标签:time_wait print cat slave pen 资源 9.png soft 远程服务器
以后要在项目中使用Spark 用户昵称文本做一下聚类分析,找出一些违规的昵称信息。以前折腾过Hadoop,于是看了下Spark官网的文档以及 github 上 官方提供的examples,看完了之后决定动手跑一个文本聚类的demo,于是有了下文。
本地开发环境是:IDEA2018、JDK8、windows 10。远程服务器 Ubuntu 16.04.3 LTS上安装了spark-2.3.1-bin-hadoop2.7
看spark官网介绍,有两种形式(不是Spark Application Execution Mode)来启动spark
Running the Examples and Shell
比如说./bin/pyspark --master local[2]启动的是一个交互式的命令行界面,可以在4040端口查看作业。
Launching on a Cluster
spark 集群,有多种部署选项:Standalone。另外还有:YARN,Mesos(将集群中的资源将由资源管理器来管理)。
对于Standalone,./sbin/start-master.sh 启动Master,通过8080端口就能看到:集群的情况。
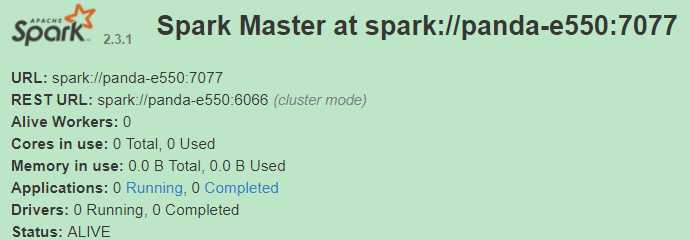
再通过./sbin/start-slave.sh spark://panda-e550:7077 启动slave:Alive Workers 就是启动的slave。
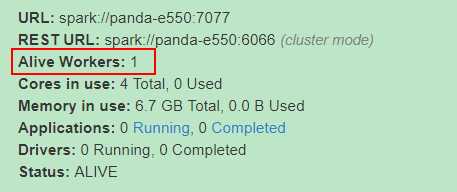
执行jps:看到Master和Worker:
~/spark-2.3.1-bin-hadoop2.7$ jps
45437 Master
50429 Worker
下面介绍一下在本地windows10 环境下写Spark程序,然后连接到远程的这台Ubuntu机器上的Spark上进行调试。
创建Maven工程,根据官网提供的Spark Examples 来演示聚类算法(JavaBisectingKMeansExample )的运行过程,并介绍如何配置Spark调试环境。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.3.1</version>
<!--<scope>runtime</scope>-->
</dependency>package net.hapjin.spark;
import org.apache.spark.ml.clustering.BisectingKMeans;
import org.apache.spark.ml.clustering.BisectingKMeansModel;
import org.apache.spark.ml.linalg.Vector;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class JavaBisectingKMeansExample {
public static void main(String[] args) {
// SparkSession spark = SparkSession.builder().appName("JavaBisectingKMeansExample").getOrCreate();
SparkSession spark = SparkSession.builder().appName("JavaBisectingKMeansExample").master("spark://xx.xx.129.170:7077").getOrCreate();
// Dataset<Row> dataset = spark.read().format("libsvm").load(".\\data\\sample_kmeans_data.txt");
Dataset<Row> dataset = spark.read().format("libsvm").load("hdfs://172.25.129.170:9000/user/panda/sample_kmeans_data.txt");
// Dataset<Row> dataset = spark.read().format("libsvm").load("file:///E:/git/myown/test/spark/example/data/sample_kmeans_data.txt");
// Trains a bisecting k-means model.
BisectingKMeans bkm = new BisectingKMeans().setK(2).setSeed(1);
BisectingKMeansModel model = bkm.fit(dataset);
// Evaluate clustering.
double cost = model.computeCost(dataset);
System.out.println("Within Set Sum of Squared Errors = " + cost);
// Shows the result.
System.out.println("Cluster Centers: ");
Vector[] centers = model.clusterCenters();
for (Vector center : centers) {
System.out.println(center);
}
// $example off$
spark.stop();
}
}
在IDEA中,"Run"-->"Edit Configurations"-->"Template"--->"Remote",点击 "+"号:
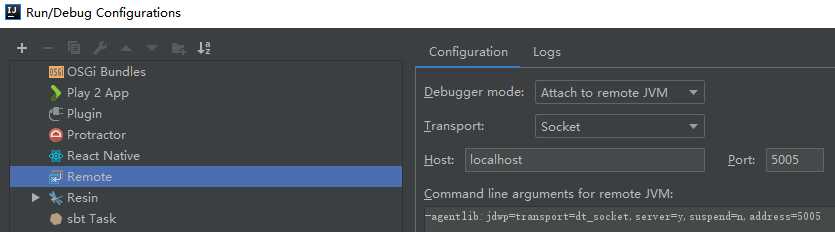
报错:
Could not locate executable null\bin\winutils.exe
去这个github下载对应的Hadoop版本的winutils.exe。
配置windows10环境变量:HADOOP_HOME,并将该环境变量添加到 Path 环境变量下%HADOOP_HOME%\bin。
再次Debug调试,成功进入断点:(如果报拒绝连接的错误,修改一下 conf/spark-env.sh 指定SPARK_LOCAL_IP为机器的IP地址,然后再 修改 /etc/hosts 文件 将主机名与机器IP地址相对应即可)
但是到后面执行读取文件时,明明文件就在windows的该路径下,但是就是报错:
Caused by: java.io.FileNotFoundException: File file:/E:/git/myown/test/spark/example/data/sample_kmeans_data.txt does not exist
尝试了好几个路径写法,比如这篇stackoverflow,都未果。
// Dataset<Row> dataset = spark.read().format("libsvm").load(".\\data\\sample_kmeans_data.txt");
Dataset<Row> dataset = spark.read().format("libsvm").load("file:///E:\\git\\myown\\test\\spark\\example\\data\\sample_kmeans_data.txt");
// Dataset<Row> dataset = spark.read().format("libsvm").load("file:///E:/git/myown/test/spark/example/data/sample_kmeans_data.txt");看里面的解释:
SparkContext.textFile internally calls
org.apache.hadoop.mapred.FileInputFormat.getSplits, which in turn usesorg.apache.hadoop.fs.getDefaultUriif schema is absent. This method reads "fs.defaultFS" parameter of Hadoop conf. If you set HADOOP_CONF_DIR environment variable, the parameter is usually set as "hdfs://..."; otherwise "file://".
因为我本地Windows10没有安装Hadoop,只是上面提到的下载winutils.exe时,简单地配置了个 HADOOP_HOME环境变量。所以我也不知道这种远程调试中读取本地windows系统上的文件是否可行了。
看来,我只能在远程服务器上再安装个Hadoop了,然后把文件上传到HDFS上。于是,下载Hadoop-2.7.7,解压安装(按照官网 伪分布式模式配置安装),并启动HDFS:
$ sbin/start-dfs.shjps查看当前服务器上的进程:
panda@panda-e550:~/data/spark$ jps
2435 Master
10181 SecondaryNameNode
11543 Jps
9849 NameNode
3321 Worker
9997 DataNode
其中Master是Spark master;Worker是spark worker;NameNode、DataNode、SecondaryNameNode是Hadoop HDFS的相关进程。把文件上传到HDFS上:
panda@panda-e550:~/software/hadoop-2.7.7$ ./bin/hdfs dfs -ls /user/panda
Found 2 items
-rw-r--r-- 1 panda supergroup 70 2018-10-30 17:54 /user/panda/people.json
-rw-r--r-- 1 panda supergroup 120 2018-10-30 18:09 /user/panda/sample_kmeans_data.txt
修改一下代码中文件的路径:(还是隐藏一下具体的ip吧)
Dataset<Row> dataset = spark.read().format("libsvm").load("hdfs://xx.xx.129.170:9000/user/panda/sample_kmeans_data.txt");
继续右击debug,又报错:
failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
按照提示的链接看:应该是下面这个问题。
- If the error message says the remote service is on "127.0.0.1" or "localhost" that means the configuration file is telling the client that the service is on the local server. If your client is trying to talk to a remote system, then your configuration is broken.
- Check that there isn‘t an entry for your hostname mapped to 127.0.0.1 or 127.0.1.1 in
/etc/hosts(Ubuntu is notorious for this)
cat /etc/hosts 部分内容如下:
127.0.0.1 localhost
172.25.129.170 panda-e550
再看看 hdfs上的配置文件:cat etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>在远程服务器上:
panda@panda-e550:~/software/hadoop-2.7.7$ netstat -anp | grep 9000
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 9849/java
tcp 0 0 127.0.0.1:43162 127.0.0.1:9000 ESTABLISHED 9997/java
tcp 0 0 127.0.0.1:43360 127.0.0.1:9000 TIME_WAIT -
tcp 0 0 127.0.0.1:9000 127.0.0.1:43162 ESTABLISHED 9849/java
因此,出现ConnectException的原因就很明显了。因此,服务器Hadoop HDFS 9000端口绑定在到环回地址上。那我在windows10上的机器上的IDEA的代码程序里面指定:hdfs://172.25.129.170:9000/user/panda/sample_kmeans_data.txt肯定是不行的了。毕竟windows10开发环境机器的ip地址,肯定和安装Hadoop的远程服务器的ip地址是不同的。
由于core-site.xml配置的是hdfs://localhost:9000,按理说,把 localhost 改成 ip 地址应该是可以的。但是我采用另一种方案,修改 /etc/hosts中的文件:把原来的127.0.0.1对应的localhost注释掉,修改成机器的ip地址,如下:
panda@panda-e550:~/software/hadoop-2.7.7$ cat /etc/hosts
# comment this line and add new line for hadoop hdfs
#127.0.0.1 localhost
172.25.129.170 localhost然后再重启一下 HDFS进程。此时:
panda@panda-e550:~/software/hadoop-2.7.7$ netstat -anp | grep 9000
tcp 0 0 172.25.129.170:9000 0.0.0.0:* LISTEN 13126/java
tcp 0 0 172.25.129.170:50522 172.25.129.170:9000 ESTABLISHED 13276/java
tcp 0 0 172.25.129.170:50616 172.25.129.170:9000 TIME_WAIT -
tcp 0 0 172.25.129.170:9000 172.25.129.170:50522 ESTABLISHED 13126/java
在windows10 机器的cmd命令行上telnet 一下:发现能成功连接上。因此可以放心debug了。
C:\Users\Administrator.000>telnet 172.25.129.170 9000
最终,整个远程调试完整跑通:
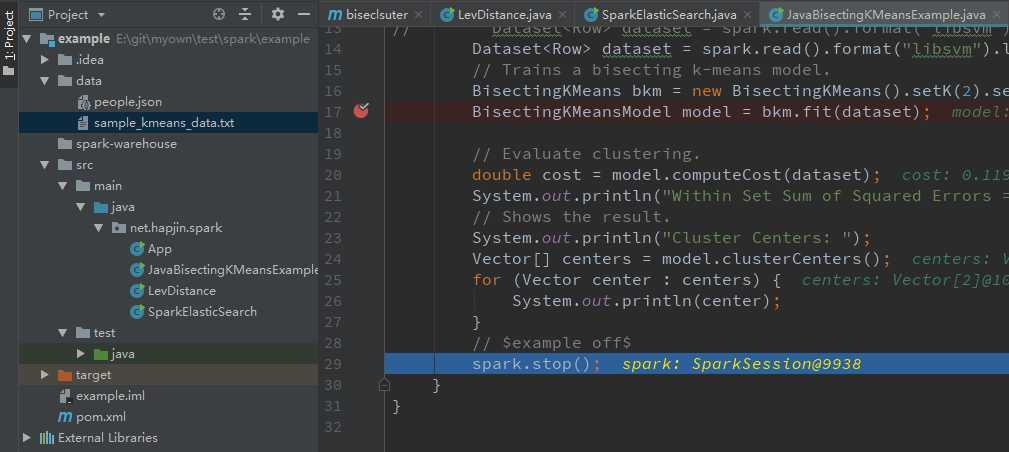
程序输出:
Within Set Sum of Squared Errors = 0.11999999999994547
Cluster Centers:
[0.1,0.1,0.1]
汇总一下: 启动spark master 和 slave命令。
./sbin/start-master.sh
./sbin/start-slave.sh spark://panda-e550:7077
http://172.25.129.170:8080/ 查看spark管理界面
启动hdfs命令(伪分布式)
./sbin/start-dfs.sh
在知乎上看到一个问题:如何更有效地学习开源项目的代码?,放到这里供大家参考一下。
原文:https://www.cnblogs.com/hapjin/p/9879002.html
标签:time_wait print cat slave pen 资源 9.png soft 远程服务器
原文地址:https://www.cnblogs.com/hapjin/p/9879002.html
{kind=link}