标签:残差 数通 驱动 驱动器 header use 示例 大量 分割文件
论文详细介绍
通过从脑部MR图像中分割155个神经结构来验证该网络学习3D表示的效率
目标:设计一个高分辨率和紧凑的网络架构来分割体积图像中的精细结构
特点:大多数存在的网络体系结构都遵循完全卷积下行-向上采样路径。具有高空间分辨率的低层次特征首先被下采样用于更高层次的特征抽象;然后对特征图进行上采样,以实现高分辨率分割。本论文提出了一种新的3D架构,它包含了整个层的高空间分辨率特征图,并且可以在广泛的接受领域中进行训练
验证:通过从T1加权MR图像中自动进行脑区分割成155个结构的任务来验证网络,验证了采用蒙特卡罗方法对实验中存在漏失的网络进行采样来对体素水平不确定度估计的可行性
结果:经过训练的网络实现了通用体积图像表示的第一步,为其他体积图像分割任务的迁移学习提供了一个初始模型
3D卷积网络的要素
卷积和扩张卷积
为了使用较小的参数,为所有的卷积选用小的3D卷积核,只拥有3 * 3 * 3 的参数
扩张卷积的优点是特征可以在高空间分辨率下计算,接受域的大小可以任意放大。扩张卷积可以用于产生精确的密集预测和沿着对象边界的详细分割映射
论文提出采用扩张卷积的方法进行体积图像分割:用于进行上采样的卷积核使用膨胀系数r,对于输入特征图I的M通道,在扩张时生成的输出特征通道O为:
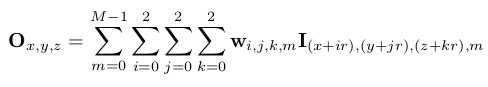
其中,(x,y,z)表示空间位置;w包含33 * M个可训练参数
该扩张卷积拥有3 * 3 * 3的参数,保留了空间分辨率,同时提供了(2r + 1)3的体素接收域
在实现中使用分拆合并策略来实现3D扩张卷积以从GPU受益
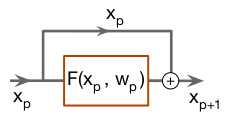
残差连接
残差连接可以使信息传播顺畅,提高训练速度,提高深度网络的效率,关键思想是创建标识映射连接,以绕过网络中的参数化层
示例:
有效的接受域
对于有n个残块的网络有2n个唯一路径的集合,因此,特征可以通过大量不同的接受域来学习
由于深度卷积网络的接受域相对较大,分割映射将避免卷积边界的畸变。进行了实验,证明了所提出的网络在边界附近只产生了很小的失真,畸变边界的宽度远小于最大接受域,因此,在测试时,在每个输入卷中填充一个0的边框,并在分割输出中丢弃相同数量的边框
损失函数
网络的最后一层是softmax函数,它为每个体素的所有标签打分
为处理处理训练数据不平衡的问题,不直接根据类别频率重新加权每个体素,而是使用直接最大化平均骰子系数(mean Dice coefficient)的解决方案
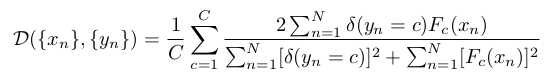
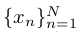 表示N体素的图片向量,C为数据类别数,
表示N体素的图片向量,C为数据类别数,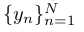 为分割结果,
为分割结果,
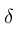 为狄拉克函数(Dirac delta function),Fc(xn)为在C类别中xn的softmax分类得分
为狄拉克函数(Dirac delta function),Fc(xn)为在C类别中xn的softmax分类得分
函数介绍文献
用差值法估计不确定度
预测的不确定性可以用M个样本的样本方差来估计
在最后一个卷积层之前增加一个1 * 1 * 1的卷积层来扩展分割网络。该被扩展的网络被训练时拥有一个带有0.5的dropout比率的新插入的层。在测试时,使用dropout对网络进行N次采样。最后的分割通过多数投票获得。在每个体素上被计算的与投票结果不一致的样本百分比作为不确定性估计
网络架构与实现
体系架构
网络包括20层卷积。前7层使用3 * 3 * 3的体素卷积,这些层用来捕获如边缘、拐角之类的低级图像特征。在随后的卷积层中,内核被放大两到四倍,这些具有扩展内核的深层编码中、高级图像特征。利用残差连接对每两个卷积层进行分组。在每个残块中,每个卷积层都与元素级的ReLU层和批规格化层相关联。ReLU、批规格化和卷积层按预激活顺序排列
架构图
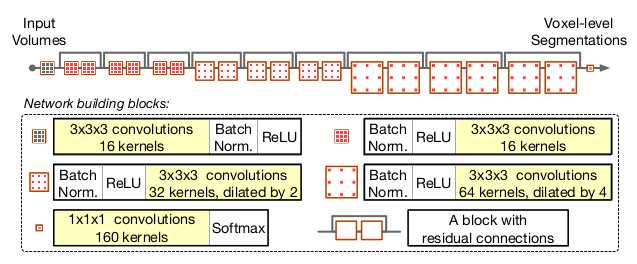
为了在多个尺度上合并特征,当层越深时,膨胀曲的膨胀系数逐渐增大。具有标识映射的残块使不同尺度的特征能够直接融合。在整个网络中保持输入量的空间分辨率
在训练阶段,向网络中输入96 * 96 * 96的体素图像。最终,softmax层为96 * 96 * 96个体素都给出了基于分类标签的分类得分
实现细节
在训练阶段,预处理步骤包括输入数据的标准化以及在图像和子体素水平上的增强。在图像层面,采用基于直方图的尺度标准化方法对强度直方图进行规范化。对随机采样的96 * 96 * 96的子体素的随机拟合
为了做一个公平的比较,我们对所有的方法使用固定超参数的Adam优化方法
学习率设置为0.01,步长(step size)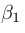 设置为0.9,
设置为0.9,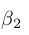 设置为0.999,而对于V-Net选择了训练算法收敛的最大的学习率0.0001
设置为0.999,而对于V-Net选择了训练算法收敛的最大的学习率0.0001
为了获得更好的分割结果,没有添加后处理步骤,而是将重点放在由网络生成的密集分割图上
实验和结果
数据
网络从ADNI数据集中学习543张t1加权MR图像的高粒度分割,每卷的平均体素的为182 * 244 * 246,平均每卷尺寸为1.18mm * 1.05mm * 1.05mm。所有卷都经过偏压校正并重新定向到标准的右前向或上向。采用GIF框架对155个脑结构和5个非脑外部组织进行了青铜(brozen)标准分割。分别随机选择443卷、50卷和50卷进行训练、测试和验证
总体评价
采用平均骰子系数相似度(Dice Coefficient Similarity -- DCS)作为性能指标
输入图片信息
格式为Nifty格式的.gz压缩文件,解压后查看图片信息为:
Header:

Summary:

假定我们已经下载好了demo
使用命令
python net_segment inference -c ~/niftynet/extensions/highres3dnet_brain_parcellation/highres3dnet_config_eval.ini来运行网络
主流程
设置所有模型文件相关参数
设置网络映射文件
设置推断输出文件
设置系统数据分割文件
设置评估文件夹
清理工作
关闭TensorFlow会话
重置图
关闭日志
参考流程
*1 获取用户参数
*2 使用参数初始化应用程序
进入engine.application_driver.py,运行initialise_application(self,workflow_param,data_param)
配置参数通过之前的步骤都存放在了workflow_param和data_param中
设置迭代器
*3 驱动程序调用应用程序运行
**1 运行应用程序
niftynet Demo分析 -- brain_parcellation
标签:残差 数通 驱动 驱动器 header use 示例 大量 分割文件
原文地址:https://www.cnblogs.com/zhhfan/p/9898196.html