标签:style blog http color io os 使用 ar for
非常想写点关于多进程和多线程的东西,我确实非常爱他们。可是每每想动手写点关于他们的东西,却总是求全心理作祟,始终动不了手。
今天最终下了决心,写点东西,以后能够再修修补补也无妨。
一.为何须要多进程(或者多线程),为何须要并发?
这个问题也许本身都不是个问题。可是对于没有接触过多进程编程的朋友来说,他们确实无法感受到并发的魅力以及必要性。
我想,仅仅要你不是整天都写那种int main()究竟的代码的人,那么或多或少你会遇到代码响应不够用的情况,也应该有尝过并发编程的甜头。就像一个快餐点的服务员,既要在前台接待客户点餐,又要接电话送外卖,没有分身术肯定会忙得你焦头烂额的。幸运的是确实有这么一种技术,让你能够像孙悟空一样分身,灵魂出窍,乐哉乐哉地轻松应付一切状况,这就是多进程/线程技术。
并发技术,就是能够让你在同一时间同一时候运行多条任务的技术。你的代码将不不过从上到下,从左到右这样规规矩矩的一条线运行。你能够一条线在main函数里跟你的客户交流,还有一条线,你早就把你外卖送到了其它客户的手里。
所以,为何须要并发?由于我们须要更强大的功能,提供很多其它的服务,所以并发,不可缺少。
二.多进程
什么是进程。最直观的就是一个个pid,官方的说法就:进程是程序在计算机上的一次运行活动。
说得简单点,以下这段代码运行的时候
int main()
{
printf(”pid is %d/n”,getpid() );
return 0;
}
进入main函数,这就是一个进程,进程pid会打印出来,然后执行到return,该函数就退出,然后因为该函数是该进程的唯一的一次执行,所以return后,该进程也会退出。
看看多进程。linux下创建子进程的调用是fork();
#include <unistd.h>
#include <sys/types.h>
#include <stdio.h>
void print_exit()
{
printf("the exit pid:%d/n",getpid() );
}
main ()
{
pid_t pid;
atexit( print_exit ); //注冊该进程退出时的回调函数
pid=fork();
if (pid < 0)
printf("error in fork!");
else if (pid == 0)
printf("i am the child process, my process id is %d/n",getpid());
else
{
printf("i am the parent process, my process id is %d/n",getpid());
sleep(2);
wait();
}
}
i am the child process, my process id is 15806
the exit pid:15806
i am the parent process, my process id is 15805
the exit pid:15805
这是gcc測试下的执行结果。
关于fork函数,功能就是产生子进程,因为前面说过,进程就是运行的流程活动。
那么fork产生子进程的表现就是它会返回2次,一次返回0,顺序运行以下的代码。这是子进程。
一次返回子进程的pid,也顺序运行以下的代码,这是父进程。
(为何父进程须要获取子进程的pid呢?这个有非常多原因,当中一个原因:看最后的wait,就知道父进程等待子进程的终结后,处理其task_struct结构,否则会产生僵尸进程,扯远了,有兴趣能够自己google)。
假设fork失败,会返回-1.
额外说下atexit( print_exit ); 须要的參数肯定是函数的调用地址。
这里的print_exit 是函数名还是函数指针呢?答案是函数指针,函数名永远都仅仅是一串没用的字符串。
某本书上的规则:函数名在用于非函数调用的时候,都等效于函数指针。
说到子进程仅仅是一个额外的流程,那他跟父进程的联系和差别是什么呢?
我非常想建议你看看linux内核的注解(有兴趣能够看看,那里才有本质上的了解),总之,fork后,子进程会复制父进程的task_struct结构,并为子进程的堆栈分配物理页。理论上来说,子进程应该完整地复制父进程的堆,栈以及数据空间,可是2者共享正文段。
关于写时复制:因为一般 fork后面都接着exec,所以,如今的 fork都在用写时复制的技术,顾名思意,就是,数据段,堆,栈,一開始并不复制,由父,子进程共享,并将这些内存设置为仅仅读。直到父,子进程一方尝试写这些区域,则内核才为须要改动的那片内存拷贝副本。这样做能够提高 fork的效率。
三.多线程
线程是可运行代码的可分派单元。这个名称来源于“运行的线索”的概念。在基于线程的多任务的环境中,全部进程有至少一个线程,可是它们能够具有多个任务。这意味着单个程序能够并发运行两个或者多个任务。
简而言之,线程就是把一个进程分为非常多片,每一片都能够是一个独立的流程。这已经明显不同于多进程了,进程是一个拷贝的流程,而线程不过把一条河流截成非常多条小溪。它没有拷贝这些额外的开销,可是不过现存的一条河流,就被多线程技术差点儿无开销地转成非常多条小流程,它的伟大就在于它少之又少的系统开销。(当然伟大的后面又引发了重入性等种种问题,这个后面慢慢比較)。
还是先看linux提供的多线程的系统调用:
|
int pthread_create(pthread_t *restrict tidp, |
|
Returns: 0 if OK, error number on failure |
第一个參数为指向线程标识符的指针。
第二个參数用来设置线程属性。
第三个參数是线程执行函数的起始地址。
最后一个參数是执行函数的參数。
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
void* task1(void*);
void* task2(void*);
void usr();
int p1,p2;
int main()
{
usr();
getchar();
return 1;
}
void usr()
{
pthread_t pid1, pid2;
pthread_attr_t attr;
void *p;
int ret=0;
pthread_attr_init(&attr); //初始化线程属性结构
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); //设置attr结构为分离
pthread_create(&pid1, &attr, task1, NULL); //创建线程,返回线程号给pid1,线程属性设置为attr的属性,线程函数入口为task1,參数为NULL
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
pthread_create(&pid2, &attr, task2, NULL);
//前台工作
ret=pthread_join(pid2, &p); //等待pid2返回,返回值赋给p
printf("after pthread2:ret=%d,p=%d/n", ret,(int)p);
}
void* task1(void *arg1)
{
printf("task1/n");
//艰苦而无法预料的工作,设置为分离线程,任其自生自灭
pthread_exit( (void *)1);
}
void* task2(void *arg2)
{
int i=0;
printf("thread2 begin./n");
//继续送外卖的工作
pthread_exit((void *)2);
}
这个多线程的样例应该非常明了了,主线程做自己的事情,生成2个子线程,task1为分离,任其自生自灭,而task2还是继续送外卖,须要等待返回。(因该还记得前面说过僵尸进程吧,线程也是须要等待的。假设不想等待,就设置线程为分离线程)
额外的说下,linux下要编译使用线程的代码,一定要记得调用pthread库。例如以下编译:
gcc -o pthrea -pthread pthrea.c
四.比較以及注意事项
1.看完前面,应该对多进程和多线程有个直观的认识。假设总结多进程和多线程的差别,你肯定能说,前者开销大,后者开销较小。确实,这就是最主要的差别。
2.线程函数的可重入性:
说到函数的可重入,和线程安全,我偷懒了,引用网上的一些总结。
线程安全:概念比較直观。一般说来,一个函数被称为线程安全的,当且仅当被多个并发线程重复调用时,它会一直产生正确的结果。
可重入:概念基本没有比較正式的完整解释,可是它比线程安全要求更严格。依据经验,所谓“重入”,常见的情况是,程序运行到某个函数foo()时,收到信号,于是暂停眼下正在运行的函数,转到信号处理函数,而这个信号处理函数的运行过程中,又恰恰也会进入到刚刚运行的函数foo(),这样便发生了所谓的重入。此时假设foo()可以正确的运行,并且处理完毕后,之前暂停的foo()也可以正确运行,则说明它是可重入的。
线程安全的条件:
要确保函数线程安全,主要须要考虑的是线程之间的共享变量。属于同一进程的不同线程会共享进程内存空间中的全局区和堆,而私有的线程空间则主要包含栈和寄存器。因此,对于同一进程的不同线程来说,每一个线程的局部变量都是私有的,而全局变量、局部静态变量、分配于堆的变量都是共享的。在对这些共享变量进行訪问时,假设要保证线程安全,则必须通过加锁的方式。
可重入的推断条件:
要确保函数可重入,需满足一下几个条件:
1、不在函数内部使用静态或全局数据
2、不返回静态或全局数据,全部数据都由函数的调用者提供。
3、使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据。
4、不调用不可重入函数。
可重入与线程安全并不等同,一般说来,可重入的函数一定是线程安全的,但反过来不一定成立。它们的关系可用下图来表示:
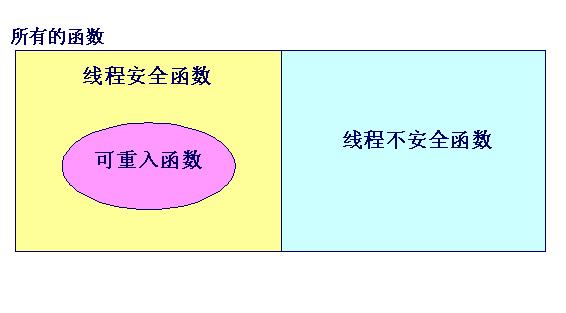
比方:strtok函数是既不可重入的,也不是线程安全的;加锁的strtok不是可重入的,但线程安全;而strtok_r既是可重入的,也是线程安全的。
假设我们的线程函数不是线程安全的,那在多线程调用的情况下,可能导致的后果是显而易见的——共享变量的值因为不同线程的訪问,可能发生不可预料的变化,进而导致程序的错误,甚至崩溃。
3.关于IPC(进程间通信)
因为多进程要并发协调工作,进程间的同步,通信是在所难免的。
略微列举一下linux常见的IPC.
linux下进程间通信的几种主要手段简单介绍:
也许你会有疑问,那多线程间要通信,应该怎么做?前面已经说了,多数的多线程都是在同一个进程下的,它们共享该进程的全局变量,我们能够通过全局变量来实现线程间通信。假设是不同的进程下的2个线程间通信,直接參考进程间通信。
4.关于线程的堆栈
说一下线程自己的堆栈问题。
是的,生成子线程后,它会获取一部分该进程的堆栈空间,作为其名义上的独立的私有空间。(为何是名义上的呢?)由于,这些线程属于同一个进程,其它线程仅仅要获取了你私有堆栈上某些数据的指针,其它线程便能够自由訪问你的名义上的私有空间上的数据变量。(注:而多进程是不能够的,由于不同的进程,同样的虚拟地址,基本不可能映射到同样的物理地址)
5.在子线程里fork
看过好几次有人问,在子线程函数里调用system或者 fork为何出错,或者fork产生的子进程是全然复制父进程的吗?
我測试过,仅仅要你的线程函数满足前面的要求,都是正常的。
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
void* task1(void *arg1)
{
printf("task1/n");
system("ls");
pthread_exit( (void *)1);
}
int main()
{
int ret=0;
void *p;
int p1=0;
pthread_t pid1;
pthread_create(&pid1, NULL, task1, NULL);
ret=pthread_join(pid1, &p);
printf("end main/n");
return 1;
}
上面这段代码就能够正常得调用ls指令。
只是,在同一时候调用多进程(子进程里也调用线程函数)和多线程的情况下,函数体内非常有可能死锁。
详细的样例能够看看这篇文章。
http://www.cppblog.com/lymons/archive/2008/06/01/51836.aspx
End:临时写到这吧,总结这东西,看来真不适合我写。有空了,想到什么了,再回来修修补补吧。
标签:style blog http color io os 使用 ar for
原文地址:http://www.cnblogs.com/yxwkf/p/4019041.html