标签:root 三元 ret 函数 tin 字典 ips src 分数
无论是训练机器学习或是深度学习,第一步当然是先划分数据集啦,今天小白整理了一些划分数据集的方法,希望大佬们多多指教啊,嘻嘻~
首先看一下数据集的样子,flower_data文件夹下有四个文件夹,每个文件夹表示一种花的类别
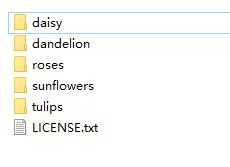

划分数据集的主要步骤:
1. 定义一个空字典,用来存放各个类别的训练集、测试集和验证集,字典的key是类别,value也是一个字典,存放该类别的训练集、测试集和验证集;
2.使用python获取所有的类别文件夹;
3.对每个类别划分训练集、测试集和验证集:(1)把该类别的所有有效图片放入一个列表中;(2)设置一个随机数对列表进行划分。
具体的代码实现如下所示
import glob import os.path import random import numpy as np # 图片数据文件夹 INPUT_DATA = ‘./flower_data‘ # 这个函数从数据文件夹中读取所有的图片列表并按训练、验证、测试数据分开 # testing_percentage和validation_percentage指定了测试数据集和验证数据集的大小 def create_image_lists(testing_percentage,validation_percentage): # 得到的所有图片都存在result这个字典里,key为类别的名称,value值也是一个字典,存放的是该类别的 # 文件名、训练集、测试集和验证集 result = {} # 获取当前目录下所有的子目录,这里x 是一个三元组(root,dirs,files),第一个元素表示INPUT_DATA当前目录, # 第二个元素表示当前目录下的所有子目录,第三个元素表示当前目录下的所有的文件 sub_dirs = [x[0] for x in os.walk(INPUT_DATA)] # sub_dirs = [‘./flower_data‘,‘./flower_data\\daisy‘,‘./flower_data\\dandelion‘, # ‘./flower_data\\roses‘,‘./flower_data\\sunflowers‘,‘./flower_data\\tulips‘] # 每个子目录表示一类花,现在对每类花划分训练集、测试集和验证集 # sub_dirs[0]表示当前文件夹本身的地址,不予考虑,只考虑他的子目录(各个类别的花) for sub_dir in sub_dirs[1:]: # 获取当前目录下所有的有效图片文件 extensions = [‘jpg‘,‘jpeg‘] # 把图片存放在file_list列表里 file_list = [] # os.path.basename(sub_dir)返回sub_sir最后的文件名 # 如os.path.basename(‘./flower_data/daisy‘)返回daisy dir_name = os.path.basename(sub_dir) for extension in extensions: file_glob = os.path.join(INPUT_DATA,dir_name,‘*.‘+extension) # glob.glob(file_glob)获取指定目录下的所有图片,存放在file_list中 file_list.extend(glob.glob(file_glob)) if not file_list: continue # 通过目录名获取类别的名称,返回将字符串中所有大写字符转换为小写后生成的字符串 label_name = dir_name.lower() # 初始化当前类别的训练数据集、测试数据集和验证数据集 training_images = [] testing_images = [] validation_images = [] for file_name in file_list: base_name = os.path.basename(file_name) # 随机将数据分到训练数据集、测试数据集和验证数据集 # 产生一个随机数,最大值为100 chance = np.random.randint(100) if chance < validation_percentage: validation_images.append(base_name) elif chance < (testing_percentage+validation_percentage): testing_images.append(base_name) else: training_images.append(base_name) # 将当前类别是数据放入结果字典 result[label_name]={‘dir‘:dir_name, ‘training‘:training_images, ‘testing‘:testing_images, ‘validation‘:validation_images} # 返回整理好的所有数据 return result result = create_image_lists(10,30) print(result)
运行结果:
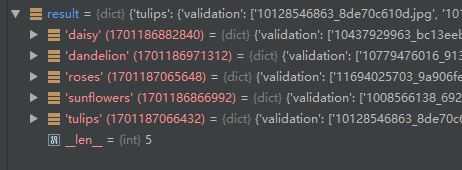
可以看出字典result中有五个key,表示五个类别。
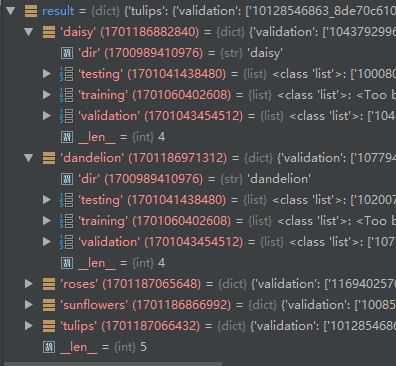
下图是各个类别的划分情况:
标签:root 三元 ret 函数 tin 字典 ips src 分数
原文地址:https://www.cnblogs.com/lijingblog/p/9888930.html