标签:iss ict 严格 hunk **kwargs clean .com rmi str
import hdfs
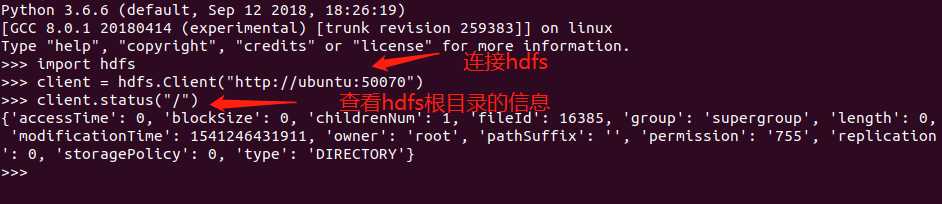
# 1.如何连接hadoop上的hdfs
‘‘‘
参数:
def __init__(self, url, root=None, proxy=None, timeout=None, session=None):
url:这里的url就是我们在浏览器查看hdfs时的连接,也就是ip:端口
root:指定hdfs的根目录
proxy:指定用户的登录身份
timeout:设定的超时时间
session:requests模块里面的session类的实例,用来发出请求
‘‘‘
client = hdfs.Client("http://ubuntu:50070")
# 2.查看路径的具体信息
‘‘‘
参数:
def status(self, hdfs_path, strict=True):
hdfs_path:路径,这里我们指定/,也就是根目录
strict:严格模式,默认为True,表示路径不存在就会抛出异常,为False路径不存在则返回None
‘‘‘
client.status(hdfs_path="/")
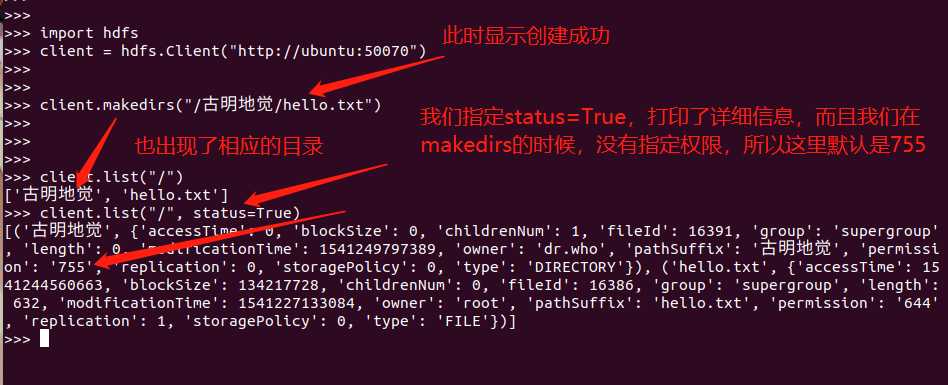
# 3.查看指定目录里的文件或目录
‘‘‘
参数:
def list(self, hdfs_path, status=False):
hdfs_path:路径
status:默认为False,如果为True,则不仅显示有哪些文件或目录,还显示具体的信息
‘‘‘
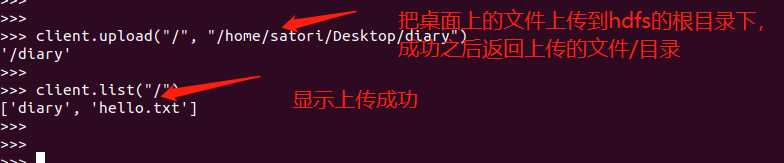
client.list("/")
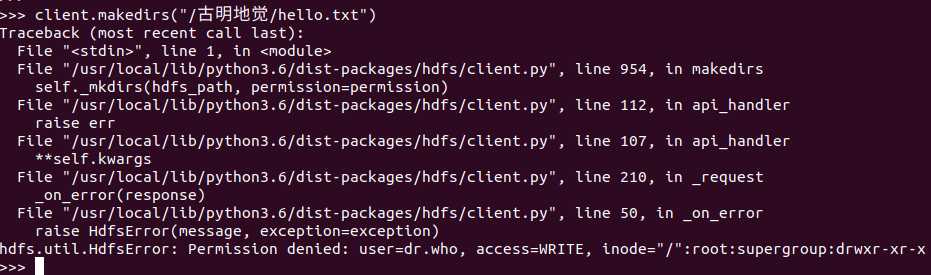
# 4.创建目录
‘‘‘
参数:
def makedirs(self, hdfs_path, permission=None):
hdfs_path:创建的目录,值得一提的是,这个是可以递归创建的
permission:设置权限,比如777,可读可写可执行
‘‘‘
client.makedirs("/古明地觉/hello.txt")
# 5.重命名
‘‘‘
参数:
def rename(self, hdfs_src_path, hdfs_dst_path):
hdfs_src_path:源文件
hdfs_dst_path:新文件
‘‘‘
client.rename("/古明地觉/hello.txt", "/古明地觉/hello_satori.txt")
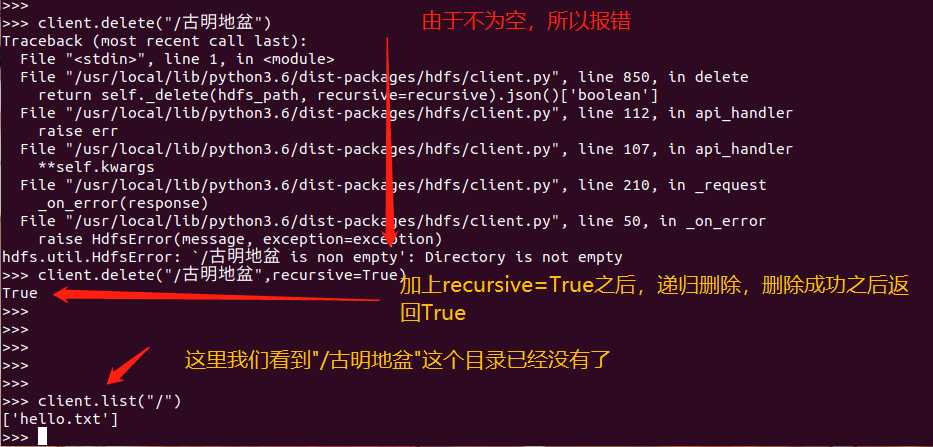
# 6.删除
‘‘‘
参数:
def delete(self, hdfs_path, recursive=False):
hdfs_path:路径
recursive:表示是否递归,默认为False
‘‘‘
client.delete("/古明地觉/hello_satori.txt", recursive=True)
# 7.上传文件
‘‘‘
参数:
def upload(self, hdfs_path, local_path, overwrite=False, n_threads=1,
temp_dir=None, chunk_size=2 ** 16, progress=None, cleanup=True, **kwargs):
hdfs_path:hdfs路径
local_path:本地文件路径,仔细一看这和hdfs dfs -put 本地 hdfs,刚好是相反的。表示从本地上传文件到hdfs
overwrite:就是遇见同名的,是否覆盖
n_threads:启动的线程数
temp_dir:当overwrite=true时,远程文件一旦存在,则会在上传完之后进行交换
chunk_size:文件上传的大小区间
progress:回调函数来跟踪进度,为每一chunk_size字节。它将传递两个参数,文件上传的路径和传输的字节数。一旦完成,-1将作为第二个参数
cleanup:如果在上传任何文件时发生错误,则删除该文件
‘‘‘
client.upload("/", "/home/satori/Desktop/diary")
# 8.下载文件
‘‘‘
参数:
def download(self, hdfs_path, local_path, overwrite=False, n_threads=1,
temp_dir=None, **kwargs):
hdfs_path:hdfs文件路径
local_path:本地文件路径,表示从hdfs下载文件到本地
‘‘‘
client.download("/hello.txt", "/home/satori/Desktop/hello.txt")




标签:iss ict 严格 hunk **kwargs clean .com rmi str
原文地址:https://www.cnblogs.com/traditional/p/9902160.html