标签:style mapr 分割 ... eclips tostring manager 命令 length
hadoop2.0伪分布式环境平台正常运行
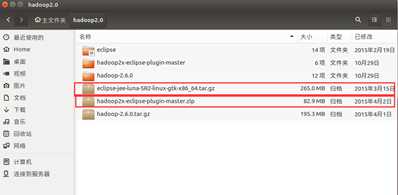
所需压缩包:eclipse-jee-luna-SR2-linux-gtk-x86_64.tar.gz
在Linux环境下运行的eclipse软件压缩包,解压后文件名为eclipse
hadoop2x-eclipse-plugin-master.zip
在eclipse中需要安装的Hadoop插件,解压后文件名为hadoop2x-eclipse-plugin-master
如图所示,将所有的压缩包放在同一个文件夹下并解压。
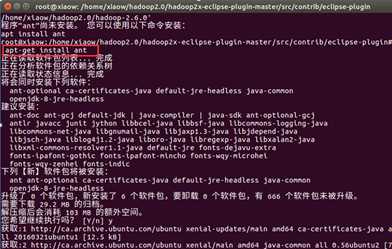
编译hadoop2x-eclipse-plugin-master的plugin 的插件源码,需要先安装ant工具
接着输入命令:
ant jar -Dversion=2.6.0 -Declipse.home=‘/home/xiaow/hadoop2.0/eclipse‘ # 刚才放进去的eclipse软件包的路径 -Dhadoop.home=‘/home/xiaow/hadoop2.0/hadoop-2.6.0‘ # hadoop安装文件的路径
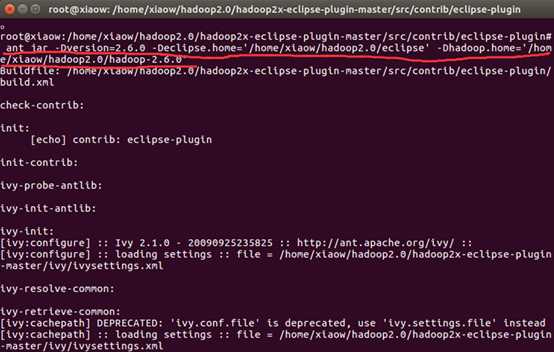
等待一小会时间就好了
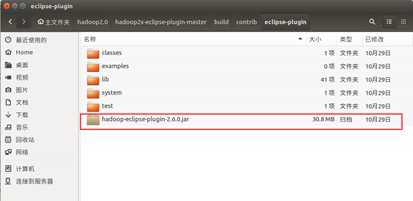
编译成功后,找到放在 /home/xiaow/ hadoop2.0/hadoop2x-eclipse-pluginmaster/build/contrib/eclipse-plugin下, 名为hadoop-eclipse-plugin-2.6.0.jar的jar包, 并将其拷贝到/hadoop2.0/eclipse/plugins下
输入命令:
cp -r /home/xiaow/hadoop2.0/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin/hadoop-eclipse-plugin-2.6.0.jar /home/xiaow/hadoop2.0/eclipse/plugins/

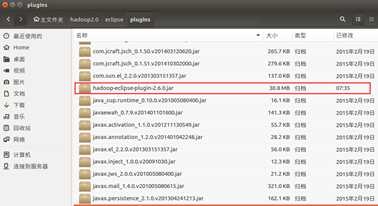
接下来打开eclipse软件
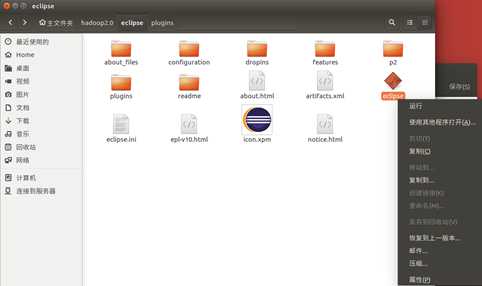
一定要出现这个图标,没有出现的话前面步骤可能错了,或者重新启动几次Eclipse
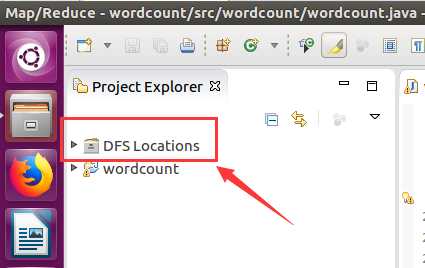
然后按照下面的截图操作:
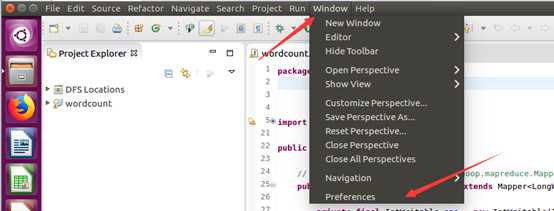
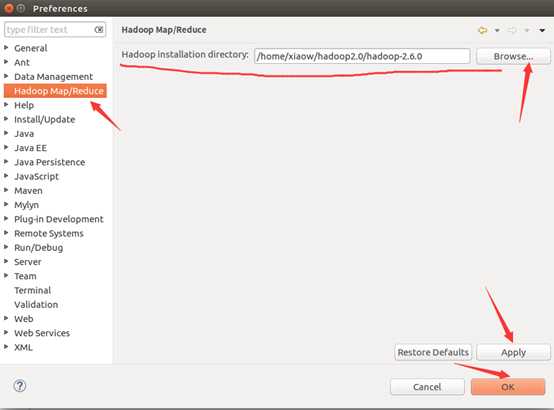
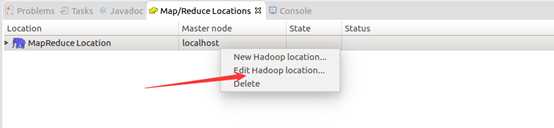
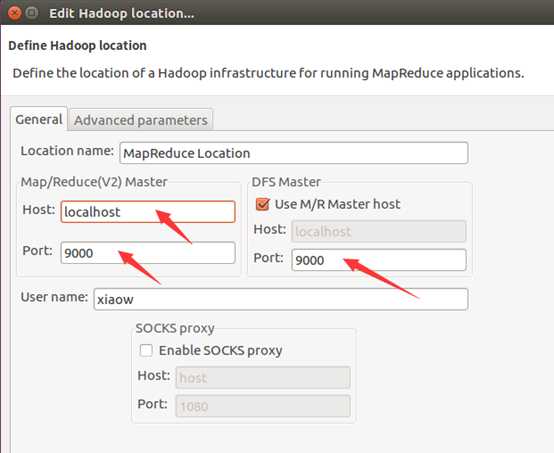
如此,Eclipse环境搭建完成。
建工程:
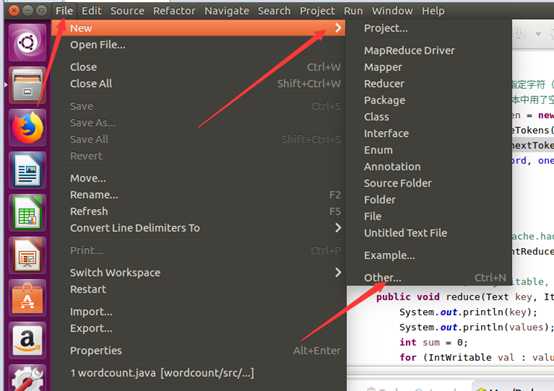
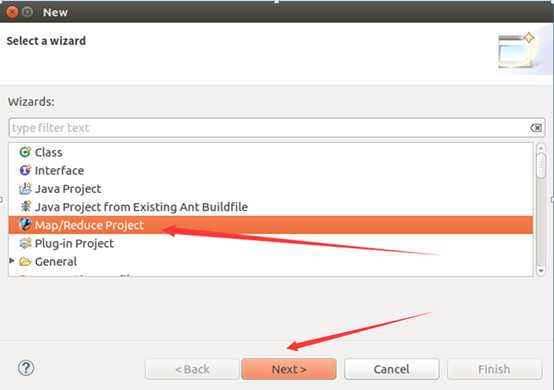
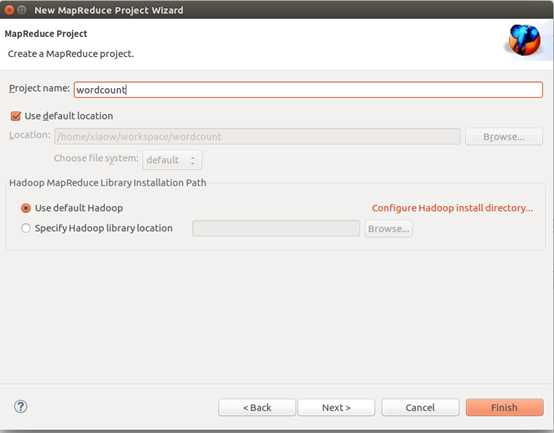
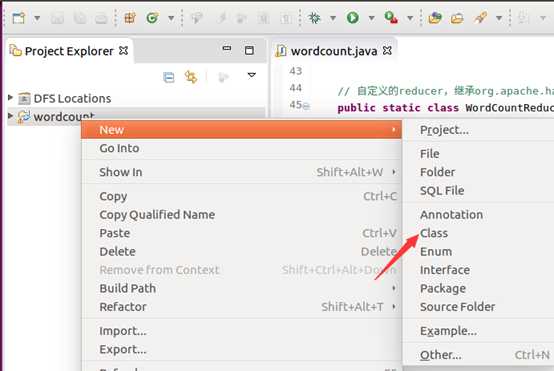
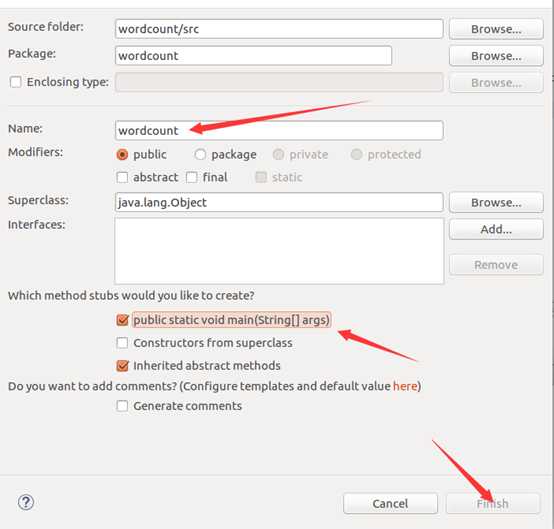
输入如下代码:
package wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.reduce.IntSumReducer;
import org.apache.hadoop.util.GenericOptionsParser;
public class wordcount {
// 自定义的mapper,继承org.apache.hadoop.mapreduce.Mapper
public static class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
// Mapper<LongWritable, Text, Text, LongWritable>.Context context
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println(line);
// split 函数是用于按指定字符(串)或正则去分割某个字符串,结果以字符串数组形式返回,这里按照“\t”来分割text文件中字符,即一个制表符
// ,这就是为什么我在文本中用了空格分割,导致最后的结果有很大的出入
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
// 自定义的reducer,继承org.apache.hadoop.mapreduce.Reducer
public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
// Reducer<Text, LongWritable, Text, LongWritable>.Context context
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
System.out.println(key);
System.out.println(values);
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
// 客户端代码,写完交给ResourceManager框架去执行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf,"word count");
// 打成jar执行
job.setJarByClass(wordcount.class);
// 数据在哪里?
FileInputFormat.addInputPath(job, new Path(args[0]));
// 使用哪个mapper处理输入的数据?
job.setMapperClass(WordCountMap.class);
// map输出的数据类型是什么?
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(LongWritable.class);
job.setCombinerClass(IntSumReducer.class);
// 使用哪个reducer处理输入的数据
job.setReducerClass(WordCountReduce.class);
// reduce输出的数据类型是什么?
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job.setInputFormatClass(TextInputFormat.class);
// job.setOutputFormatClass(TextOutputFormat.class);
// 数据输出到哪里?
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 交给yarn去执行,直到执行结束才退出本程序
job.waitForCompletion(true);
/*
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length<2){
System.out.println("Usage:wordcount <in> [<in>...] <out>");
System.exit(2);
}
for(int i=0;i<otherArgs.length-1;i++){
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
System.exit(job.waitForCompletion(tr0ue)?0:1);
*/
}
}
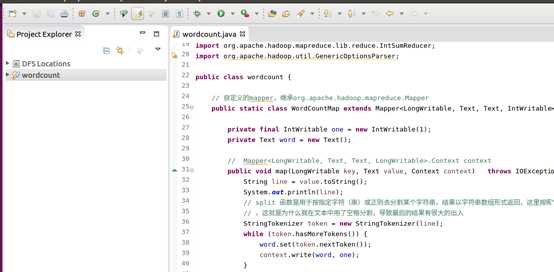
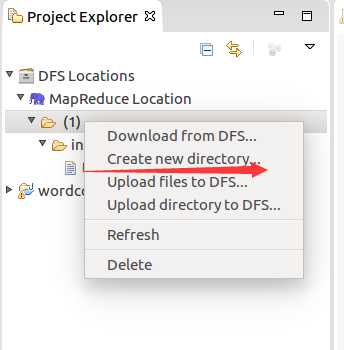
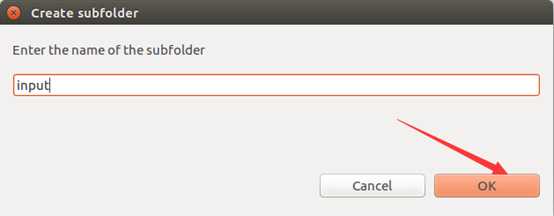
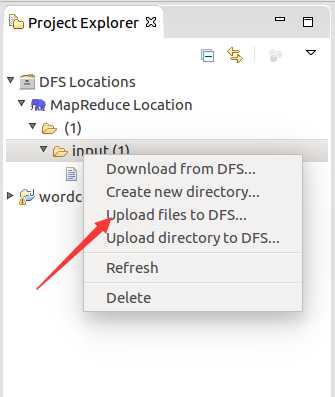
将准备到的文档导入进去
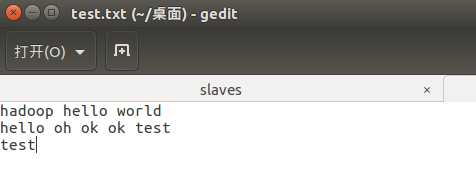
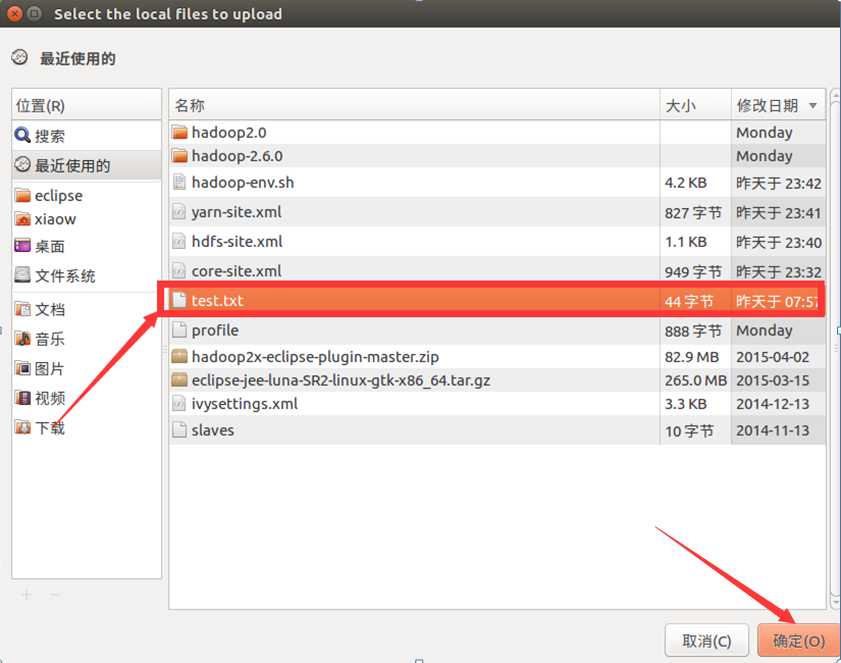
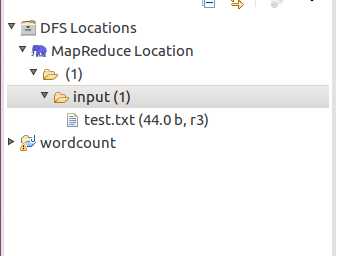
目录结构如下:
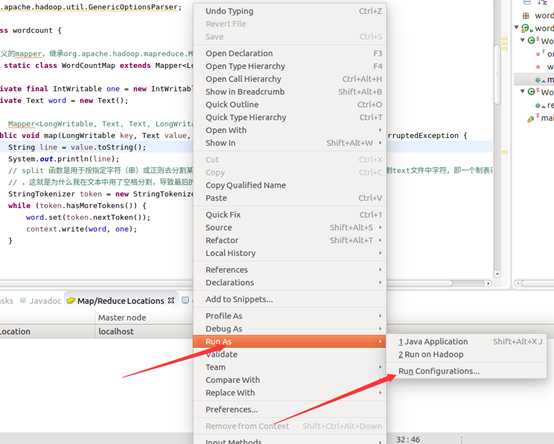
运行mapreduce程序
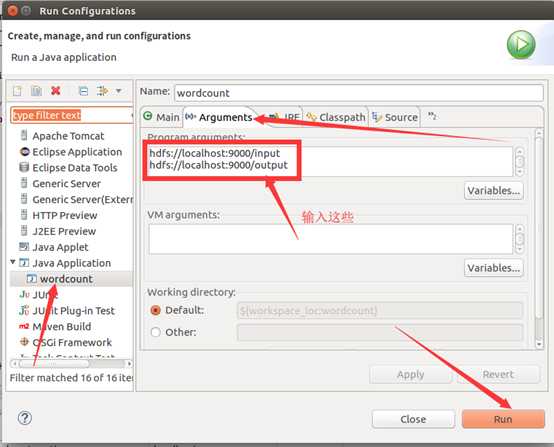
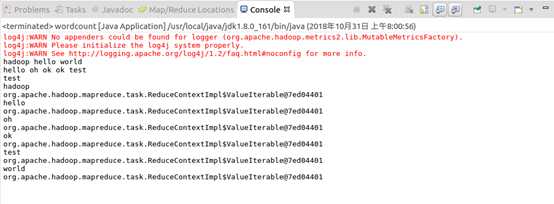
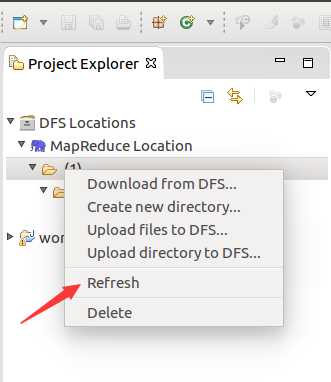
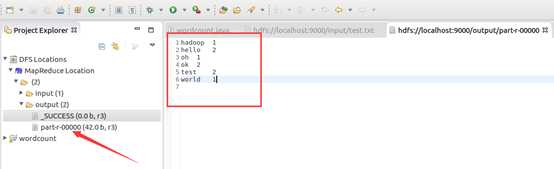
OK,搞定收工!!!
标签:style mapr 分割 ... eclips tostring manager 命令 length
原文地址:https://www.cnblogs.com/xiaoyh/p/9885678.html