标签:运行 stop end load data edr 开启 个数 rop 文件中
1>hive下创建表并导入数据
(数据可以是本地的,也可以是hdfs上的)
>创建本地文件 [root@zhiyou01 /]# vi student 1,xiaoming 2,xiaohong 3,xiaogang 4,tom 5,tim >hive下创建表;desc table;查看自己创建的表结构 create table t1(id int,name String) row format delimited fields terminated by ‘,‘;
>将本地文件导入表中 load data local inpath ‘/student‘ into table t1;
>每次上传同一个数据到同一个表中,会自动拷贝一份,所以可以使用overwrite
load data local inpath ‘/student‘ overwrite into table t1;
>查看表中数据: select * from t1;
>统计表里面一共有多少条记录;
select count(id) from t1; #运行的时候运行在mapredurce上
>删除表
drop table t1;
2>内部表与外部表
外部表和 内部表 在元数据的组织上是相同的,而实际数据的存储则有较大的差异 内部表 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载 数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓 库目录中完成。删除表时,表中的数据和元数据将会被同时删除
外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中, 只是与外部数据建立一个链接。当删除一个 外部表 时,仅删除该链接
>创建内部表步骤如上,相比缺少了external关键字的使用
>创建外部表
create external table t2 (id int,name String) row format delimited fields
terminated by ‘,‘;
3>创建分区表
把不同类型的数据放到不同的目录下;
1>创建分区表
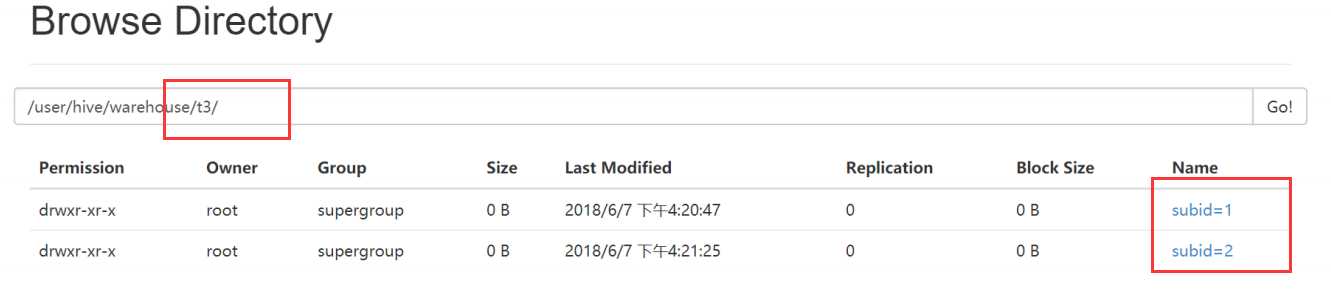
create table t3 (id int ,name String ) partitioned by (subid int ) row format delimited fields terminated by ‘,‘;
2>向表中插入数据
load data local inpath ‘/student‘ into table t3 partition(subid=1) ;
load data local inpath ‘/student2‘ overwrite into table t3 partition(subid=2) ;
3>查询分区:
hive> show partitions t3;
4>查询分区的某个文件
select * from t3 where subid=2;
效果如图:t3这个目录中含有两个不同的数据表,查询的时候可以提高效率
4>基于UDF对表中数据的查询操作:
写一个类继承与hive的UDF类,写一个方法,必须是evaluate,支持重载
package com.zhiyou.han.udf; import java.util.HashMap; import java.util.Map; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; public class MyUDF extends UDF{ private static Map<String, String> map= new HashMap<String, String>(); static { map.put("xiaoming", "小明");
map.put("xiaohong", "小红"); } public static Text evaluate(Text name) { String getName = name.toString(); String chainName = map.get(getName); if(chainName==null) { chainName = "null"; } return new Text(chainName); } }
>将这个类到处jar包上传liunx下 /注意jar包的地址
hive> add jar /U.jar;
>命名临时函数名:
hive> create temporary function U as ‘com.zhiyou100.udf.MyUDF‘;
>平常查出结果是这样的
hive> select id ,name from t1;
OK
1 xiaoming
2 xiaohong
3 xiaogang
>使用UDF查询后
hive> select id ,U(name) from t1;
OK
1 小明
2 小红
3 无名
>销毁临时的函数
hive> drop temporary function U;
>删除jar包
hive> delete jar /U.jar
5>使用java远程访问liunx下的hive
1>与jdbc的执行流程是一样的
jdbc的执行流程:
1.加载驱动
2.建立连接
3.准备sql
4.执行sql
5.处理结果
6.释放资
2>liunx下启动hive的远程服务:
>启动远程服务: #hive --service hiveserver //版本1的 #hive hiveserver2 //版本2的
>启动过程中在liunx下使用命令连接看是否能成功连接上
beeline -u jdbc:hive2://ip:10000/数据库名 IP 可以写自己的主机名或是自己的主机的IP地址
>报错如下
>出现root is not allowed tp (state=08S01,code=0)
需要在hadoop配置文件下core-site.xml文件中加入如下代码: 然后停止(stop-all.sh)hadoop,在启动(start-all.sh)hadoop,其中不需要预格式化,然后重新启动hive(直接输入hive)
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
>如果报错: inode="tmp/hive" root:supergroup:drwx---- 是因为权限的问题
执行一下该命令 hdfs dfs -chmod -R 777 /tmp/
3>执行完上述步骤,保证可以远程访问:
然后写java代码如下:
package com.zhiyou.han.hiveApi; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import org.apache.hadoop.io.Text; import com.zhiyou.han.udf.MyUDF; public class HiveApi { // 要求必须liunx下hive开启远程服务,和访问本地的的mysql数据库一个原理 public static void main(String[] args) throws Exception { // 1.加载驱动 Class.forName("org.apache.hive.jdbc.HiveDriver"); // 2.建立连接,输入自己的IP,且端口号为 1000 String url = "jdbc:hive2://192.168.188.130:10000/default"; String user = "root"; String password = "root"; Connection conn = DriverManager.getConnection(url, user, password); // 3.准备sql语句 String sql = "select id,name from t2"; PreparedStatement ps = conn.prepareStatement(sql); // 4.执行sql语句 ResultSet rs = ps.executeQuery(); // 5.处理结果 while (rs.next()) {
//这部分可以自己发挥写,只要数据对照数据库中的名字就行 System.out.println(rs.getInt("id") + "\t" + MyUDF.evaluate(new Text(rs.getString("name")))); } // 6.释放资源 rs.close(); ps.close(); conn.close(); } }
hive的(ql)hql使用和基于UDF的用法;以及java对hive的远程访问
标签:运行 stop end load data edr 开启 个数 rop 文件中
原文地址:https://www.cnblogs.com/han-guang-xue/p/9897679.html