标签:利用 roi cascade enter layer local module color 假设
这篇文章比较简单,但还是不想写overview,转自: https://blog.csdn.net/zimenglan_sysu/article/details/52451098
另外,读这篇paper的时候,一直想不明白白一个问题,就是他分出了\(k^2\)个Instance-sensitive score maps,他是怎么训练的。。换句话说,ground truth是怎么弄的? 文章里只说了用logistics做损失函数,应该需要看代码,因为还没有搞分割的打算,先不详细了解代码。
Instance-sensitive Fully Convolutional Networks - eccv 2016
=====
论文地址:http://arxiv.org/abs/1603.08678
=====
一句话概括:
根据local coherence的特性,以sliding window的方式,利用FCN产生positive-sensitive的instance-level的segment proposal。
=====
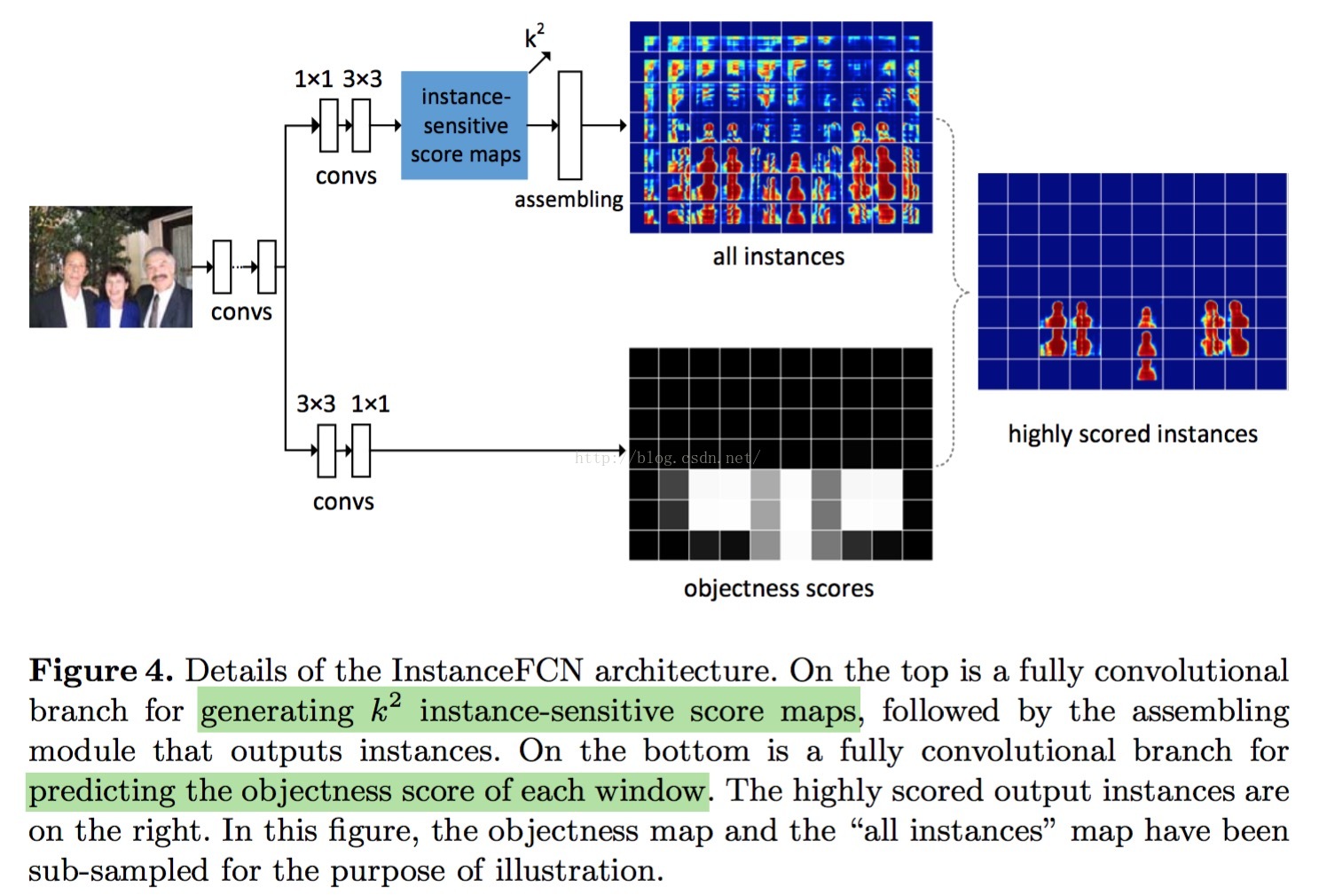
framework
从上图可以看出,该network是一个full convolutional network(based on VGG16),除了feature extractor(VGG16的前13个conv layers)外,还有两个branches:
1 segment branch
该branch由1*1 conv,3*3 conv和一个assembling layer构成,后接segment的loss layer(采用logistic regression layer)
2 scoring branch
该branch由3*3 conv,1*1 conv构成,后接一个scoring的loss layer(采用logistic regression layer)
显然segment branch产生instance-level的segmentation mask,scoring branch对segment branch产生的instance mask进行打分。
(这里为objectness score,有点不明白为什么不是class-specific的)。
剩下的network architecture(VGG16-base)见下图:
论文采用了hole algorithm来获取dense的feature map同时保持和原来VGG16的感受野大小。
=====
key module - assembling module
论文中的network(如上所述)是比较容易理解的,除了segment branch的assembling module。
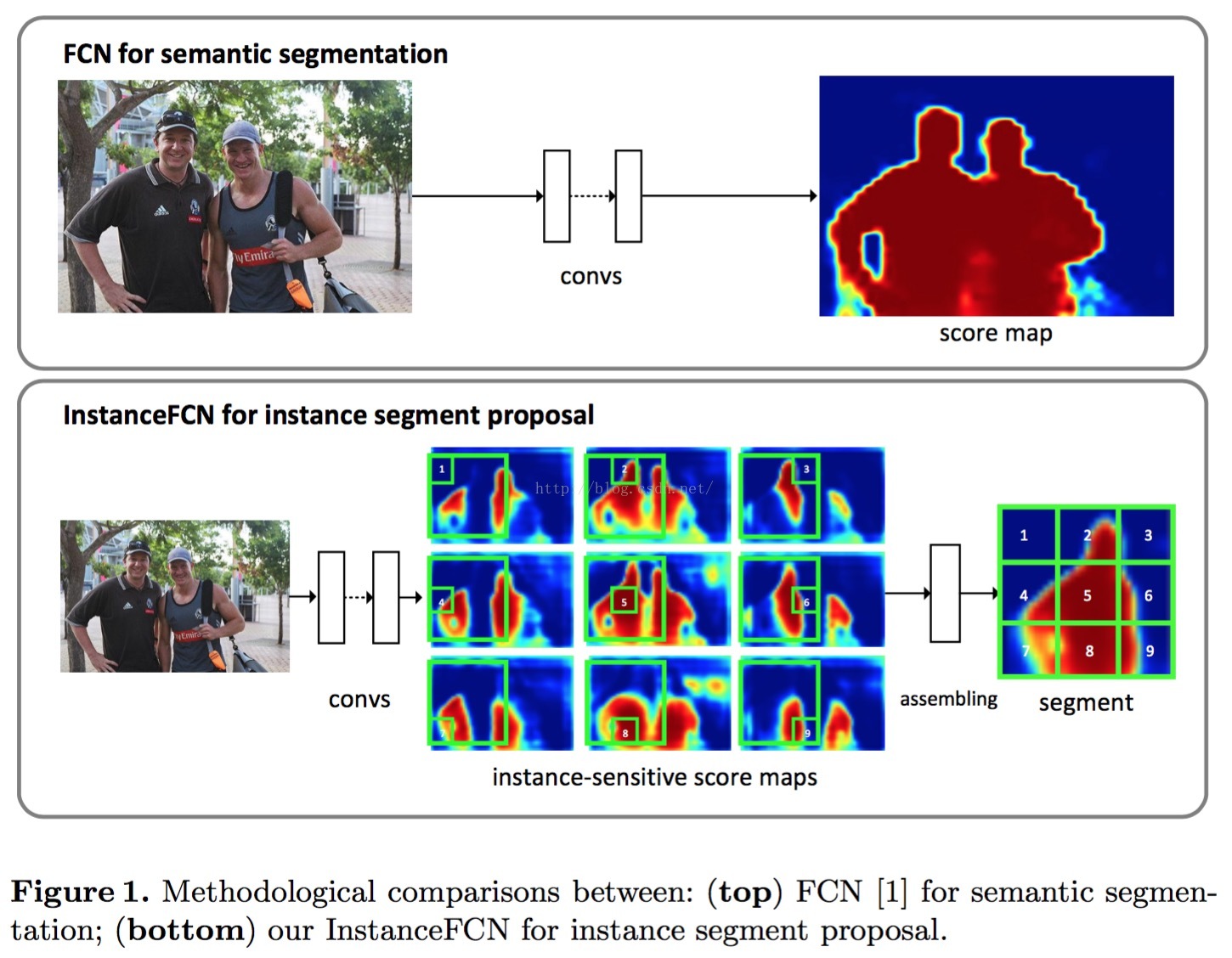
先上图来个感性认识
从上述三张图可以看出assembling module是如何工作的了,具体来说:
1 理解k^2 feature maps
由segment branch产生k^2个feature maps(或者理解为predicted masks),
这k^2 feature map编码了不同的位置信息,如top-left,top-center,……,bottom-right。
也就是每个feature map对应一个位置。
2 assembling -> producing instance-level mask
假如给定一个bounding box M(m*m大小),那么就可以将bounding box投影到k^2个feature map。
(类似RoIPooling)
将bounding box划分为k*k个bin,每个bin的大小为(m/k,m/k),
同理,bounding box投影到的feature map上的投影bounding boxes的
每个bounding box N_i (i=1,2, ...., k^2)也划分为k*k个bins。
这样M的每个bin K对应到第K个feature map上的N_k的bin K(刚好都是k^2)
那么对应的instance-level mask的输出为:同样为m*m大小,同样划分为k*k个bins
将第K个feature map上的N_k的bin K的feature values,拷贝到输出对应的bin K上。
(反向传播时,就是将对应的diff反过来拷贝过来就好)
说的有点绕口,但是它就是这么简单。
这里的输入bounding box并不是由proposal method产生的,而是论文作者以sliding window的方式
和指定bounding box的大小来产生的:
1 假设k^2的feature maps的大小为h和w,(同样对应的scoring branch的score map的大小也是h和w)
2 feature map上的每个pixel都产生一个bounding box,其大小为m*m,(论文里m=21)
3 每个pixel根据该bounding box
(已经是投影再feature map上的bounding box了,这个需要注意,而不是再从原图投影到feature map上),
输入其的instance-level的mask
4 这里的每个instance-level mask(一共w*h个)都由一个对应的objectness score,由scoring branch的score map给出
需要注意的是这里的w和h由个隐性的约束条件:h>=m, w>=m
=====
training & testing
那么论文是怎么training和testing的?还是直接看图(笔者直接截出来的)
=====
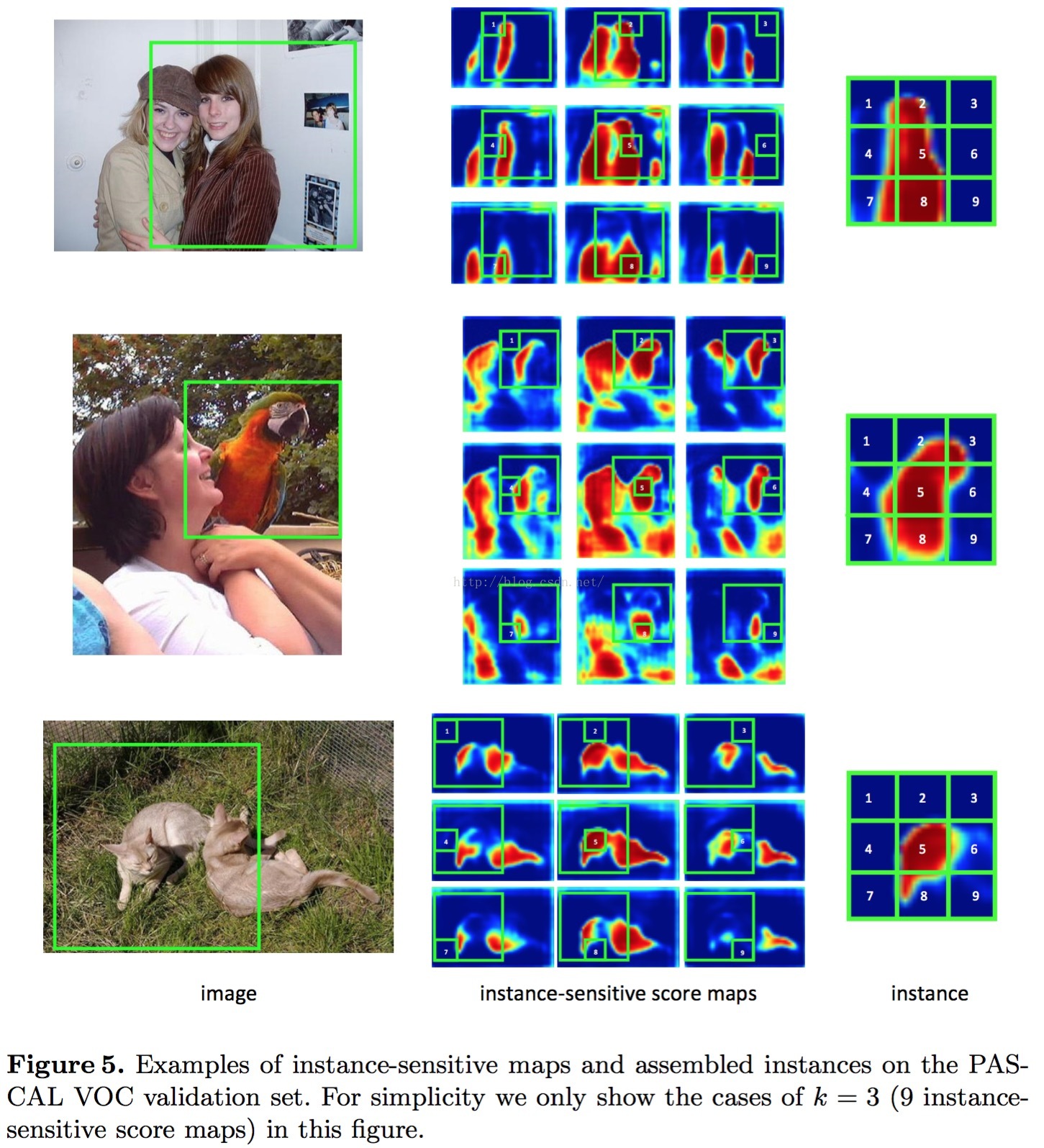
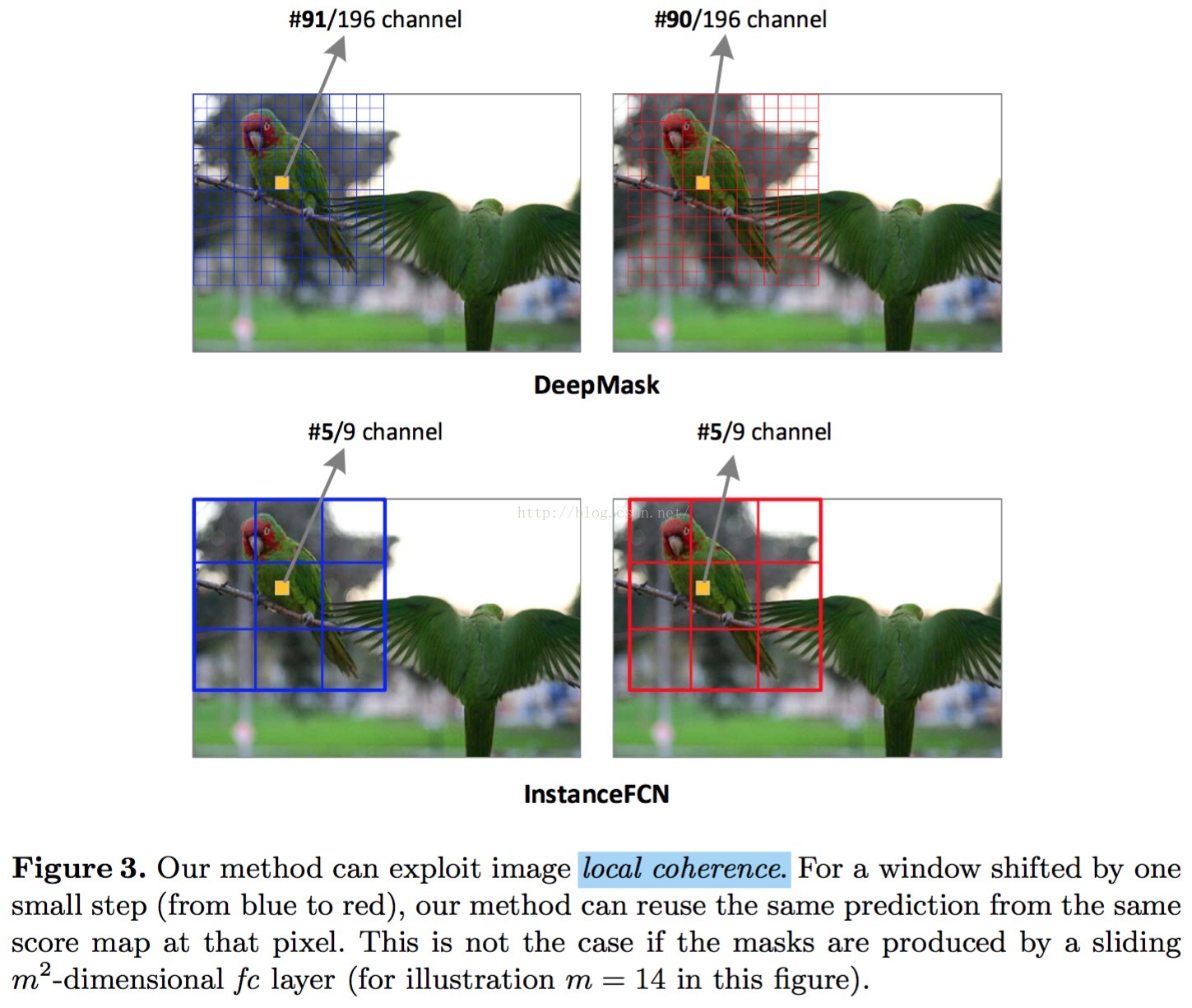
local coherence
嗯,直接看图,不说话
=====
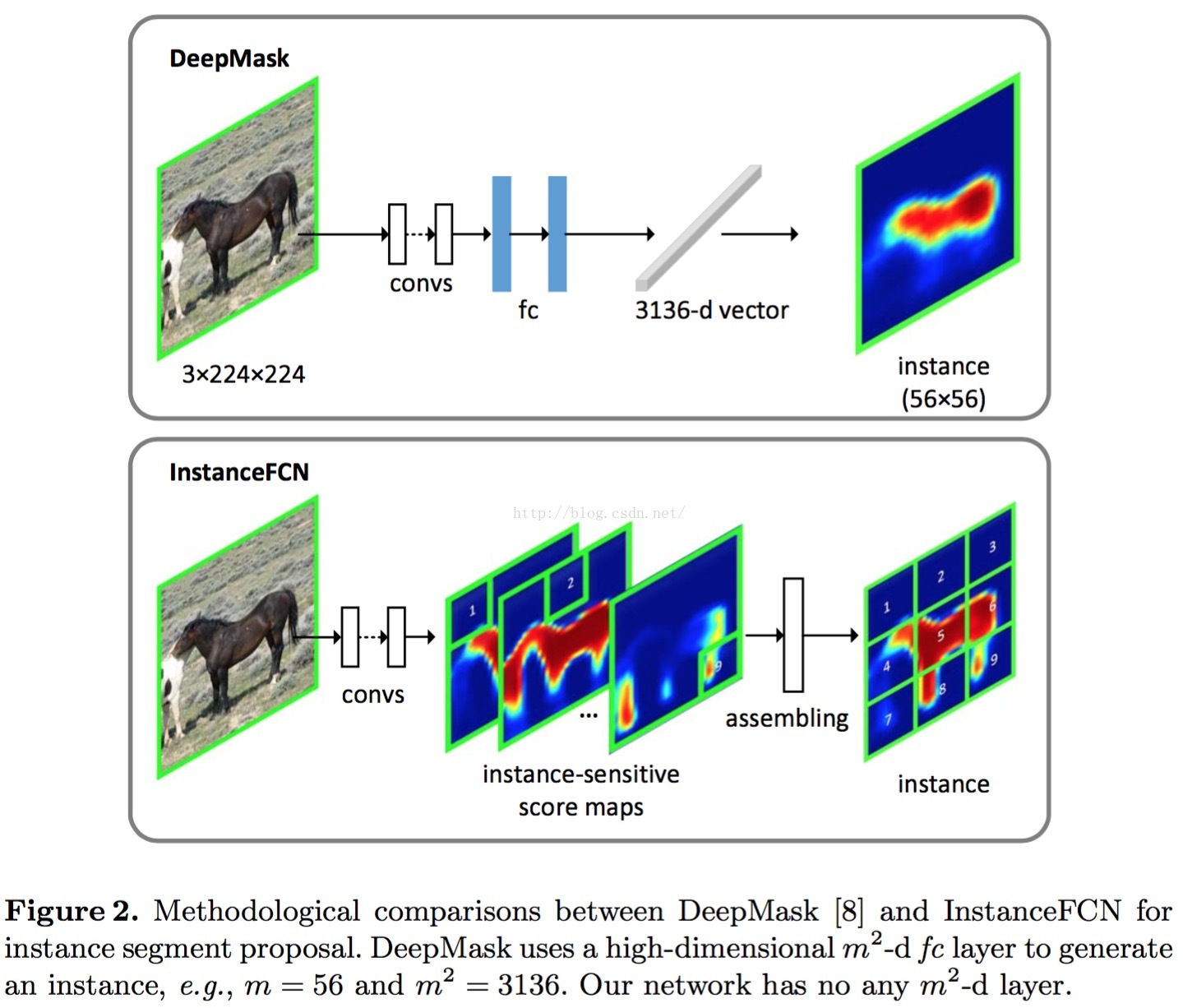
与deepmask的对比
这个嘛,上面的local coherence已经说的很明白了,具体的请各位客官各自看论文和deepmask的论文
=====
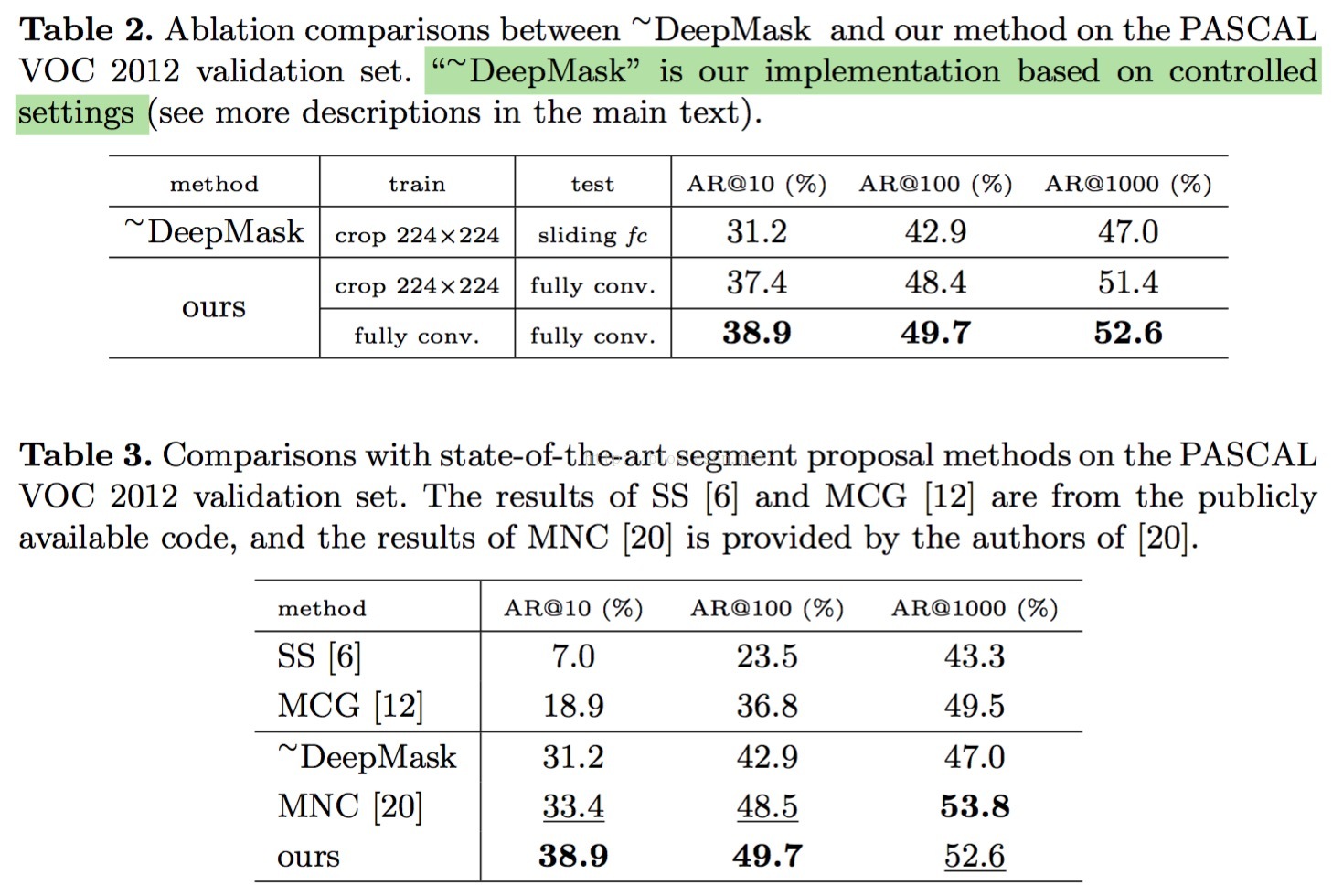
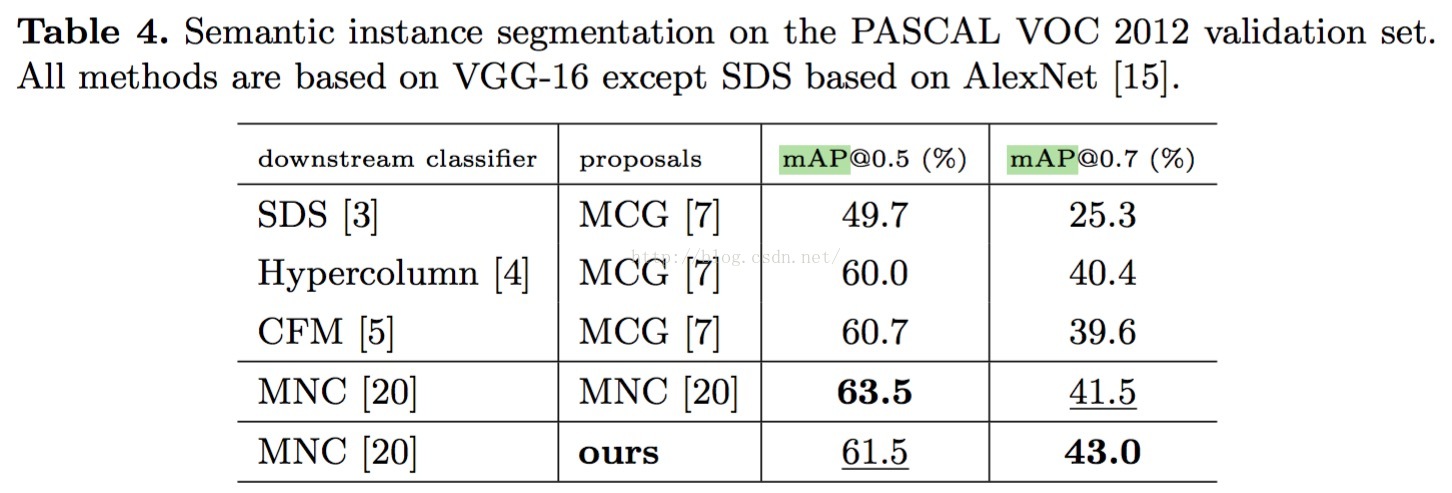
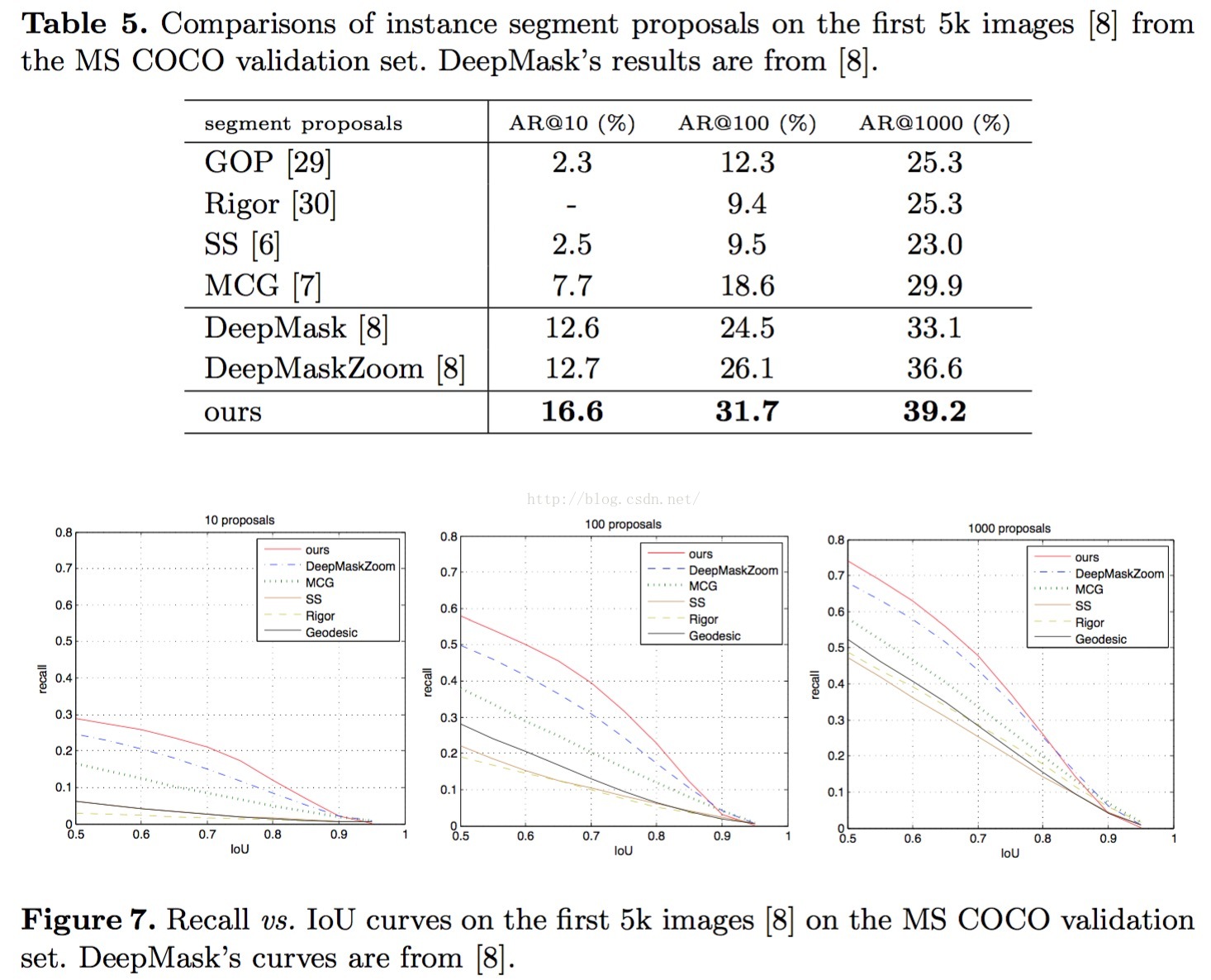
实验效果
嗯,直接看图,不说话
=====
总的来说,
整篇论文的思路很简单,但是效果就是好,复现也容易(但是,笔者还是坐等论文作者开源)
但是笔者有几处不是很明了,不知道哪位客官可以解答下:
1 branches的conv layer设计,为什么segment branch的为1*1,3*3,而scoring branch为3*3,1*1,为什么这样设计?
2 scoring branch的score为什么不是class-specific的而是objectness?
3 为什么不用proposal method的方式来产生bounding boxes?
4 训练segment branch时,是如何为每个predicted instance-level的mask分配对应的ground-truth?
5 为什么不用在论文作者的另外一篇论文上:Instance-aware Semantic Segmentation via Multi-task Network Cascades
笔者在此多谢喇!
欢迎前来探讨!

=====
如果这篇博文对你有帮助,可否赏笔者喝杯奶茶?
【Semantic Segmentation】 Instance-sensitive Fully Convolutional Networks论文解析
标签:利用 roi cascade enter layer local module color 假设
原文地址:https://www.cnblogs.com/kk17/p/9899170.html