标签:title div business 调整 内部使用 xtend pipe 需要 构造
精进篇:netty源码死磕7
巧夺天工——Pipeline入站流程详解
在讲解入站处理流程前,先脑补和铺垫一下两个知识点:
(1)如何向Pipeline添加一个Handler节点
(2)Handler的出站和入站的区分方式
在Pipeline实例创建的同时,Netty为Pipeline创建了一个Head和一个Tail,并且建立好了链接关系。
代码如下:
protected DefaultChannelPipeline(Channel channel) {
this.channel = ObjectUtil.checkNotNull(channel, "channel");
tail = new TailContext(this);
head = new HeadContext(this);
head.next = tail;
tail.prev = head;
}
也就是说,在加入业务Handler之前,Pipeline的内部双向链表不是一个空链表。而新加入的Handler,加入的位置是,插入在链表的倒数第二个位置,在Tail的前面。
加入Handler的代码,在DefaultChannelPipeline类中。
具体的代码如下:
@Override
public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
final AbstractChannelHandlerContext newCtx;
synchronized (this) {
//检查重复
checkMultiplicity(handler);
//创建上下文
newCtx = newContext(group, filterName(name, handler), handler);
//加入双向链表
addLast0(newCtx);
//…
}
callHandlerAdded0(newCtx);
return this;
}
加入之前,首先进行Handler的重复性检查。非共享类型的Handler,只能被添加一次。如果当前要添加的Handler是非共享的,并且已经添加过,那就抛出异常,否则,标识该handler已经添加。
什么是共享类型,什么是非共享类型呢?先聚焦一下主题,后面会详细解答。
检查完成后,给Handler创建包裹上下文Context,然后将Context加入到双向列表的尾部Tail前面。
代码如下:
private void addLast0(AbstractChannelHandlerContext newCtx) {
AbstractChannelHandlerContext prev = tail.prev;
newCtx.prev = prev;
newCtx.next = tail;
prev.next = newCtx;
tail.prev = newCtx;
}
这里主要是通过调整双向链接的指针,完成节点的插入。如果对双向链表不熟悉,可以自己画画指向变化的草图,就明白了。
对于入站和出站,Pipeline中两种不同类型的Handler处理器,出站Handler和入站Handler。
入站(inBound)事件Handler的基类是 ChannelInboundHandler,出站(outBound)事件Handler的基类是 ChannelOutboundHandler。
处理入站(inBound)事件,最典型的就是处理Channel读就绪事件,还有就是业务处理Handler。处理出站outBound操作,最为典型的处理,是写数据到Channel。
对应于两种Handler处理器的Context 包裹器,更加需要区分入站和出站。对Context的区分方式,又是什么呢?
首先,需要在Context加了一组boolean类型判断属性,判断出站和入站的类型。这组属性就是——inbound、outbound。这组属性,定义在上下文包裹器的基类中——ContextAbstractChannelHandlerContext 定义。它们在构造函数中进行初始化。
ContextAbstractChannelHandlerContext 的构造器代码如下:
abstract class AbstractChannelHandlerContext extends DefaultAttributeMap implements ChannelHandlerContext
{
private final boolean inbound;
private final boolean outbound;
AbstractChannelHandlerContext(DefaultChannelPipeline pipeline, EventExecutor executor, String name,
boolean inbound, boolean outbound) {
//….
this.pipeline = pipeline;
this.executor = executor;
this.inbound = inbound;
this.outbound = outbound;
//…
}
//…
}
final class DefaultChannelHandlerContext extends AbstractChannelHandlerContext {
//…
private final ChannelHandler handler;
private static boolean isInbound(ChannelHandler handler) {
return handler instanceof ChannelInboundHandler;
}
private static boolean isOutbound(ChannelHandler handler) {
return handler instanceof ChannelOutboundHandler;
}
DefaultChannelHandlerContext(
DefaultChannelPipeline pipeline, EventExecutor executor, String name, ChannelHandler handler) {
super(pipeline, executor, name, isInbound(handler), isOutbound(handler));
//….
this.handler = handler;
}
}
再看两个非通用的HandlerContext——head和tail。
在HeadContext,则调用父类构造器的第五个参数(outbound)的值为true,表示Head是一个出站类型的Context。代码如下:
final class HeadContext extends AbstractChannelHandlerContext
implements ChannelOutboundHandler, ChannelInboundHandler {
private final Unsafe unsafe;
HeadContext(DefaultChannelPipeline pipeline) {
//父类构造器
super(pipeline, null, HEAD_NAME, false, true);
//...
}
}
在TailContext,则调用父类构造器的第四个参数(inbound)的值为true,表示Tail是一个入站类型的Context。代码如下:
final class TailContext extends AbstractChannelHandlerContext implements ChannelInboundHandler {
TailContext(DefaultChannelPipeline pipeline) {
super(pipeline, null, TAIL_NAME, true, false);
//...
}
}
无论是哪种类型的handler,Pipeline没有单独和分开的入站和出站链表,都是统一在一个双向链表中进行管理。
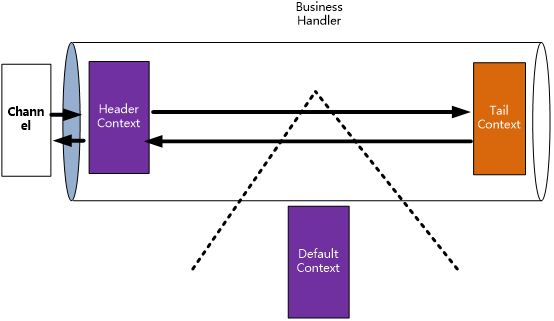
下图中,使用紫色代表入站Context,橙色代表出站Context。
在上图中,橙色表示出站Context,紫色表示入站Context。
在上图中的流程中,区分一个 ChannelHandlerContext到底是in(入站)还是out(出站) ,使用的是Context的isInbound() 和 isOutbound() 这一组方法。
赘述一下:
Tail是出站执行流程的启动点,但是,它最后一个入站处理器。
Hearder,是入站流程的启动起点,但是,它最后一个出站处理器。
感觉,有点儿饶。容易让人混淆。看完整个的入站流程和出站流程的详细介绍,就清楚了。
入站事件前面已经讲过,流向是从Java 底层IO到ChannelHandler。入站事件的类型包括连接建立和断开、读就绪、写就绪等。
基本上,,在处理流程上,大部分的入站事件的处理过程,是一致的。
通用的入站Inbound事件处理过程,大致如下(使用IN_EVT符号代替一个通用事件):
(1)pipeline.fireIN_EVT
(2)AbstractChannelHandlerContext.invokeIN_EVT(head, msg);
(3)context.invokeIN_EVT(msg);
(4)handler.IN_EVT
(5)context.fireIN_EVT(msg);
(6)Connect.findContextInbound()
(7)context.invokeIN_EVT(msg);
上面的流程,如果短时间内看不懂,没有关系。可以先看一个例子,再回来推敲学习这个通用流程。
下面以最为常见和最好理解的事件——读就绪的事件为例,将Inbound事件做一个详细的描述。
整个读就绪的入站处理流程图,如下:

入站事件处理的源头,在Channel的底层Java NIO 就绪事件。
Netty对底层Java NIO的操作类,进行了封装,封装成了Unsafe系列的类。比方说,AbstractNioByteChannel 中,就有一个NioByteUnsafe 类,封装了底层的Java NIO的底层Byte字节的读取操作。
为什么叫Unsafe呢?
很简单,就是在外部使用,是不安全的。Unsafe就是只能在Channel内部使用的,在Netty 外部的应用开发中,不建议使用。Unsafe包装了底层的数据读取工作,包装在Channel中,不需要应用程序关心。应用程序只需要从缓存中,取出缓存数据,完成业务处理即可。
Channel 读取数据到缓存后,下一步就是调用Pipeline的fireChannelRead()方法,从这个点开始,正式开始了Handler的入站处理流程。
从Channel 到Pipeline这一段,Netty的代码如下:
public abstract class AbstractNioByteChannel extends AbstractNioChannel
{
protected class NioByteUnsafe extends AbstractNioUnsafe {
@Override
public final void read() {
final ChannelPipeline pipeline = pipeline();
……
// 读取结果.
byteBuf = allocHandle.allocate(allocator);
……
int localReadAmount = doReadBytes(byteBuf);
………
// 通过pipeline dispatch(分发)结果到Handler
pipeline.fireChannelRead(byteBuf);
……
}
//通过重写newUnsafe() 方法
//取得内部类NioSocketChannelUnsafe的实例
@Override
protected AbstractNioUnsafe newUnsafe() {
return new NioSocketChannelUnsafe();
}
…
}
前面分析到,Pipeline中,入站事件处理流程的处理到的第一个Context是Head。
这一点,从DefaultChannelPipeline 源码可以得到验证,如下所示:
public class DefaultChannelPipeline implements ChannelPipeline
{
…
@Override
public final ChannelPipeline fireChannelRead(Object msg) {
AbstractChannelHandlerContext.invokeChannelRead(head, msg);
return this;
}
…
}
Pipeline将内部链表的head头作为参数,传入了invokeChannelRead的静态方法中。
就像开动了流水线的开关,开启了整个的流水线的循环处理。
一个Pipeline上有多个InBound Handler,每一个InBound Handler的处理,可以算做一次迭代,也可以说成小迭代。
每一个迭代,有四个动作。这个invokeIN_EVT方法,是整个四个动作的小迭代的起点。
四个动作,分别如下:
(1)invokeChannelRead(next, msg)
(2)context.invokeIN_EVT(msg);
(3)handler.IN_EVT
(4)context.fireIN_EVT(msg);
(5)Connect.findContextInbound()
局部的流程图如下:

整个五个动作中,只有第三步在Handler中,其他的四步都在Context中完成。
invokeChannelRead(next,msg) 静态方法,非常关键,其重要作为是:作为流水线迭代处理的每一轮循环小迭代的第一步。在Context的抽象基类中,源码如下:
abstract class AbstractChannelHandlerContext extends DefaultAttributeMap implements ChannelHandlerContext
{
//...
static void invokeChannelRead(final AbstractChannelHandlerContext next, final Object msg) {
……
next.invokeChannelRead(msg);
……
}
//...
}
其次,这个方法没有啥特别。只是做了一个二转。将处理传递给context实例,调用context实例的invokeChannelRead方法。强调一下,使用了同一个名称哈。但是后边的invokeChannelRead,是一个实例方法,而且只有一个参数。
流水线小迭代第二步,触发当前的Context实例的IN_EVT操作。
对于IN_EVT为ChannelRead的时候,第二步方法为invokeChannelRead,其源码如下:
abstract class AbstractChannelHandlerContext extends DefaultAttributeMap implements ChannelHandlerContext
{
private void invokeChannelRead(Object msg) {
……
((ChannelInboundHandler) handler()).channelRead(this, msg);
……
}
}
这一步很简单,就是将context和msg(byteBuf)作为参数,传递给Handler实例,完成业务处理。
在Handler中,可以获取到以上两个参数实例,作为业务处理的输入。在业务Handler中的IN_EVT方法中,可以写自己的业务处理逻辑。
流水线小迭代第三步,完后Context实例中Handler的IN_EVT业务操作。
如果Handler中的IN_EVT方法中没有写业务逻辑,则Netty提供了默认的实现。默认源码在ChannelInboundHandlerAdapter 适配器类中。
当IN_EVT为ChannelRead的时候,第三步的默认实现源码如下:
public class ChannelInboundHandlerAdapter extends ChannelHandlerAdapter implements ChannelInboundHandler
{
//默认的通道读操作
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ctx.fireChannelRead(msg);
}
//...
}
读完源码发现,这份默认源码,都没有做什么实际的处理。
唯一的干的活,就是调用ctx.fireChannelRead(msg),将msg通过context再一次发射出去。
进入第四步。
流水线小迭代第四步,寻找下家,触发下一家的入站处理。
整个是流水线的流动的关键一步,实现了向下一个HandlerContext的流动。
源码如下:
abstract class AbstractChannelHandlerContext extends DefaultAttributeMap implements ChannelHandlerContext
{
private final boolean inbound;
private final boolean outbound;
//...
@Override
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(), msg);
return this;
}
//..
}
第四步还是在ChannelInboundHandlerAdapter 适配器中定义。首先通过第五步,找到下一个Context,然后回到小迭代的第一步,完成了小迭代的一个闭环。
这一步,对于业务Handler而言,很重要。
在用户Handler中,如果当前 Handler 需要将此事件继续传播下去,则调用contxt.fireIN_EVT方法。如果不这样做, 那么此事件的流水线传播会提前终止。
第五步是查找下家。
代码如下:
public class ChannelInboundHandlerAdapter extends ChannelHandlerAdapter implements ChannelInboundHandler
{
//...
private AbstractChannelHandlerContext findContextInbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.next;
} while (!ctx.inbound);
return ctx;
}
}
这个是一个标准的链表查询操作。this表示当前的context,this.next表示下一个context。通过while循环,一直往流水线的下边找,知道查找到下一个入站Context为止。
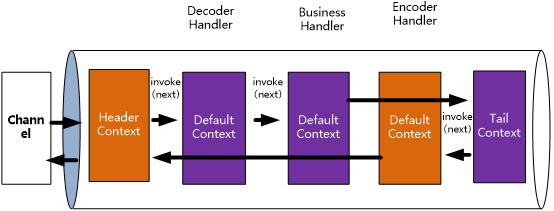
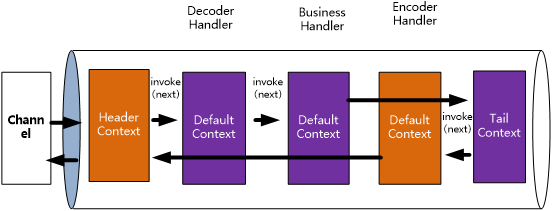
假定流水下如下图所示:
在上图中,如果当前context是head,则下一个是Decoder;如果当前context是Decoder,则下一个是Business;如果当前context是Business,则下一个是Tail。
第五步,是在第四步调用的。
找到之后,第四步通过 invokeChannelRead(findContextInbound(), msg)这个静态方法的调用,由回到小迭代的第一步,开始下一轮小的运行。
我们在前面讲到,在Netty中,Tail是最后一个IN boundContext。
final class TailContext extends AbstractChannelHandlerContext implements ChannelInboundHandler {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
onUnhandledInboundMessage(msg);
}
protected void onUnhandledInboundMessage(Object msg) {
//…
//释放msg的引用计数
ReferenceCountUtil.release(msg);
//..
}
}
在最后的一轮入站处理中。Tail没有做任何的业务逻辑,仅仅是对msg 释放一次引用计数。
这个msg ,是从channel 入站源头的过来的byteBuf。有可能是引用计数类型(ReferenceCounted)类型的缓存,则需要释放其引用。如果不是ReferenceCounted,则什么也不做。
关于缓存的引用计数,后续再开文章做专题介绍。
对入站(Inbound )事件的处理流程,做一下小节:
Inbound 事件是通知事件,当某件事情已经就绪后,从Java IO 通知上层Netty Channel。
Inbound 事件源头是 Channel内部的UNSafe;
Inbound 事件启动者是 Channel,通过Pipeline. fireIN_EVT启动。
Inbound 事件在 Pipeline 中传输方向是从 head 到 tail。
Inbound 事件最后一个的处理者是 TailContext, 并且其处理方法是空实现。如果没有其他的处理者,则对Inbound ,TailContext是唯一的处理者。
Inbound 事件的向后传递方法是contxt.fireIN_EVT方法。在用户Handler中,如果当前 Handler 需要将此事件继续传播下去,则调用contxt.fireIN_EVT方法。如果不这样做, 那么此事件的流水线传播会提前终止。
标签:title div business 调整 内部使用 xtend pipe 需要 构造
原文地址:https://www.cnblogs.com/crazymakercircle/p/9868218.html



{kind=link}
{kind=link}
{kind=link}