标签:png 最大 io操作 了解 字符 深度 adb html htm
目录
很久以前在网上看到一篇叫做《如何给老婆解释什么是RPC》的文章,给我留下了深刻的印象,文章生动有趣,让技术不那么乏味。最近在看很多新的东西,我也想按照这一风格推出一个《如何向女朋友介绍**》系列的文章,因为我也是一个小白,文章中难免会有错误或者疏漏,还请大家多多指点。
又是一个难得的周末,起床困难户的我刚刚翻开我的《高性能MySQL》,女朋友好奇的凑了过来。
大小姐:一直听你们程序员说索引索引,到底那是什么东西?
我:索引(在MySQL中也叫做“键(key)”)是存储引擎用于快速找到记录的一种数据结构。
大小姐:停停停,能不能说得通俗一点?术语听不懂。
我:emmmm,通俗一点说,索引就是类似与书籍的目录一样,可以通过书籍的目录快速定位到对应的页码。
大小姐:目录?太通俗了,说了和没说一样。
我:果然女生都是泡椒凤爪~~,好吧,那我用既通俗又专业的例子来给你解释吧。
索引有很多类型,常见的有B-Tree,哈希索引,数据空间索引,全文索引等,可以为不同场景提供更好的性能,不同的数据库也可能使用不同类型的索引,本文主要介绍MySQL主要的索引B-Tree和B+Tree,在程序员小哥哥们讨论索引的时候,如果没有特别指明类型,那么多半是在说B-Tree。
因为待会主要讲的是B-Tree和B+Tree,所以我们来简单回顾一下常见动态查找树有:二叉查找树(Binary Search Tree),平衡二叉查找树(Balanced Binary Search Tree),红黑树 (Red-Black Tree ),B-tree/B+-tree/ B*-tree(B~Tree)。
二叉树因为其树的深度过大造成磁盘I/O读写过于频繁,导致查询效率低下,所以一般不用来作为索引的数据结构,那么减少树的深度就要考虑多叉树的结构,例如B-Tree等。
具体的二叉树和磁盘I/O相关知识在这里不再描述。
念BTree,而不是B减Tree,上次分享会被导师纠正了,呜呜,怪自己理所当然的以为有+就有-,无地自容~~
B-tree又叫平衡多路查找树,一棵m阶的B-tree (m叉树)的特性如下:
1、树中每个结点至多有m个孩子;
2、除根结点和叶子结点外,其它每个结点至少有有ceil(m / 2)个孩子(其中ceil(x)是一个取上限的函数);
3、若根结点不是叶子结点,则至少有2个孩子;
4、关键字的个数n必须满足: ceil(m / 2)-1 <= n <= m-1
这些特征暂时记不住也没有关系,接下来的例子中会有用到。
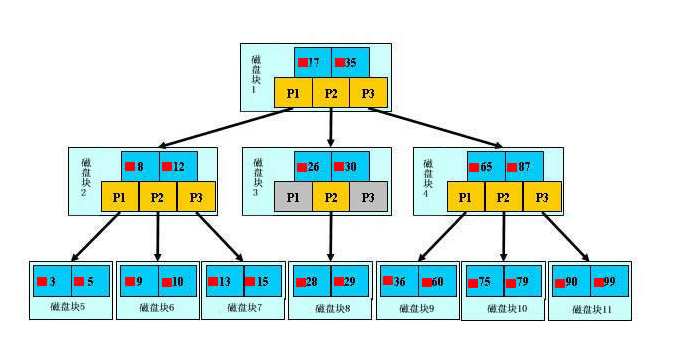
如图中:
17表示一个磁盘文件名也就是关键字,红方块表示17这个文件在硬盘中的存储位置,P1表示17左子树的指针
模拟查找文件29的过程:
(1) 根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作1次】
(2) 此时内存中有两个文件名17,35和三个存储其他磁盘页面地址的数据。根据算法我们发现17<29<35,因此我们找到指针p2。
(3) 根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作2次】
(4) 此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现26<29<30,因此我们找到指针p2。
(5) 根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作3次】
(6) 此时内存中有两个文件名28,29。根据算法我们查找到文件29,并定位了该文件内存的磁盘地址。
首先有一个5阶空树,然后插入以下字符字母到空的5阶B-tree中:C N G A H E K Q M F W L T Z D P R X Y S
特征1:树中每个结点至多有m个孩子;
特征4:关键字的个数n必须满足: ceil(m / 2)-1 <= n <= m-1
B-Tree中的数据是有序排列的,所以5阶树最多有5个孩子和4个关键字,先插入前四个单词
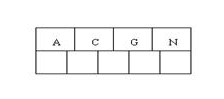
当咱们试着插入H时,结点发现空间不够,以致将其分裂成2个结点,移动中间元素G上移到新的根结点中,在实现过程中,咱们把A和C留在当前结点中,而H和N放置新的其右邻居结点中。如下图:
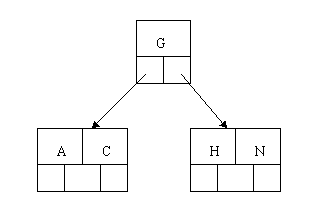
当咱们插入E,K,Q时,不需要任何分裂操作
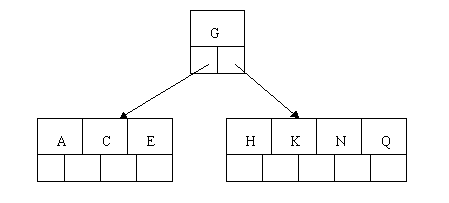
插入M需要一次分裂,注意M恰好是中间关键字元素,以致向上移到父节点中
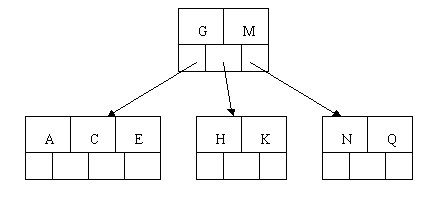
插入F,W,L,T不需要任何分裂操作
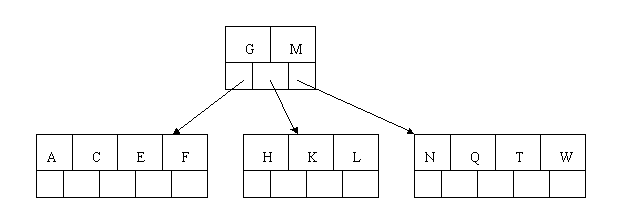
插入Z时,最右的叶子结点空间满了,需要进行分裂操作,中间元素T上移到父节点中,注意通过上移中间元素,树最终还是保持平衡,分裂结果的结点存在2个关键字元素。
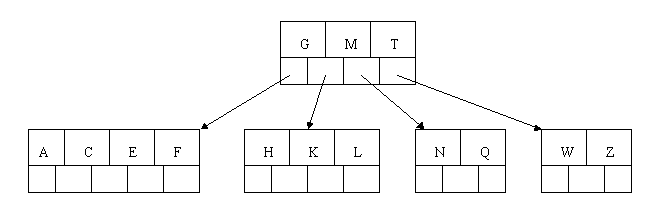
插入D时,导致最左边的叶子结点被分裂,D恰好也是中间元素,上移到父节点中,然后字母P,R,X,Y陆续插入不需要任何分裂操作。
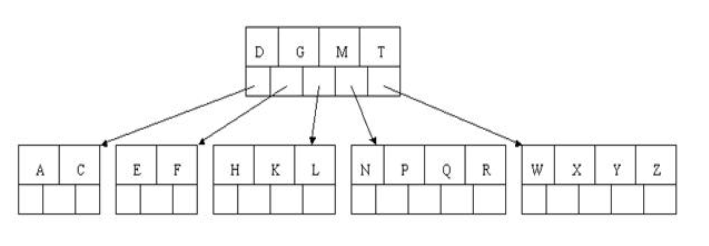
最后,当插入S时,含有N,P,Q,R的结点需要分裂,把中间元素Q上移到父节点中,但是情况来了,父节点中空间已经满了,所以也要进行分裂,将父节点中的中间元素M上移到新形成的根结点中,注意以前在父节点中的第三个指针在修改后包括D和G节点中。这样具体插入操作的完成,下面介绍删除操作,删除操作相对于插入操作要考虑的情况多点。
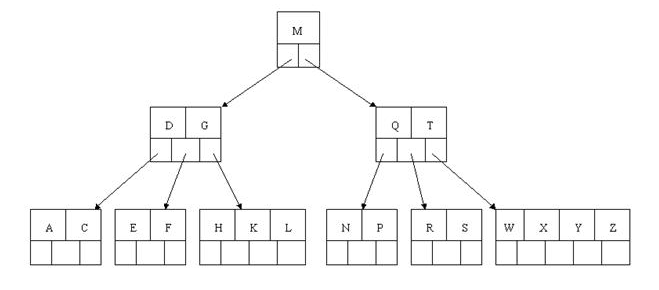
针对上面构造的树,依次删除H,T,R,E
首先删除元素H,当然首先查找H,H在一个叶子结点中,且该叶子结点元素数目3大于最小元素数目ceil(m/2)-1=2,则操作很简单,咱们只需要移动K至原来H的位置,移动L至K的位置(也就是结点中删除元素后面的元素向前移动)
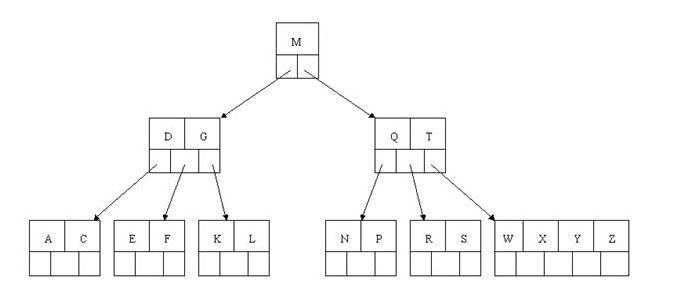
下一步,删除T,因为T没有在叶子结点中,而是在中间结点中找到,咱们发现他的继承者W(字母升序的下个元素),将W上移到T的位置,然后将原包含W的孩子结点中的W进行删除,这里恰好删除W后,该孩子结点中元素个数大于2,无需进行合并操作。
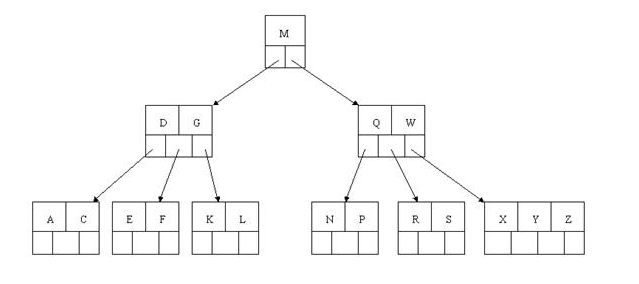
下一步删除R,R在叶子结点中,但是该结点中元素数目为2,删除导致只有1个元素,已经小于最小元素数目ceil(5/2)-1=2,如果其某个相邻兄弟结点中比较丰满(元素个数大于ceil(5/2)-1=2),则可以向父结点借一个元素,然后将最丰满的相邻兄弟结点中上移最后或最前一个元素到父节点中,在这个实例中,右相邻兄弟结点中比较丰满(3个元素大于2),所以先向父节点借一个元素W下移到该叶子结点中,代替原来S的位置,S前移;然后X在相邻右兄弟结点中上移到父结点中,最后在相邻右兄弟结点中删除X,后面元素前移。
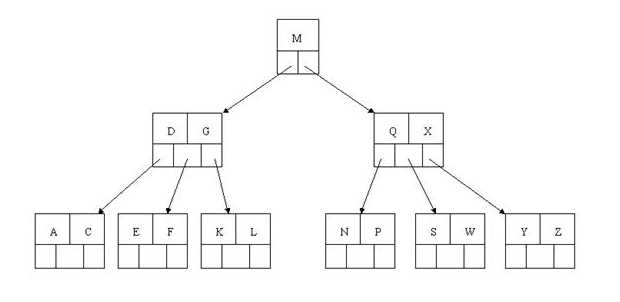
最后一步删除E,删除后会导致很多问题,因为E所在的结点数目刚好达标,刚好满足最小元素个数(ceil(5/2)-1=2),而相邻的兄弟结点也是同样的情况,删除一个元素都不能满足条件,所以需要该节点与某相邻兄弟结点进行合并操作;首先移动父结点中的元素(该元素在两个需要合并的两个结点元素之间)下移到其子结点中,然后将这两个结点进行合并成一个结点。所以在该实例中,咱们首先将父节点中的元素D下移到已经删除E而只有F的结点中,然后将含有D和F的结点和含有A,C的相邻兄弟结点进行合并成一个结点。
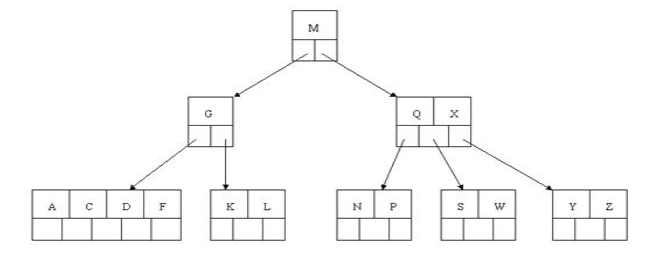
也许你认为这样删除操作已经结束了,其实不然,在看看上图,对于这种特殊情况,你立即会发现父节点只包含一个元素G,没达标,这是不能够接受的。如果这个问题结点的相邻兄弟比较丰满,则可以向父结点借一个元素。假设这时右兄弟结点(含有Q,X)有一个以上的元素(Q右边还有元素),然后咱们将M下移到元素很少的子结点中,将Q上移到M的位置,这时,Q的左子树将变成M的右子树,也就是含有N,P结点被依附在M的右指针上。所以在这个实例中,咱们没有办法去借一个元素,只能与兄弟结点进行合并成一个结点,而根结点中的唯一元素M下移到子结点,这样,树的高度减少一层。
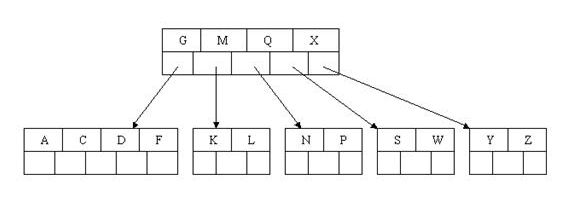
1、有m个子树的节点包含有m个元素(B-Tree中是m-1)
2、根节点和分支节点中不保存数据,只用于索引,所有数据都保存在叶子节点中。(B-Tree节点会保存)
3、所有分支节点和根节点都同时存在于子节点中,在子节点元素中是最大或者最小的元素。(B-Tree只保存儿子的指针)
4、叶子节点会包含所有的关键字,以及指向数据记录的指针,并且叶子节点本身是根据关键字的大小从小到大顺序链接。(B-Tree叶子节点不会保存所以关键字)
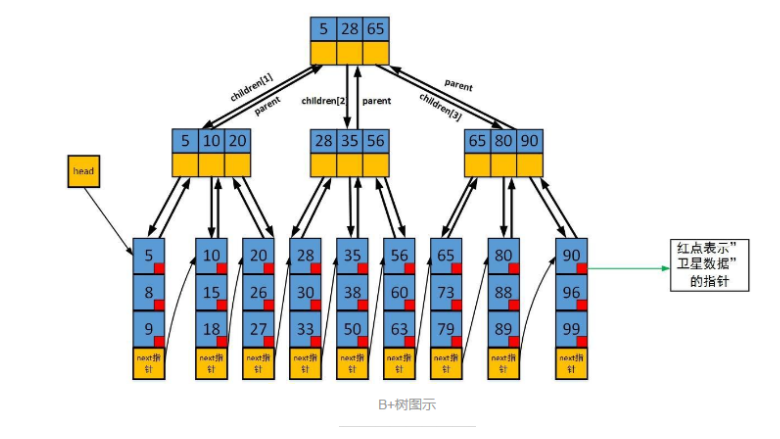
1、红点表示是指向卫星数据的指针,指针指向的是存放实际数据的磁盘页,卫星数据就是数据库中一条数据记录。
2、叶子节点中还有一个指向下一个叶子节点的next指针,所以叶子节点形成了一个有序的链表,方便遍历B+树。
叶子节点形成有顺链表,范围查找性能更优,和B-Tree对比
B树范围查找3-8的过程
a、先查找3
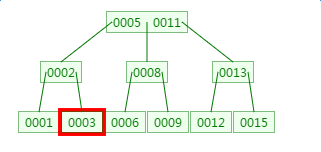
b、再分别查找4、5、6、7、8,中间过程省略,直接到8的查找
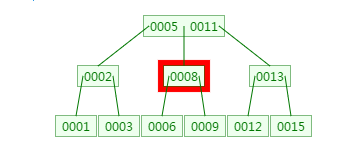
这里查找的范围跨度越大,则磁盘IO的次数越多,性能越差。
B+树范围查找3-11的过程
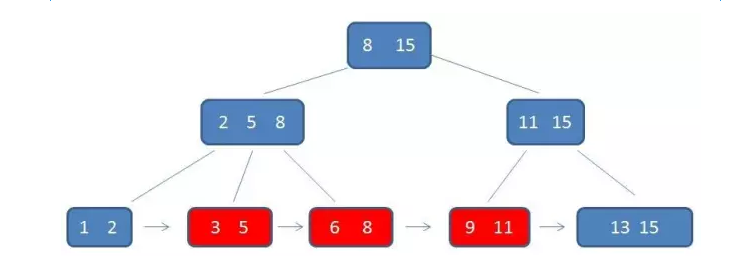
先从上到下找到下限元素3,然后通过链表指针,依次遍历得到元素5/6/8/9/11;如此一来,就不用像B树那样一个个元素进行查找。
还没听完的大小姐已经呼呼睡着了,其实关于MySQL索引相关的资料在网上都很丰富,我也是截取一些讲的比较深入浅出的资料整理了一下,很多原理在工作中并没有运用到,所以感觉学起来很枯燥,其实我们不一定要都记下来,而是在脑中建立一个“索引”,等哪天系统出现了一些业务上无法解决问题,我们了解一些底层,可以快速定位到所需要的知识,这才是最重要的。
《高性能MySQL》
《详解B+tree以及mysql的索引原理 一》https://blog.csdn.net/csdnxingyuntian/article/details/57540650
《什么是B+Tree》https://www.cnblogs.com/dongguacai/p/7241860.html
标签:png 最大 io操作 了解 字符 深度 adb html htm
原文地址:https://www.cnblogs.com/tomxin7/p/9901251.html