标签:比较 读者 sha 51cto color process md5 ofo free
二、dm dedup的原理如果看过上我上篇《linux I/O栈预习》的读者会很容易发现,dm dedup仅仅是linux I/O栈中沧海一粟的一个附加功能,那为什么我会对这个技术这么感兴趣?
那么我认为有两点比较有趣:其一是这个项目从2014年开始到如今也没有被合并入linux kernel主线的代码,说明其完备性不够。其二是因为这个技术确实是比较新颖,所以可以在其中有一些思考,而不像其他dm模块那样稳定。
那么直接开始,从它的设计开始说起:
dmdedup的设计思想,其实非常简单,从图中可以看出来三个主要的逻辑:
1、hash index
2、LBN Mapping
3、space manager
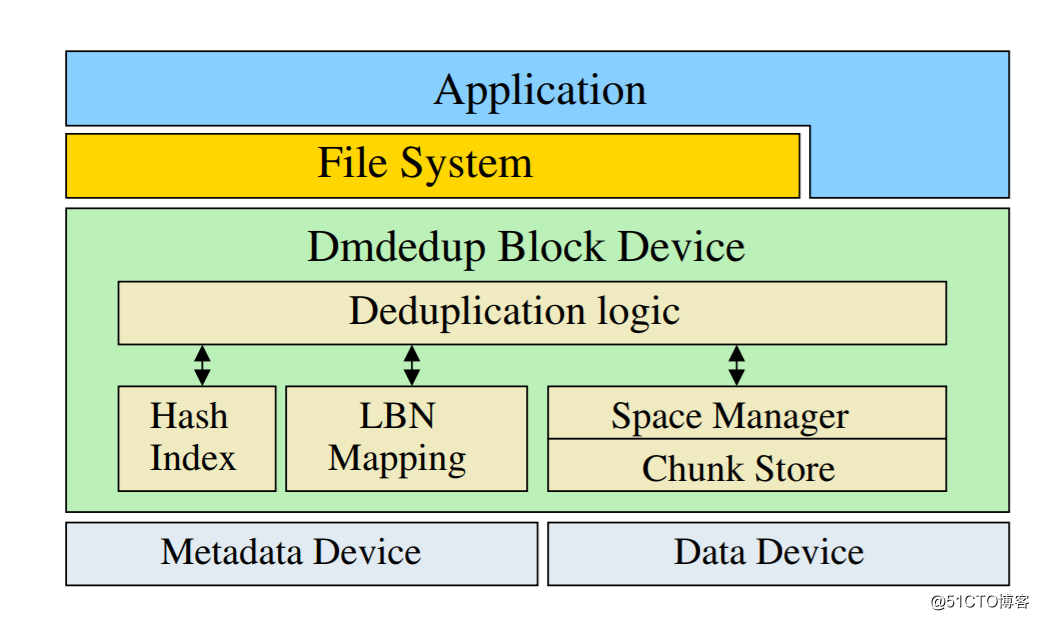
1.hash index,首先dm dmdedup支持非常多中hash算法,那么我们这里需要理解hash index产生的冲突概率
如果简单来讲,大致的算法产生hash碰撞的概率如下:
16位Hash碰撞概率为50%,则n = 301次
32位Hash碰撞概率为50%,则n = 77162次
128位MD5碰撞概率为50%,则n = 21,719,381,355,163,562,492次
具体算法公式请参见:http://www.freezhongzi.info/?p=100
从上述的碰撞百分之50的次数:我们大致可以推算出来,如果对于定长去重(那么如果采用md5,大概得有2 x 10^19才可能有百分之50的概率出现相同的md5值),但是这样的分析不够全面,因为还要考虑到硬盘bit错误(概率大概是10 ^-18),所以考虑这个因素公式的参数要重新去填写。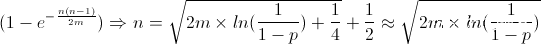
那么n 约等于 2 ^128 x10^-18再开根,大约是2 x10^10次方,如果按照4k去算,大概能够表示,100T的数据是不重复的。
device-mapper deduplication (dm dedup) <2>概要
标签:比较 读者 sha 51cto color process md5 ofo free
原文地址:http://blog.51cto.com/12580077/2310366