输密码,并主动进行屏蔽。
实时分析数据仓库——POLARMPP,POLARDB最佳搭档
数据的处理可以分成数据库生态和大数据生态。数据库生态适合于处理交易订单等数据一致性要求强的场景,但在处理能力和处理量级上不会特别大。比如订单量在1TB、2TB级别时,还可以使用,但数量一旦增长到3TB~5TB时,单库的性能就会出现非常大的瓶颈,此时复杂的分析查询就会使得数据库不堪重负。通常的做法是采用大数据生态,通过ETL或数据复制的方式把在线事务处理产生的数据复制到Hadoop生态中进行数据实时分析。在Hadoop 生态中,标准方式是利用MapReduce或Spark来做数据分析,但开发人员并不习惯MR或Spark,也不喜欢使用Scala语言,他们还是习惯于使用SQL。所以在这种模式下,经常还要给开发人员准备Hive、Impla等类SQL组件,让研发人员仍然可以使用SQL来处理数据。这种方式存在的问题,在于在线事务处理和离线数据仓库之间有延迟,少则几秒,多则几分钟甚至几小时。并且数据实际上存了两份,并不经济。
针对这种情况,我们提供了POLAR MPP和HybridDB来解决,它可以很好的处理数据的写入,提供百万级的TPS,非常适合用于存储用户的行为、标签、Log日志等。这种模式可以对百亿级的大表做出毫秒级的响应,对多表关联做复杂的聚合,做多值的子列,全文检索。最重要的是,它可以和POLARDB共用一份数据,极大的缓解了数据库生态和大数据生态中需要存储两份数据,并且读写存在延迟的问题。
业务场景分析——互联网创新型应用场景实践
有了云原生数据库作为武器,互联网创新型的业务场景应该如何设计呢?在讲到创新型业务前,先看一下传统的采用MySQL一主N从的架构,如何构建数据仓库驱动BI报表实现商务智能。这种架构的问题是需要存储N份数据,做数据的同步复制。MySQL 的主从之间要进行数据复制,从业务库到分析库也要进行数据复制。
那么采用云原生POLARDB的系统架构应该如何设计呢?这之间,POLARDB和只读分析库构成了云原生的数据集群,由POLAR Store统一进行数据的共享存储。业务应用会把在线的业务写到POLARDB中,当POLARDB一主一从的模式不足以应对时,可以快速进行扩展,扩展成一主两从甚至N从。这种扩展区别于MySQL,他提供了敏捷性和业务弹性。如果数据量比较大,MySQL只读库的生成可能就需要数个小时的时间。而不管数据量多大,在POLARDB生态下创建一个只读库只需要分钟级的时间。并且只需要一份数据就可以通过POLARMPP来驱动业务报表。
云原生架构带来如下的业务收益:
标签:私有 方式 只读 png 暴力 商务 容器 war 分享图片
原文地址:http://blog.51cto.com/14031893/2308948