标签:mes puts hold out sts future start share repr
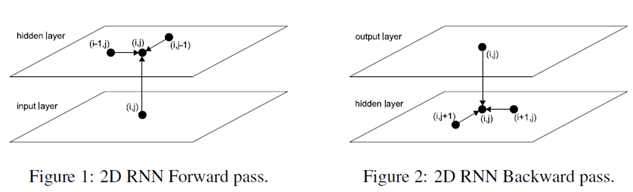
The basic idea of MDRNNs is to replace the single recurrent connection found in standard RNNs with as many recurrent connections as there are dimensions in the data. During the forward pass, at each point in the data sequence, the hidden layer of the network receives both an external input and its own activations from one step back along all dimensions.
Clearly, the data must be processed in such a way that when the network reaches a poin in an n-dimensional sequence, it has already passed through all the points from which it will rechive its previous activations.
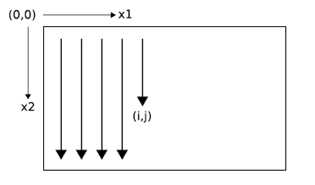
2D sequence ordering. The MDRNN forword pass starts at the origin and follows the direction of the arrows. The point(I,j) is never reached before both (i-1,j) and (i,j-1)
The forward pass of an MDRNN can then be carried out by feeding forward the input and the n previous hidden layer activations at each point in the ordered input sequence, and storing the resulting hidden layer activations at each point in the ordered input sequence, and storing the resulting hidden layer activations. Care must be taken at the sequence boundaries not to feed forward activations from points outside the sequence.
Note that each ‘point‘ in the input sequence will in general be a multivalued vector. For example, in a two dimensional color image, the inputs could be single pixels represented by RGB triples, or blocks of pixels, or the outputs of a preprocessing method such as a discrete cosine transform.
The error gradient of an MDRNN(that is, the derivative of some objective function with respect to the network weights) can be calculated with an n-dimensional extension of the backpropagation through time(BPTT) algorithm. As with one dimensional BPTT, the sequence is processed in the reverse order of the forward pass. At each timestep, the hidden layer receives both the output error derivatives and its own n ‘future‘ derivatives. Figure 2 illustrates the BPTT backword pass for two dimensions. Again, care must be taken at the sequence boundaries.
At a point in an n-dimensional sequence, define and respectively as the activations of the input unit and the hidden unit. Define as the weight of the connection going from unit j to unit k. Then for an n-dimensional MDRNN whose hidden layer consists of summation units with the tanh activation function, the forward pass for a sequence with dimensions can be sumarised as follows:

Defining and respectively as the derivatives of the objective function with respect to the activations of the output unit and the hidden unit at point x, the backward pass is:
Since the forward and backward pass require one pass each through the data sequence, the overall complexity of MDRNN training is linear in the number of data points and the unmber of network weights.

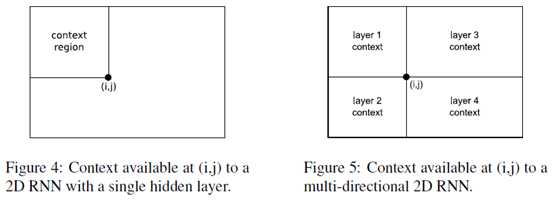
For one dimensional RNNs, the problem of multi-directional context was solved in 1997 by the introduction of bidirectional recurrent neural networks (BRNNs). BRNNs contain two separate hidden layers that process the input sequence in the forward and reverse directions. The two hidden layers are connected to a single output layer, thereby providing the network with access to both past and future context.
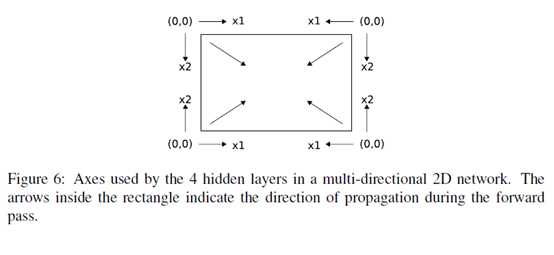
BRNNs can be extended to n-dimensional data by using separate hidden layers, each of which processes the sequence using the ordering defined above, but with a different choice of axes.
More specifically, the axes are chosen so that their origins lie on the the vertices of the sequence. The 2 dimensional case is illustrated in Figure 6.
As before, the hidden layers are connected to a single output layer, which now has access to all surrounding context.
If the size of the hidden layers is held constan, multi-direcitonal MDRNNs scales as O() for n-dimensional data. In practive however, we have found that using small layers gives better results than 1 large layer with the same overall number of weights, presumably because the data processing is shared between the hidden layers. This also holds in one dimension, as previous experiments have demonstrated. In any case the complexity of the algorithm remains linear in the number of data points and the number of parameters, and the number of parameters is independent of the data dimensionality.
For a multi-directional MDRNN, the forward and backward passes through an n-dimensional sequence can be summarized as follows:


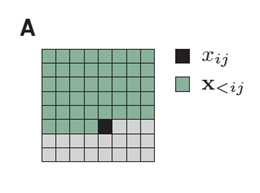
We factorize the distribution of images such that the prediction of a pixel(black) may depend on any pixel in the upper-left green region.
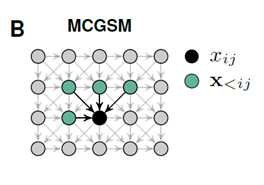
A graphical model representation of an MCGSM with a causal neighborhood limited to a small region.
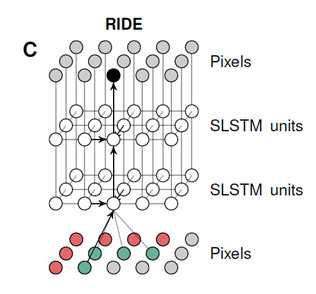
A visualization of our recurrent iamge model with two layers of spatial LSTMs. The pixels of the image are represented twice and some arrows are omitted for clarity. Through feedforward connections, the prediction of a pixel depends directly on its neighborhood(gre-e),but through recurrent connections it hs access to the information in a much larger region(r-ed).
Multi-Dimensional Recurrent Neural Networks
标签:mes puts hold out sts future start share repr
原文地址:https://www.cnblogs.com/kexinxin/p/9858492.html