标签:nload rev this 高级技巧 css布局 控制 跳过 figure ict
例如:求字符串‘nininihaoa‘中出现次数最多字符
方法一:
var str = "nininihaoa";
var o = {};
for (var i = 0, length = str.length; i < length; i++) {
var char = str.charAt(i);
if (o[char]) {
o[char]++; //次数加1
} else {
o[char] = 1; //若第一次出现,次数记为1
}
}
console.log(o); //输出的是完整的对象,记录着每一个字符及其出现的次数
//遍历对象,找到出现次数最多的字符的次数
var max = 0;
for (var key in o) {
if (max < o[key]) {
max = o[key]; //max始终储存次数最大的那个
}
}
for (var key in o) {
if (o[key] == max) {
//console.log(key);
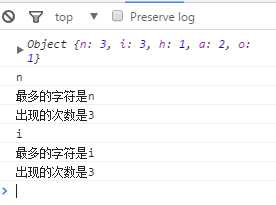
console.log("最多的字符是" + key);
console.log("出现的次数是" + max);
}
}
结果如图所示:
方法二,当然还可以使用reduce方法来实现:
var arrString = ‘abcdaabc‘;
arrString.split(‘‘).reduce(function(res, cur) {
res[cur] ? res[cur] ++ : res[cur] = 1
return res;
}, {})
想详细了解reduce()方法,可以参考:《JS数组reduce()方法详解及高级技巧》
jQuery实现方式:
var sum=0;
var wite;
for (var i = 1; i < 10; i++){
var div=$(‘<div class="class‘+i+‘"></div>‘);
$("body").append(div);
for(var j = i; j > 0; j--){
sum = j * i;
wite = (j+"X"+i+"="+sum);
div.prepend($(‘<span style="padding-right:10px">‘+wite+‘</span>‘));
}
}
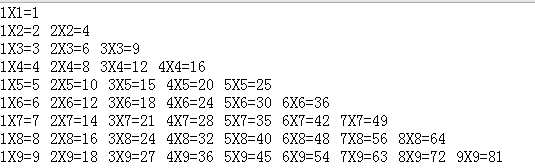
实现结果如图所示:
原生js实现方式:
css代码:
html,body,ul,li {
padding: 0;
margin: 0;
border: 0;
}
ul {
width: 900px;
overflow: hidden;
margin-top: 4px;
font-size: 12px;
line-height: 36px;
}
li {
float: left;
width: 90px;
margin: 0 4px;
display: inline-block;
text-align: center;
border: 1px solid #333;
background:yellowgreen;
}
js代码:
for(var i = 1; i <= 9; i++){
var myUl = document.createElement(‘ul‘);
for(var j = 1; j <= i; j++){
var myLi = document.createElement(‘li‘);
var myText = document.createTextNode(j + " × " + i + " = " + i*j);
myLi.appendChild(myText);
myUl.appendChild(myLi);
}
document.getElementsByTagName(‘body‘)[0].appendChild(myUl);
}
原生js实现效果如图所示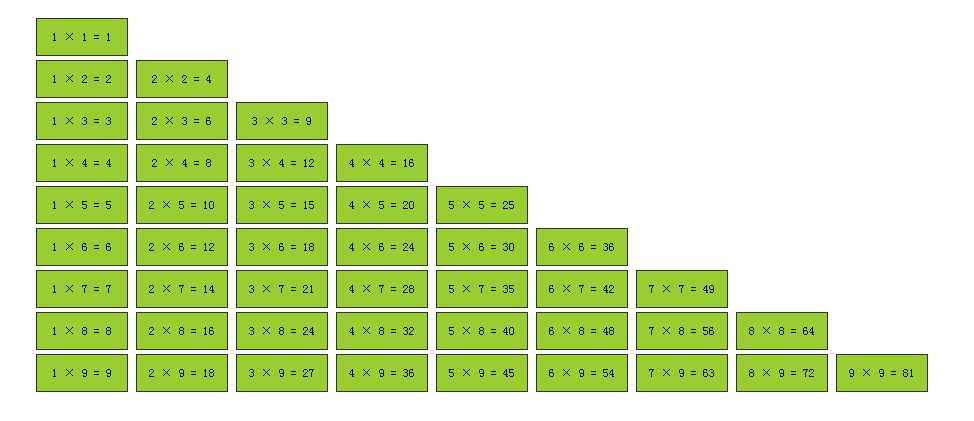
var fun = function(){
this.name = ‘peter‘;
return {
name: ‘jack‘
};
}
var p = new fun();
//请问p.name是:
var fun = function(){
this.name = ‘peter‘;
return ‘jack‘;
}
var p = new fun();
//请问p.name是:
var fun = function(){}
fun.prototype = {
info : {
name : ‘peter‘,
age : 25
}
}
var a = new fun();
var b = new fun();
a.info.name = ‘jack‘;
b.info.name = ‘tom‘;
//请问a.info.name和b.info.name分别是:
var fun = function(){
this.info = {
name : ‘peter‘,
age : 25
}
}
var a = new fun();
var b = new fun();
a.info.name = ‘jack‘;
b.info.name = ‘tom‘;
//请问a.info.name和b.info.name分别是:
var fun = function(){}
fun.prototype = {
name : ‘peter‘,
age : 25
}
var a = new fun();
var b = new fun();
a.name = ‘jack‘;
b.name = ‘tom‘;
//请问a.name和b.name分别是:
var fun = function(){
this.info = {
name : ‘peter‘,
age : 25
}
}
fun.prototype = {
info : {
name : ‘peter‘,
age : 25
}
}
var a = new fun();
var b = new fun();
a.info.name = ‘jack‘;
b.info.name = ‘tom‘;
//请问a.info.name和b.info.name分别是:
解答:
1,2题考察的是构造函数的返回值的问题。
每个函数都有返回值,如果使用了return语句,则返回return后跟的值,如果没有使用return,则默认返回undefined.
特别的,如果这个函数是构造函数,则默认返回this对象,如果构造函数内使用了return语句,并且return后跟的是一个对象,则这个构造函数返回的是这个对象,否则返回this.
所以1题中的p = {name: ‘jack‘},而2题中的p = {name: ‘peter‘}.
3, 4, 5, 6题都是考察prototype的知识。
3.两个都输出tom。首先你要知道原型模式的执行流程:
1.先查找构造函数实例里的属性或方法,如果有,就立即返回。
2.如果构造函数的实例没有,就去它的原型对象里找,如果有,就立即返回
4 .a.info.name 为jack,b.info.name为tom。原因我想你从第三题已经得出来了。
5.a.name输出jack,b.name输出tom。原因我想你从第三题已经得出来了。
6.a.info.name 为jack,b.info.name为tom。原因我想你从第三题已经得出来了。
注意:第三题 a.info.name这段代码,首先去访问了实例对象本身是否有info这个对象,发现没有就去原型上查找了,发现原型上有,所以地址共享了得到的值都是Tom;第五题是有区别的,a.name实例本身没有,给当前a这个实例对象执行赋值操作,没有去访问原型上的name。就相当于第三题先访问了原型上的info对象,第五题没有访问过程,只是在实例上添加了name属性值。
function sayHello(name)
{
var text = ‘Hello ‘ + name;
var sayAlert = function() { console.log(text); }
sayAlert();
}
sayHello("Bob") // 输出"Hello Bob"
在sayHello()函数中定义并调用了sayAlert()函数;sayAlert()作为内层函数,可以访问外层函数sayHello()中的text变量。
function sayHello2(name)
{
var text = ‘Hello ‘ + name; // 局部变量
var sayAlert = function() { console.log(text); }
return sayAlert;
}
var say2 = sayHello2("Jane");
say2(); // 输出"Hello Jane"
function buildList(list) {
var result = [];
for(var i = 0; i < list.length; i++) {
var item = ‘item‘ + list[i];
result.push(
function() {
console.log(item + ‘ ‘ + list[i]);
}
);
}
return result;
}
var fnlist = buildList([1,2,3]);
for (var j = 0; j < fnlist.length; j++) {
fnlist[j]();
}
得到的结果:连续输出3个"item3 undefined"
解析:通过执行buildList函数,返回了一个result,那么这个result存放的是3个匿名函数。然而这三个匿名函数其实就是三个闭包,因为它可以访问到父函数的局部变量。所以闭包内的保留的i是最终的值为3.所以list[3]肯定是undefined.
item变量值为item3.
改成如下代码:
function buildList(list) {
var result = [];
for(var i = 0; i < list.length; i++) {
var item = ‘item‘ + list[i];
result.push(
(function(i) {
console.log(item + ‘ ‘ + list[i]);
})(i)
);
}
return result;
}
var fnlist = buildList([1,2,3]);
得到的结果:
item1 1
item2 2
item3 3
解释:这儿虽然传递了一个数组进去,但是返回的是三个自执行的函数。
function newClosure(someNum, someRef)
{
var anArray = [1,2,3];
var num = someNum;
var ref = someRef;
return function(x)
{
num += x;
anArray.push(num);
console.log(‘num: ‘ + num + "; " + ‘anArray ‘ + anArray.toString() + "; " + ‘ref.someVar ‘ + ref.someVar);
}
}
closure1 = newClosure(40, {someVar: "closure 1"});
closure2 = newClosure(1000, {someVar: "closure 2"});
closure1(5); // 打印"num: 45; anArray 1,2,3,45; ref.someVar closure 1"
closure2(-10); // 打印"num: 990; anArray 1,2,3,990; ref.someVar closure 2"
每次调用newClosure()都会创建独立的闭包,它们的局部变量num与ref的值并不相同。
function sayAlice()
{
var sayAlert = function() { console.log(alice); }
var alice = ‘Hello Alice‘;
return sayAlert;
}
var sayAlice2 = sayAlice();
sayAlice2(); // 输出"Hello Alice"
alice变量在sayAlert函数之后定义,这并未影响代码执行。因为返回函数sayAlice2所指向的闭包会包含sayAlice()函数中的所有局部变量,这自然包括了alice变量,因此可以正常打印”Hello Alice”。
function setupSomeGlobals() {
var num = 666;
gAlertNumber = function() { console.log(num); }
gIncreaseNumber = function() { num++; }
gSetNumber = function(x) { num = x; }
}
setupSomeGlobals();
gAlertNumber(); // 输出666
gIncreaseNumber();
gAlertNumber(); // 输出667
gSetNumber(5);
gAlertNumber(); // 输出5
解释:首先gAlertNumber,gIncreaseNumber,gSetNumber是三个全局变量,并且其三个值都是匿名函数,然而这三个匿名函数本身都是闭包。他们操作的num都是保存在内存中的同一个num,所有会得出上面的结果。
下面看一个dom操作,使用闭包的例子:
// 这个代码是错误的,因为变量i从来就没背locked住
// 相反,当循环执行以后,我们在点击的时候i才获得数值
// 因为这个时候i操真正获得值
// 所以说无论点击那个连接,最终显示的都是I am link #10(如果有10个a元素的话)
var elems = document.getElementsByTagName(‘a‘);
for (var i = 0; i < elems.length; i++) {
elems[i].addEventListener(‘click‘, function (e) {
e.preventDefault();
alert(‘I am link #‘ + i);
}, ‘false‘);
}
// 这个是可以用的,因为他在自执行函数表达式闭包内部
// i的值作为locked的索引存在,在循环执行结束以后,尽管最后i的值变成了a元素总数(例如10)
// 但闭包内部的lockedInIndex值是没有改变,因为他已经执行完毕了
// 所以当点击连接的时候,结果是正确的
var elems = document.getElementsByTagName(‘a‘);
for (var i = 0; i < elems.length; i++) {
(function (lockedInIndex) {
elems[i].addEventListener(‘click‘, function (e) {
e.preventDefault();
alert(‘I am link #‘ + lockedInIndex);
}, ‘false‘);
})(i);
}
// 你也可以像下面这样应用,在处理函数那里使用自执行函数表达式
// 而不是在addEventListener外部
// 但是相对来说,上面的代码更具可读性
var elems = document.getElementsByTagName(‘a‘);
for (var i = 0; i < elems.length; i++) {
elems[i].addEventListener(‘click‘, (function (lockedInIndex) {
return function (e) {
e.preventDefault();
alert(‘I am link #‘ + lockedInIndex);
};
})(i), ‘false‘);
}
如下:
重复输出一个给定的字符串(str第一个参数)n 次 (num第二个参数),如果第二个参数num不是正数的时候,返回空字符串。
function repeatStringNumTimes(str, num) {
return str;
}
repeatStringNumTimes("abc", 3);
提供测试情况:
repeatStringNumTimes("*", 3) //应该返回 "***".
repeatStringNumTimes("abc", 3) //应该返回 "abcabcabc".
repeatStringNumTimes("abc", 4) //应该返回 "abcabcabcabc".
repeatStringNumTimes("abc", 1) //应该返回 "abc".
repeatStringNumTimes("*", 8) //应该返回 "********".
repeatStringNumTimes("abc", -2) //应该返回 "".
我将介绍三种方法:
function repeatStringNumTimes(string, times) {
var repeatedString = "";
while (times > 0) {
repeatedString += string;
times--;
}
return repeatedString;
}
repeatStringNumTimes("abc", 3);
不过这里还可以有几个变种:
对于老前端来说,首先一个可能会将字符串拼接,修改为 数组join()拼接字符串,例如:
function repeatStringNumTimes(string, times) {
var repeatedArr = []; //
while (times > 0) {
repeatedArr.push(string);
times--;
}
return repeatedArr.join("");
}
repeatStringNumTimes("abc", 3)
很多老前端都有用数组join()拼接字符串的“情怀”,因为很早以前普遍认为数组join()拼接字符串比字符串+拼接速度要快得多。不过现在未必,例如,V8 下+拼接字符串,要比数组join()拼接字符串快。我用这两个方法测试了3万次重复输出,只相差了几毫秒。
另一个变种可以用 for 循环:
function repeatStringNumTimes(string, times) {
var repeatedString = "";
for(var i = 0; i < times ;i++) {
repeatedString += string;
}
return repeatedString;
}
repeatStringNumTimes("abc", 3)
递归是一种通过重复地调用函数本身,直到它达到达结果为止的迭代操作的技术。为了使其正常工作,必须包括递归的一些关键特征。
function repeatStringNumTimes(string, times) {
if(times < 0)
return "";
if(times === 1)
return string;
else
return string + repeatStringNumTimes(string, times - 1);
}
repeatStringNumTimes("abc", 3);
这个解决方案比较新潮,您将使用 String.prototype.repeat() 方法:
repeat() 方法构造并返回一个新字符串,该字符串包含被连接在一起的指定数量的字符串的副本。 这个方法有一个参数 count 表示重复次数,介于0和正无穷大之间的整数 : [0, +∞) 。表示在新构造的字符串中重复了多少遍原字符串。重复次数不能为负数。重复次数必须小于 infinity,且长度不会大于最长的字符串。
function repeatStringNumTimes(string, times) {
if (times > 0)
return string.repeat(times);
else
return "";
}
repeatStringNumTimes("abc", 3);
您可以使用三元表达式作为 if/else 语句的快捷方式,如下所示:
function repeatStringNumTimes(string, times) {
return times > 0 ? string.repeat(times) : "";
}
repeatStringNumTimes("abc", 3);
转载地址:http://www.css88.com/archives/7045
var x=1,
y=0,
z=0;
function add(n){
n=n+1;
}
y=add(x);
z=x+y;
console.log("y1:"+y);
console.log("z1:"+z);
function add(n){
n=n+3;
}
y=add(x);
z=x+y;
console.log("y2:"+y);
console.log("z2:"+z);
求y,z的值。
结果为:
y1:undefined
z1:NaN
y2:undefined
z2:NaN
变化一下:
var x=1,
y=0,
z=0;
function add(n){
return n=n+1;
}
y=add(x);
z=x+y;
console.log("y1:"+y);
console.log("z1:"+z);
function add(n){
return n=n+3;
}
y=add(x);
z=x+y;
console.log("y2:"+y);
console.log("z2:"+z);
求y,z的值
答案:
y1:4
z1:5
y2:4
z2:5
思考以下代码:
(function(){
var a = b = 5;
})();
console.log(b);
控制台(console)会打印出什么?
答案
上述代码会打印出5。
这个问题的陷阱就是,在立即执行函数表达式(IIFE)中,有两个命名,但是其中变量是通过关键词var来声明的。这就意味着a是这个函数的局部变量。与此相反,b是在全局作用域下的。
这个问题另一个陷阱就是,在函数中他没有使用"严格模式" (‘use strict‘;)。如果 严格模式 开启,那么代码就会报出未捕获引用错误(Uncaught ReferenceError):b没有定义。记住,严格模式要求你在需要使用全局变量时,明确地引用该变量。因此,你需要像下面这么写:
(function(){
‘use strict‘
var a = window.b = 5;
})();
console.log(b);
再看如下一个例子:
var a = 6;
setTimeout(function () {
alert(a);
a = 666;
}, 1000);
a = 66;
结果:66
在 String 对象上定义一个 repeatify 函数。这个函数接受一个整数参数,来明确字符串需要重复几次。这个函数要求字符串重复指定的次数。举个例子:
console.log(‘hello‘.repeatify(3));
应该打印出hellohellohello.
答案:
String.prototype.repeatify = String.prototype.repeatify || function(times) {
var str = ‘‘;
for (var i = 0; i < times; i++) {
str += this;
}
return str;
};
在这里,另一个关键点是,看你怎样避免重写可能已经定义了的方法。这可以通过在定义自己的方法之前,检测方法是否已经存在。
String.prototype.repeatify = String.prototype.repeatify || function(times){
/*code here*/
};
当你需要为旧浏览器实现向后兼容的函数时,这一技巧十分有用。
执行以下代码的结果是什么?为什么?
function test() {
console.log(a);
console.log(foo());
var a = 1;
function foo() {
return 2;
}
}
test();
答案:
这段代码的执行结果是undefined 和 2。
这个结果的原因是,变量和函数都被提升(hoisted) 到了函数体的顶部。因此,当打印变量a时,它虽存在于函数体(因为a已经被声明),但仍然是undefined。换言之,上面的代码等同于下面的代码:
function test() {
var a;
function foo() {
return 2;
}
console.log(a);
console.log(foo());
a = 1;
}
test();
再看如下代码:
(function() {
console.log(typeof foo);
console.log(typeof bar);
var foo = ‘hello‘,
bar = function() {
return ‘world‘;
};
function foo() {
return ‘hello‘;
}
}());
结果:
function
undefined
以下代码的结果是什么?请解释你的答案。
var fullname = ‘John Doe‘;
var obj = {
fullname: ‘Colin Ihrig‘,
prop: {
fullname: ‘Aurelio De Rosa‘,
getFullname: function() {
return this.fullname;
}
}
};
console.log(obj.prop.getFullname());
var test = obj.prop.getFullname;
console.log(test());
答案:
这段代码打印结果是:Aurelio De Rosa 和 John Doe 。原因是,JavaScript中关键字this所引用的是函数上下文,取决于函数是如何调用的,而不是怎么被定义的。
在第一个console.log(),getFullname()是作为obj.prop对象的函数被调用。因此,当前的上下文指代后者,并且函数返回这个对象的fullname属性。相反,当getFullname()被赋值给test变量时,当前的上下文是全局对象window,这是因为test被隐式地作为全局对象的属性。基于这一点,函数返回window的fullname,在本例中即为第一行代码设置的。
修复前一个问题,让最后一个console.log() 打印输出Aurelio De Rosa.
答案:
这个问题可以通过运用call()或者apply()方法强制转换上下文环境。
console.log(test.call(obj.prop));
考虑下面的代码:
var nodes = document.getElementsByTagName(‘button‘);
for (var i = 0; i < nodes.length; i++) {
nodes[i].addEventListener(‘click‘, function() {
console.log(‘You clicked element #‘ + i);
});
}
请问,如果用户点击第一个和第四个按钮的时候,控制台分别打印的结果是什么?为什么?
答案:
两次打印都是nodes.length的值。
那么修复上题的问题,使得点击第一个按钮时输出0,点击第二个按钮时输出1,依此类推。
有多种办法可以解决这个问题,下面主要使用两种方法解决这个问题。
第一个解决方案使用立即执行函数表达式(IIFE)再创建一个闭包,从而得到所期望的i的值。实现此方法的代码如下:
var nodes = document.getElementsByTagName(‘button‘);
for (var i = 0; i < nodes.length; i++) {
nodes[i].addEventListener(‘click‘, (function(i) {
return function() {
console.log(‘You clicked element #‘ + i);
}
})(i));
}
另一个解决方案不使用IIFE,而是将函数移到循环的外面。这种方法由下面的代码实现:
function handlerWrapper(i) {
return function() {
console.log(‘You clicked element #‘ + i);
}
}
var nodes = document.getElementsByTagName(‘button‘);
for (var i = 0; i < nodes.length; i++) {
nodes[i].addEventListener(‘click‘, handlerWrapper(i));
}
代码片段一:
var name = "The Window";
var object = {
name : "My Object",
getNameFunc : function(){
return function(){
return this.name;
};
}
};
alert(object.getNameFunc()());
结果:The Window
代码片段二:
var name = "The Window";
var object = {
name : "My Object",
getNameFunc : function(){
var that = this;
return function(){
return that.name;
};
}
};
alert(object.getNameFunc()());
结果:My Object
文章地址:http://www.ruanyifeng.com/blog/2009/08/learning_javascript_closures.html
考虑如下代码:
console.log(typeof null);
console.log(typeof {});
console.log(typeof []);
console.log(typeof undefined);
答案:
object
object
object
undefined
下面代码运行结果是什么?请解释。
function printing() {
console.log(1);
setTimeout(function() { console.log(2); }, 1000);
setTimeout(function() { console.log(3); }, 0);
console.log(4);
}
printing();
答案:
1 4 3 2
想知道为什么输出顺序是这样的,你需要弄了解setTimeout()做了什么,以及浏览器的事件循环原理。浏览器有一个事件循环用于检查事件队列,处理延迟的事件。UI事件(例如,点击,滚动等),Ajax回调,以及提供给setTimeout()和setInterval()的回调都会依次被事件循环处理。因此,当调用setTimeout()函数时,即使延迟的时间被设置为0,提供的回调也会被排队。回调会呆在队列中,直到指定的时间用完后,引擎开始执行动作(如果它在当前不执行其他的动作)。因此,即使setTimeout()回调被延迟0毫秒,它仍然会被排队,并且直到函数中其他非延迟的语句被执行完了之后,才会执行。
写一个isPrime()函数,当其为质数时返回true,否则返回false。
答案:
我认为这是面试中最常见的问题之一。然而,尽管这个问题经常出现并且也很简单,但是从被面试人提供的答案中能很好地看出被面试人的数学和算法水平。
首先, 因为JavaScript不同于C或者Java,因此你不能信任传递来的数据类型。如果面试官没有明确地告诉你,你应该询问他是否需要做输入检查,还是不进行检查直接写函数。严格上说,应该对函数的输入进行检查。
第二点要记住:负数不是质数。同样的,1和0也不是,因此,首先测试这些数字。此外,2是质数中唯一的偶数。没有必要用一个循环来验证4,6,8。再则,如果一个数字不能被2整除,那么它不能被4,6,8等整除。因此,你的循环必须跳过这些数字。如果你测试输入偶数,你的算法将慢2倍(你测试双倍数字)。可以采取其他一些更明智的优化手段,我这里采用的是适用于大多数情况的。例如,如果一个数字不能被5整除,它也不会被5的倍数整除。所以,没有必要检测10,15,20等等。
最后一点,你不需要检查比输入数字的开方还要大的数字。我感觉人们会遗漏掉这一点,并且也不会因为此而获得消极的反馈。但是,展示出这一方面的知识会给你额外加分。
现在你具备了这个问题的背景知识,下面是总结以上所有考虑的解决方案:
function isPrime(number) {
// If your browser doesn‘t support the method Number.isInteger of ECMAScript 6,
// you can implement your own pretty easily
if (typeof number !== ‘number‘ || !Number.isInteger(number)) {
// Alternatively you can throw an error.
return false;
}
if (number < 2) {
return false;
}
if (number === 2) {
return true;
} else if (number % 2 === 0) {
return false;
}
var squareRoot = Math.sqrt(number); //平方根,比如Math.sqrt(9)为3
for(var i = 3; i <= squareRoot; i += 2) {
if (number % i === 0) {
return false;
}
}
return true;
}
其中代码中用到了Number.isInteger(),该方法是ES6方法,用来判断一个值是否为整数。
例如:
Number.isInteger(25) // true
Number.isInteger(25.0) // true
Number.isInteger(25.1) // false
Number.isInteger("15") // false
Number.isInteger(true) // false
需要注意的是,在JavaScript内部,整数和浮点数是同样的储存方法,所以25和25.0被视为同一个值。
1、基本数据类型:undefined、null、String、Number、boolean。
2、有以下两个函数,定义一个对象使其拥有这两个函数属性。
function mobile(){
return ‘mobile‘;
}
function phone(){
return ‘phone‘;
}
var a = {};
a.mobile = mobile();
a.phone = phone();
console.log(a);
3、(考察了对象变量和堆内存)
var a = {n:10,m:20};
var b = a;
b.n = 30;
console.log(a.n);
console.log(b);
结果:
30
Object {n: 30, m: 20}
4、(考察闭包)
var x = 20;
var a = {
x : 15,
fn : function(){
var x = 30;
return function(){
return this.x;
};
}
};
console.log(a.fn());
console.log((a.fn())());
console.log(a.fn()());
console.log(a.fn()() == (a.fn())());
console.log(a.fn().call(this));
console.log(a.fn().call(a));
结果:
1)、function(){return this.x;}
2)、20
3)、20
4)、true
5)、20
6)、15
5、(数组去重复项)
var arr = [‘a‘,‘g‘,‘q‘,‘d‘,‘a‘,‘e‘,‘q‘];
Array.prototype.unique = function(){
for(var i = 0; i < this.length; i++){
for(var j = i+1; j < this.length; j++){
if(this[i] == this[j]){
this.splice(j,1);
}
}
}
return this;
};
console.log(arr.unique());
此方法有缺陷,比如var arr = [‘a‘,‘a‘,‘a‘,‘g‘,‘q‘,‘d‘,‘a‘,‘e‘,‘q‘]; 那么得到的结果:["a", "a", "g", "q", "d", "e"]。知道原因吧?不知道请查看数组去重的方法《JS实现数组去重方法总结》
6、编写一个函数fn(Number n),将数字转为大写输出,如输入123,输出一百二十三
function fn(n){
if(!/^([1-9]\d*)/.test(n)){
return ‘非法数据‘;
}
var unit = ‘千百十亿千百十万千百十个‘;
if(n.length > unit.length){
return ‘数据过长‘;
}
var newStr = ‘‘;
var nlength = n.length;
unit = unit.substr(unit.length - nlength);
for(var i = 0; i < nlength; i++){
newStr += ‘零一二三四五六七八九‘.charAt(n[i]) + unit.charAt(i);
}
newStr = newStr.substr(0,newStr.length-1);
newStr = newStr.replace(/零(千|百|十)/g,‘零‘).replace(/(零)+/g,‘零‘).replace(/零(亿|万)/g,‘$1‘);
return newStr;
}
console.log(fn(‘205402002103‘));
1、考察了盒子模型
2、内联元素、块元素
3、css3的贝塞尔曲线(张鑫旭大神的解说)
4、弹性盒子flexbox
1、js跨域问题
1、有36辆自动赛车和6条跑道,没有计时器的前提下,最少用几次比赛可以筛选出最快的三辆赛车?
2、一面墙,单独工作时,A花18小时砌好,B花24小时,C花30小时,现A, B, C的顺序轮流砌,每人工作1小时换班,完工时,B总共干了多少小时?
A. 9小时
B. 8小时
C. 7小时
D. 6小时48分
答案:B,C
原因:
按照A,BC轮流砌,没有说明谁先开始。
1/18 + 1/24 + 1/30 = 47/360;
共同完成7小时:7*47/360 = 329/360,还差31/360;
如果A先砌:则B砌了7小时44分钟。
如果B先砌:则B砌了8小时。
如果C先砌:则B砌了7小时。
1)tite与h1的区别
2)b与strong的区别
3)i与em的区别
PS:不要小看这些题,80%人答不上来
title与h1的区别
定义:title是网站标题,h1是文章主题
作用:title概括网站信息,可以直接告诉搜索引擎和用户这个网站是关于什么主题和内容的,是显示在网页Tab栏里的;h1突出文章主题,面对用户,更突出其视觉效果,指向页面主体信息,是显示在网页中的。
定义:b(bold)是实体标签,用来给文字加粗,而strong是逻辑标签,作用是加强字符语气
区别:b标签只是加粗的样式,没有实际含义,常用来表达无强调或着重意味的粗体文字,比如文章摘要中的关键词、评测文章中的产品名称、文章的导言; 而strong表示标签内字符重要,用以强调,其默认格式是加粗,但是可以通过CSS添加样式,使用别的样式强调。
建议:为了符合CSS3的规范,b应尽量少用而改用strong
定义:i(italic)是实体标签,用来使字符倾斜,而em(emphasis)是逻辑标签,作用是强调文本内容
区别:i标签只是斜体的样式,没有实际含义,常用来表达无强调或着重意味的斜体,比如生物学名、术语、外来语(比如「de facto」这样的英语里常用的拉丁语短语);而em表示标签内字符重要,用以强调,其默认格式是斜体,但是可以通过CSS添加样式
建议:为了符合CSS3的规范,i应尽量少用而改用em
下面扩展一些其它的标签属性区别:
alt属性是在你的图片因为某种原因不能加载时在页面显示的提示信息,它会直接输出在原本加载图片的地方
title属性是在你鼠标悬停在该图片上时显示一个小提示,鼠标离开就没有了,有点类似jQuery的hover
定义:href指定网络资源的位置建立链接或关系,用在link和a等元素上。src将外部资源嵌入到当前标签所在位置,如img图片和js脚本等
区别:我们在可替换的元素上使用src,然而把href用于在涉及的文档和外部资源之间建立一个关系。 浏览器解析src属性时,会暂停其他资源的下载和处理,直至将该资源加载,编译,执行完毕。 浏览器解析到href的时候会识别该链接内容,对其进行下载不会停止对当前文档的处理
addEventListener,第三个参数是用来表示事件是以事件冒泡还是事件捕获这个各位都知道!但是他问的问题是:
我们给一个dom同时绑定两个点击事件,一个用捕获,一个用冒泡,你来说下会执行几次事件,然后会先执行冒泡还是捕获!!!
来吧,谁能说出来。。。。
考察优先级问题,反正会出很多莫名其妙的变形,比如将style标签写在body后与body前有什么区别,比如同一dom应用多个class其应该如何表现,比如class a定义颜色为blue,class b定义颜色为red,同时应用到dom上,dom作何显示。。。
好吧各位去回答吧。。。。。
function DemoFunction(){
this.init = function(){
var func = (function(va){
this.va = va;
return function(){
va += this.va;
return va;
}
})(function(va1, va2){
var va3 = va1 + va2;
return va1;
}(1,2));
console.log(func(20));
this.func = func;
console.log(this.func(100));
}
}
var a = new DemoFunction();
a.init();
结果:
2
NAN
首先我们得有如下几个概念:
执行上下文:每次当控制器转到ECMAScript可执行代码时,即会进入一个可执行上下文,参考文献:深入理解JavaScript系列(11):执行上下文(Execution Contexts)
this:this的创建是在 “进入执行上下文” 时创建的,在代码执行过程中是不可变的,参考文献:深入理解JavaScript系列(13):This? Yes,this!
自执行函数:准确来说应该叫:立即调用函数表达式。因为他声明后即执行,参考文献:深入理解JavaScript系列(4):立即调用的函数表达式
详细解释此段代码
这是代码的重点,第一层代码可以缩减为如下:
function DemoFunction(){
this.init = function(){
//省略代码....
}
}
表示为DemoFunction的实例提供init方法(声明:此处有误导成份,方法应尽可能放在原型链接上,也就是prototype上。),对外公开的接口。
var func = (function(va){
this.va = va;
return function(){
va += this.va;
return va;
}
})(/*省略代码...*/);
//省略代码....
上面代码介绍:
首先定义了一个立即执行函数,并把此函数的执行结果赋值给func。
需要注意立即执行函数中this.va=va这行代码,由于立即执行函数没有调用者,所以在进入可执行上下文时,this会被赋值为Global(浏览器中为window对象)。
更需要注意立即执行函数,返回的是一个匿名函数,也是一个闭包,在这里一定要注意一个问题:this是在进入可执行上下文时创建的。
var func = (function(va){
this.va = va;
return function(){
va += this.va;
return va;
}
})(function(va1, va2){
var va3 = va1 + va2;
return va1;
}(1,2));
//省略代码....
va的实际参数是一个自执行匿名函数,这个匿名函数接受了两个参数va1,va2,但只返回了va1。以此为据,那么可以确定va的值也就为1。接着就执行this.va=va这句代码,由于当前this为window,所以参数va的值被赋值到了window的一个叫va的属性上。
var func = (function(va){
this.va = va;
return function(){
va += this.va;
return va;
}
})(function(va1, va2){
var va3 = va1 + va2;
return va1;
}(1,2));
console.log(func(20));
this.func = func;
console.log(this.func(100));
}
结果分析:
第一个console.log输出的是func(20),这里一定要注意调用者是没有具体指定的,此时默认的就是Global(也就是widnow对象),因此输出为:2
第二个console.log输出的是this.func(100),可以看到this.func与func是指向同一个函数的引用,但此时的调用者则指定为this,也就是当前对象的实例,因此输出为:NaN。原因:this(当前对象的实例)作为调用者,在func的函数中va += this.va这句代码中的this是指向当前对象的实例,但当前对象的实例上是没有va属性的。但是va是有值的,当前值为2了。是因为闭包把va值存到内存中了。那么如何让第二次得到的值也是2呢,结果很简单,如下:
function DemoFunction(){
this.va = 0;
this.init = function(){
var func = (function(va){
this.va = va;
return function(){
va += this.va;
return va;
}
})(function(va1, va2){
var va3 = va1 + va2;
return va1;
}(1,2));
console.log(func(20));
this.func = func;
console.log(this.func(100));
}
}
var a = new DemoFunction();
a.init();
a.双倍边距bug:
例如:当给父元素内第一个浮动元素设置margin-left或margin-right的时候,margin属性会加倍,此时需要添加属性display:inline.
这样能避免双倍边距
b当浮动元素与非浮动元素相邻时,这个3像素的Bug就会出现,它会偏移3像素。我的解决办法是给非浮动元素加上浮动就可以了
c.当子元素浮动未知高度时,使父容器适应子元素的高度bug
overflow:auto;——-让父容器自适应子元素的高度
在IE6会自动扩展父层元素的高度,而IE8和FF等浏览器加上overflow:auto后,即可清除浮动。
所有浏览器 通用
height: 100px;
IE6 认:
_height: 100px;
IE6 ,IE7 都认:
*height: 100px;
IE7
*+height: 100px;
例如border(边框)、margin(边距)、padding(补白)和背景
HTML结构是页面的骨架,
一个页面就好像一幢房子, HTML结构就是钢筋混泥土的墙,一幢房子如果没有钢筋混泥土的墙那就是一堆费砖头,
不能住人,不能办公。css是装饰材料,
css如果没有html结构那就是一堆木板,一同油漆,没有了实际使用价值。当我们提到“语义标记”的时候,我们所说的HTML应该是完全脱离表现信息的,其中的标签应该都是语义化地定义了文档的结构。
意义:
SEO就是搜索引擎的优化
1、了解搜索引擎如何抓取网页和如何索引网页
你需要知道一些搜索引擎的基本工作原理,各个搜索引擎之间的区别
2、Meta标签优化
主要包括主题(Title),网站描述(Description),和关键词(Keywords)。还有一些其它的隐藏文字比如Author(作者),Category(目录),Language(编码语种)等。
3、如何选取关键词并在网页中放置关键词
搜索就得用关键词。关键词分析和选择是SEO最重要的工作之一。首先要给网站确定主关键词(一般在5个上下),然后针对这些关键词进行优化,包括关键词密度(Density),相关度(Relavancy),突出性(Prominency)等等。
4、了解主要的搜索引擎
虽然搜索引擎有很多,但是对网站流量起决定作用的就那么几个。比如英文的主要有Google,Yahoo,Bing等;中文的有百度,搜狗,有道等。
不同的搜索引擎对页面的抓取和索引、排序的规则都不一样。还要了解各搜索门户和搜索引擎之间的关系,比如AOL网页搜索用的是Google的搜索技
术,MSN用的是Bing的技术。
5、主要的互联网目录
6、你得学会用最少的广告投入获得最多的点击。
7、搜索引擎提交
8、链接交换和链接广泛度(Link Popularity)
跟获取你的访问量有很大的关系
9、标签的合理使用
比如尽量少用iframe,搜索引擎不会抓取到iframe里的内容,重要内容不要放在框架中。
不可使用display:none;的方法让文字隐藏,因为搜索引擎会过滤掉display:none;里边的内容,就不会被蜘蛛检索了。可以设置text-indent为负数,偏离浏览器之外,然后再利用overflow:hidden属性进行隐藏
a.行内样式
缺点:通用性差,效果特殊,优点:使用在CSS命令较少,并且不常改动的地方,使用这种方法反而是很好的选择。
b.内嵌样式:css写在head标签里面
优点:直接在HTML文档中,运用这样式比较快。缺点:代码臃肿,不利于维护
c.链接样式:引入外部的css文件
比较易于维护和美观的一种方式
d.导入样式
优点:一次性导入多个css文件。用于css文件数量庞大的系统中
CSS Sprite其实就是把网页中一些背景图片整合到一张图片文件中,再利用CSS的“background-image”,“background- repeat”,“background-position”的组合进行定位
CSS Sprites能减少图片的字节,加快网页的加载速度。缺点是开发和维护都是比较麻烦的。
border:30px;-webkit-border-radius:40px;
在标准模式中,浏览器根据规范呈现页面。在混杂模式中,页面以一种比较宽松的向后兼容的方式显示。
触发混乱模式:
IE6的触发:
DOCTYPE前加入XML声明<?xml version="1.0" encoding="utf-8"?><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
IE7的触发:
在XML声明和DOCTYPE之间加入HTML注释<?xml
version="1.0" encoding="utf-8"?><!– … and keep IE7 in quirks mode
–><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
IE6和IE7都可以触发:
在HTML4.01的DOCTYPE文档头部加入HTML注释<!– quirks mode –><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
各个浏览器的混杂模式,基本就是各个浏览器的私有模式,不相互兼容。所以,除非是为了兼容的问题,才采用混杂模式
行内元素有:a b span I img input select strong(input用于定义表单中的各个具体的表单元素)
块级元素有:div ul ol li dl dt dd
盒模型:margin border padding content
网页分成三个层次,即:结构层、表示层、行为层。
网页的结构层:由HTML 或XHTML 之类的标记语言负责创建,即HTML的语义化。,说白了就是一些标签
网页的表示层:说白了就是CSS
网页的行为层:说白了就是Javascript 语言和DOM 主宰的领域。
IE9以上开始支持
HTML5标签的改变:<header>,<footer>, <dialog>, <aside>, <figure>, <section> 等
CSS3实现圆角,阴影(text-shadow)对文字加特效(text-overflow,word-wrap,font-size-adjust),增加了更多的CSS选择器(全局选择器,组合选择器,继承选择器,伪类选择器等)
(1)创建新节点
createDocumentFragment() //创建一个DOM片段
createElement_x() //创建一个具体的元素
createTextNode() //创建一个文本节点
(2)添加、移除、替换、插入
appendChild()
removeChild()
replaceChild()
insertBefore()
(3)查找
getElementsByTagName() //通过标签名称
getElementsByName() //通过元素的Name属性的值
getElementById() //通过元素Id,唯一性
function A(name,age){
this.name=name?name:‘小刚‘;
this.age=age?age:30;
this.say=function(){
alert(this.name+"今年"+this.age+"岁了");
}
}
function B(){}
B.prototype=new A();
var C= new B();
C.say();
function parseQueryString(url) {
var pos;
var obj = {};
if (pos = url.indexOf("?") != -1) {
var urlstring = url.substring(pos + 1, url.lenght – 1);
var urlArr = urlstring.split("&");
var keyValue = [];
for (var i = 0; i < urlArr.lenght; i++) {
keyValue = urlArr[i].split("=");
obj[keyValue[0]] = keyValue[1];
}
}
return obj;
}
var objUrl = parseQueryString(url);
在工作中会经常遇到一些浏览器的兼容性问题,考虑的主要有2块方面的兼容性问题,一个是css样式的兼容性,另一个是js的兼容性问题。
(1).对于css样式来说,比如IE与火狐两大浏览器,它们对自身的浏览器都有默认的padding,margin等值,我们只需要在写样式的时候先清除它们默认样式的值,引入一个reset.css样式有能很大程度上解决一些常见问题,除此之外当然还有其它的样式问题,比如IE6的双边距问题,解决办法对IE6写样式display:inline;就能解决问题,还比如当子元素浮动未知高度时,使父容器自适应子元素的高度bug,解决办法就是在父容器样式里面加上overflow:auto就能解决(这个问题IE6中能适应子元素的高度,但是IE8跟火狐等其它浏览器不行,需要加上刚才的代码才能实现自适应),还比如当一个浮动元素跟一个非浮动元素相邻时就会出现3像素的bug,解决办法其实很简单给非浮动元素加上浮动就可以解决。
(2).对于js代码来说,也有一些常见的浏览器兼容性问题,就拿浏览器事件处理来说,IE事件处理程序需要2个方法来实现,attachEvent()和detachEvent()两个方法来实现,它们里边的参数只有2个,比如attachEvent()方法的两个参数:事件处理程序名字与事件处理程序函数。其它浏览器用到的是addEventListener()和removeEventListener()两个方法,但是它们的参数有3个,拿addEventListener()方法举例,第一个参数,要处理的事件名,比如onclick,但是不需要加上on,参数里面只需要click,第二个参事件处理程序的函数,最后一个参数是布尔值。布尔值如果是true,表示在捕获阶段调用事件处理程序;如果是false,表示在冒泡阶段调用事件处理程序。
new共经历了四个过程。
var fn = function () { };
var fnObj = new fn();
1、创建了一个空对象
var obj = new object();
2、设置原型链
obj._proto_ = fn.prototype;
3、让fn的this指向obj,并执行fn的函数体
var result = fn.call(obj);
4、判断fn的返回值类型,如果是值类型,返回obj。如果是引用类型,就返回这个引用类型的对象。
if (typeof(result) == "object"){
fnObj = result;
} else {
fnObj = obj;
}
问题表示:在某些场景下,需要将函数的 arguments 参数作为一个数组调用,但是 arguments 是一个奇异对象,所以试着将 arguments 转化为一个数组;
function argToArr(){
return [].slice.call(arguments, 0);
}
console.log(argToArr(1,2,3)); //[1,2,3]
function argToArr(){
return Array.slice.call(arguments, 0);
}
console.log(argToArr(1,2,3)); //[]
问:这是为什么呢?
另外还有一个问题,是关于 Array 是怎么找到 slice 方法的?
Array
本身是没有 slice 方法,它的方法在 Array.prototype 中,而我们在调用 slice 方法的时候,如果在 Array
本身没有找到 slice 方法的话,会通过它的原型链往上查找,而 Array.proto 并没有指向 Array.prototype,而是指向
Function(),那么它是怎么找到 slice 方法的呢?
解释:
第二段代码报错是因为Array是构造函数,不是对象,打开控制台,输入 typeof Array,结果是 function
你也说了slice()方法在其原型对象中,而[]就是Array的原型对象,在控制台中输入 Array.prototype,结果是[],所以第一段代码可以顺利执行。
第二段代码如下修改就可以了:
functionargToArr(){
return Array.prototype.slice.call(arguments, 0); // 改这一行
}
console.log(argToArr(1,2,3));
其实你的本质问题就在于误认为Array是数组对象,然而它是构造函数。
这个是浏览器隔离的,每个浏览器都会把localStorage存储在自己的UserData中,如chrome一般就是
C:\Users\你的计算机名\AppData\Local\Google\Chrome\User Data\Profile\Local Storage
如果要在浏览器查看,打开调试工具,在application选项卡下可以查看。
[] + {} 运算,首先是调用对象的 valueOf 方法,如果返回一个基本类型,则以该基本类型参与运算;否则调用 toString 方法,返回基本类型则参与运算。
数组和对象的 valueOf(默认)返回自身,因此不是基本类型,接着调用 toString,空数组返回空字符串,普通对象始终返回字符串 [object Object]。故视为两个字符串的拼接,结果为字符串 [object Object],其长度为 15。
一个例外是Date的实例,其实例首先调用 toString ,接着才调用valueOf。
可以这样验证:
([]).toString() // ""
({}).toString() // "[object Object]"
([]+{}) // "[object Object]"
1.禁止使用iframe(阻塞父文档onload事件);
*iframe会阻塞主页面的Onload事件;
*搜索引擎的检索程序无法解读这种页面,不利于SEO;
*iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载。
使用iframe之前需要考虑这两个缺点。如果需要使用iframe,最好是通过javascript
动态给iframe添加src属性值,这样可以绕开以上两个问题。
2.禁止使用gif图片实现loading效果(降低CPU消耗,提升渲染性能);
3、使用CSS3代码代替JS动画(尽可能避免重绘重排以及回流);
4、对于一些小图标,可以使用base64位编码,以减少网络请求。但不建议大图使用,比较耗费CPU;
小图标优势在于:
1.减少HTTP请求;
2.避免文件跨域;
3.修改及时生效;
5、页面头部的<style></style> 会阻塞页面;(因为 Renderer进程中 JS线程和渲染线程是互斥的);
6、页面头部<script</script> 会阻塞页面;(因为 Renderer进程中 JS线程和渲染线程是互斥的);
7、页面中空的 href 和 src 会阻塞页面其他资源的加载 (阻塞下载进程);
8、网页Gzip,CDN托管,data缓存 ,图片服务器;
9、前端模板 JS+数据,减少由于HTML标签导致的带宽浪费,前端用变量保存AJAX请求结果,每次操作本地变量,不用请求,减少请求次数
10、用innerHTML代替DOM操作,减少DOM操作次数,优化javascript性能。
11、当需要设置的样式很多时设置className而不是直接操作style。
12、少用全局变量、缓存DOM节点查找的结果。减少IO读取操作。
13、避免使用CSS Expression(css表达式)又称Dynamic properties(动态属性)。
14、图片预加载,将样式表放在顶部,将脚本放在底部 加上时间戳。
15、 避免在页面的主体布局中使用table,table要等其中的内容完全下载之后才会显示出来,显示比div+css布局慢。
对普通的网站有一个统一的思路,就是尽量向前端优化、减少数据库操作、减少磁盘IO。
向前端优化指的是,在不影响功能和体验的情况下,能在浏览器执行的不要在服务端执行,
能在缓存服务器上直接返回的不要到应用服务器,程序能直接取得的结果不要到外部取得,
本机内能取得的数据不要到远程取,内存能取到的不要到磁盘取,缓存中有的不要去数据库查询。
减少数据库操作指减少更新次数、缓存结果减少查询次数、将数据库执行的操作尽可能的让你的程序完成(例如join查询),
减少磁盘IO指尽量不使用文件系统作为缓存、减少读写文件次数等。程序优化永远要优化慢的部分,换语言是无法“优化”的。
1:捕获阶段 ---> 2:目标阶段 ---> 3:冒泡阶段
document ---> target目标 ----> document
由此,addEventListener的第三个参数设置为true和false的区别已经非常清晰了:
true表示该元素在事件的“捕获阶段”(由外往内传递时)响应事件;
false表示该元素在事件的“冒泡阶段”(由内向外传递时)响应事件。
var arr = [1,2,3,4,5,6,7,8,9,10];
arr.sort(function(){
return Math.random() - 0.5;
})
console.log(arr);
var arr = [ 1,5,1,7,5,9];
Math.max(...arr) // 9
[...new Set([2,"12",2,12,1,2,1,6,12,13,6])]
// [2, "12", 12, 1, 6, 13]
详细可参考:《JS实现数组去重方法整理》
标签:nload rev this 高级技巧 css布局 控制 跳过 figure ict
原文地址:https://www.cnblogs.com/moqiutao/p/9872066.html